
 阔海生
阔海生
 Gitee
3 months ago
Gitee
3 months ago
No known key found for this signature in database
GPG Key ID: 173E9B9CA92EEF8F
1 changed files with 80 additions and 0 deletions
Unified View
Diff Options
-
+80 -0FAQ.md
+ 80
- 0
FAQ.md
View File
| @@ -0,0 +1,80 @@ | |||||
| # GPUCodeForces FAQ | |||||
| # 2025/8/20 | |||||
| Q1:数据集主题是否太过宽泛?是否需要增加特定限制条件来帮助参赛者聚焦某一领域下研究? | |||||
| A1:不做限制,看重性能。 | |||||
| **经典计算密集型任务** _矩阵乘法(GEMM)_ | |||||
| _卷积(Convolution)_ | |||||
| _快速傅里叶变换(FFT)_ | |||||
| _排序(Sorting)_ | |||||
| _规约(Reduction)_ | |||||
| _扫描(Scan)_ | |||||
| **图像/视觉处理任务** _图像滤波(高斯模糊、边缘检测)_ | |||||
| _图像变形(Warping)_ | |||||
| _光流计算_ | |||||
| **新兴或特定领域任务** _MoE(Mixture of Experts)中的专家路由_ | |||||
| _稀疏矩阵运算_ | |||||
| _图神经网络中的聚合操作_ | |||||
| **深度学习常见算子** _LayerNorm / BatchNorm_ | |||||
| _Softmax / LogSoftmax_ | |||||
| _Attention 机制(Self-Attention, Cross-Attention)_ | |||||
| _激活函数(如 Swish, GELU)_ | |||||
| _损失函数(如 CrossEntropy)_ | |||||
| Q2:JSON文件的格式似乎没有明确规定?如下能有一个直观的输出例子会更好 | |||||
| A2:提交可运行目录即可,无需特定格式json。 | |||||
| ```plaintext | |||||
| { | |||||
| "task_name": "matrix_multiplication", | |||||
| "description": "...", | |||||
| "input_generator": "code snippet or function name", | |||||
| "gt_generator": "code snippet or function name", | |||||
| "metrics": ["time", "throughput", "bandwidth"], | |||||
| "prompt": "Optional prompt for LLM" | |||||
| } | |||||
| ``` | |||||
| Q3:建议补充错误处理和边界情况说明(比如输入为非方阵、极端大小等情况) | |||||
| A3:若前项评分相同,看加分项的评分。评测反馈交互在PR,需要跑通才有反馈。 | |||||
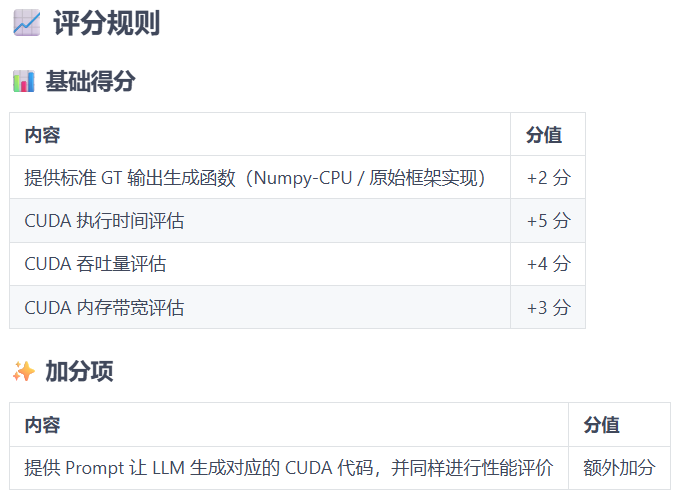
| Q4:评分规则这里明确了评估方面但没有给出具体数值范围,添加一个范围会不会更好?各方面评估是否增加分段会更好(执行时间评估-->0.1s +1分,0.01s+2分...-->最高+5分)? | |||||
| A4:核数量排名优先,同级再看评分。 | |||||
| Q5:提供prompt让LLM生成代码,如何确保【同样prompt每次都生成不同的代码】的不确定性带来的代码质量不稳定,从而引发的评分不稳定问题? | |||||
| A5:一般不会出现这种问题,评测相对稳定。 | |||||
| Q6:参赛者除了提交后能知道评分后,还能有其他方法能够更快地知道评分吗(本地评测模型、评分手册对照)? | |||||
| A6:评测本身速度就足够快,不用担心这个问题。 | |||||
|  | |||||
| # 改进的地方: | |||||
| 1. 核数量排名脚本 | |||||
| 2. 再出一版参赛说明,详情解释文档内各文件的作用 | |||||