
 WangYizhou
6 months ago
WangYizhou
6 months ago
commit
45915b2ba1
100 changed files with 582826 additions and 0 deletions
Unified View
Diff Options
-
+6 -0.idea/vcs.xml
-
+229 -0.idea/workspace.xml
-
+91483 -0Models+K-Means/data/SIR_dataset_processed.json
-
+9232 -0Models+K-Means/data/SIR_test_set.json
-
+73115 -0Models+K-Means/data/SIR_train_set.json
-
+9141 -0Models+K-Means/data/SIR_validation_set.json
-
+46 -0Models+K-Means/data/label_word_ids.json
-
+37 -0Models+K-Means/data/label_word_ids_CVSS2.json
-
+9742 -0Models+K-Means/dataset_more/test.csv
-
+63856 -0Models+K-Means/dataset_more/train.csv
-
+51 -0Models+K-Means/main/CVSSDataset.py
-
+38 -0Models+K-Means/main/CVSS_Calculator.py
-
+530 -0Models+K-Means/main/K-Means/K-Means_cluster.ipynb
-
+690 -0Models+K-Means/main/K-Means/KMeans+vectorString.ipynb
-
+7038 -0Models+K-Means/main/K-Means/PCA+KMeans_cluster.csv
-
+7038 -0Models+K-Means/main/K-Means/PCA+KMeans聚类.csv
-
BINModels+K-Means/main/K-Means/cluster.png
-
+17227 -0Models+K-Means/main/K-Means/cluster.svg
-
+5966 -0Models+K-Means/main/K-Means/cluster1.svg
-
+999 -0Models+K-Means/main/K-Means/hard.ipynb
-
BINModels+K-Means/main/K-Means/heatmap.png
-
+3387 -0Models+K-Means/main/K-Means/heatmap.svg
-
BINModels+K-Means/main/__pycache__/CVSSDataset.cpython-39.pyc
-
BINModels+K-Means/main/__pycache__/lemmatization.cpython-39.pyc
-
BINModels+K-Means/main/__pycache__/remove_stop_words.cpython-39.pyc
-
BINModels+K-Means/main/__pycache__/stemmatization.cpython-39.pyc
-
+687 -0Models+K-Means/main/csv_process.ipynb
-
+533 -0Models+K-Means/main/decisionTree/test_decisionTree.ipynb
-
+67 -0Models+K-Means/main/json2csv.py
-
+66 -0Models+K-Means/main/jsonToCsv.py
-
+56 -0Models+K-Means/main/lemmatization.py
-
BINModels+K-Means/main/output/cluster.png
-
BINModels+K-Means/main/output/heatmap.png
-
+0 -0Models+K-Means/main/output/output1.csv
-
+6331 -0Models+K-Means/main/output/output1_bert_nvd.csv
-
+6331 -0Models+K-Means/main/output/output1_distilbert_nvd.csv
-
+15962 -0Models+K-Means/main/output/output1_last.csv
-
+6331 -0Models+K-Means/main/output/output_albert.csv
-
+6331 -0Models+K-Means/main/output/roberta.csv
-
+20 -0Models+K-Means/main/remove_stop_words.py
-
BINModels+K-Means/main/requirements.txt
-
+20 -0Models+K-Means/main/stemmatization.py
-
+11 -0Models+K-Means/main/tagRemove.py
-
+291 -0Models+K-Means/main/test.py
-
+19 -0Models+K-Means/main/test.sh
-
+2 -0Models+K-Means/main/test_sh.py
-
+269 -0Models+K-Means/main/train.py
-
+14 -0Models+K-Means/main/train.sh
-
BINModels+K-Means/nltk_data/corpora/stopwords.zip
-
+32 -0Models+K-Means/nltk_data/corpora/stopwords/README
-
+754 -0Models+K-Means/nltk_data/corpora/stopwords/arabic
-
+165 -0Models+K-Means/nltk_data/corpora/stopwords/azerbaijani
-
+326 -0Models+K-Means/nltk_data/corpora/stopwords/basque
-
+398 -0Models+K-Means/nltk_data/corpora/stopwords/bengali
-
+278 -0Models+K-Means/nltk_data/corpora/stopwords/catalan
-
+841 -0Models+K-Means/nltk_data/corpora/stopwords/chinese
-
+94 -0Models+K-Means/nltk_data/corpora/stopwords/danish
-
+101 -0Models+K-Means/nltk_data/corpora/stopwords/dutch
-
+179 -0Models+K-Means/nltk_data/corpora/stopwords/english
-
+235 -0Models+K-Means/nltk_data/corpora/stopwords/finnish
-
+157 -0Models+K-Means/nltk_data/corpora/stopwords/french
-
+232 -0Models+K-Means/nltk_data/corpora/stopwords/german
-
+265 -0Models+K-Means/nltk_data/corpora/stopwords/greek
-
+221 -0Models+K-Means/nltk_data/corpora/stopwords/hebrew
-
+1036 -0Models+K-Means/nltk_data/corpora/stopwords/hinglish
-
+199 -0Models+K-Means/nltk_data/corpora/stopwords/hungarian
-
+758 -0Models+K-Means/nltk_data/corpora/stopwords/indonesian
-
+279 -0Models+K-Means/nltk_data/corpora/stopwords/italian
-
+380 -0Models+K-Means/nltk_data/corpora/stopwords/kazakh
-
+255 -0Models+K-Means/nltk_data/corpora/stopwords/nepali
-
+176 -0Models+K-Means/nltk_data/corpora/stopwords/norwegian
-
+207 -0Models+K-Means/nltk_data/corpora/stopwords/portuguese
-
+356 -0Models+K-Means/nltk_data/corpora/stopwords/romanian
-
+151 -0Models+K-Means/nltk_data/corpora/stopwords/russian
-
+1784 -0Models+K-Means/nltk_data/corpora/stopwords/slovene
-
+313 -0Models+K-Means/nltk_data/corpora/stopwords/spanish
-
+114 -0Models+K-Means/nltk_data/corpora/stopwords/swedish
-
+163 -0Models+K-Means/nltk_data/corpora/stopwords/tajik
-
+53 -0Models+K-Means/nltk_data/corpora/stopwords/turkish
-
BINModels+K-Means/nltk_data/tokenizers/punkt_tab.zip
-
+98 -0Models+K-Means/nltk_data/tokenizers/punkt_tab/README
-
+118 -0Models+K-Means/nltk_data/tokenizers/punkt_tab/czech/abbrev_types.txt
-
+96 -0Models+K-Means/nltk_data/tokenizers/punkt_tab/czech/collocations.tab
-
+52789 -0Models+K-Means/nltk_data/tokenizers/punkt_tab/czech/ortho_context.tab
-
+54 -0Models+K-Means/nltk_data/tokenizers/punkt_tab/czech/sent_starters.txt
-
+211 -0Models+K-Means/nltk_data/tokenizers/punkt_tab/danish/abbrev_types.txt
-
+101 -0Models+K-Means/nltk_data/tokenizers/punkt_tab/danish/collocations.tab
-
+53913 -0Models+K-Means/nltk_data/tokenizers/punkt_tab/danish/ortho_context.tab
-
+64 -0Models+K-Means/nltk_data/tokenizers/punkt_tab/danish/sent_starters.txt
-
+99 -0Models+K-Means/nltk_data/tokenizers/punkt_tab/dutch/abbrev_types.txt
-
+37 -0Models+K-Means/nltk_data/tokenizers/punkt_tab/dutch/collocations.tab
-
+32208 -0Models+K-Means/nltk_data/tokenizers/punkt_tab/dutch/ortho_context.tab
-
+54 -0Models+K-Means/nltk_data/tokenizers/punkt_tab/dutch/sent_starters.txt
-
+156 -0Models+K-Means/nltk_data/tokenizers/punkt_tab/english/abbrev_types.txt
-
+37 -0Models+K-Means/nltk_data/tokenizers/punkt_tab/english/collocations.tab
-
+20366 -0Models+K-Means/nltk_data/tokenizers/punkt_tab/english/ortho_context.tab
-
+39 -0Models+K-Means/nltk_data/tokenizers/punkt_tab/english/sent_starters.txt
-
+48 -0Models+K-Means/nltk_data/tokenizers/punkt_tab/estonian/abbrev_types.txt
-
+100 -0Models+K-Means/nltk_data/tokenizers/punkt_tab/estonian/collocations.tab
-
+68544 -0Models+K-Means/nltk_data/tokenizers/punkt_tab/estonian/ortho_context.tab
+ 6
- 0
.idea/vcs.xml
View File
| @@ -0,0 +1,6 @@ | |||||
| <?xml version="1.0" encoding="UTF-8"?> | |||||
| <project version="4"> | |||||
| <component name="VcsDirectoryMappings"> | |||||
| <mapping directory="$PROJECT_DIR$" vcs="Git" /> | |||||
| </component> | |||||
| </project> | |||||
+ 229
- 0
.idea/workspace.xml
View File
| @@ -0,0 +1,229 @@ | |||||
| <?xml version="1.0" encoding="UTF-8"?> | |||||
| <project version="4"> | |||||
| <component name="AutoImportSettings"> | |||||
| <option name="autoReloadType" value="SELECTIVE" /> | |||||
| </component> | |||||
| <component name="ChangeListManager"> | |||||
| <list default="true" id="7cb15b16-868b-48e5-9f8c-d95327a0b928" name="更改" comment="" /> | |||||
| <option name="SHOW_DIALOG" value="false" /> | |||||
| <option name="HIGHLIGHT_CONFLICTS" value="true" /> | |||||
| <option name="HIGHLIGHT_NON_ACTIVE_CHANGELIST" value="false" /> | |||||
| <option name="LAST_RESOLUTION" value="IGNORE" /> | |||||
| </component> | |||||
| <component name="FileTemplateManagerImpl"> | |||||
| <option name="RECENT_TEMPLATES"> | |||||
| <list> | |||||
| <option value="HTML File" /> | |||||
| <option value="Python Script" /> | |||||
| </list> | |||||
| </option> | |||||
| </component> | |||||
| <component name="Git.Settings"> | |||||
| <option name="RECENT_GIT_ROOT_PATH" value="$PROJECT_DIR$" /> | |||||
| </component> | |||||
| <component name="MarkdownSettingsMigration"> | |||||
| <option name="stateVersion" value="1" /> | |||||
| </component> | |||||
| <component name="ProjectColorInfo">{ | |||||
| "associatedIndex": 2 | |||||
| }</component> | |||||
| <component name="ProjectId" id="2wQLGPO7Ae3L3IOpkLnnyaEAHnt" /> | |||||
| <component name="ProjectLevelVcsManager" settingsEditedManually="true" /> | |||||
| <component name="ProjectViewState"> | |||||
| <option name="hideEmptyMiddlePackages" value="true" /> | |||||
| <option name="showLibraryContents" value="true" /> | |||||
| </component> | |||||
| <component name="PropertiesComponent">{ | |||||
| "keyToString": { | |||||
| "DefaultHtmlFileTemplate": "HTML File", | |||||
| "RunOnceActivity.OpenProjectViewOnStart": "true", | |||||
| "RunOnceActivity.ShowReadmeOnStart": "true", | |||||
| "WebServerToolWindowFactoryState": "false", | |||||
| "ignore.virus.scanning.warn.message": "true", | |||||
| "last_opened_file_path": "C:/Users/lw/Desktop/seeingData/static/img", | |||||
| "node.js.detected.package.eslint": "true", | |||||
| "node.js.detected.package.tslint": "true", | |||||
| "node.js.selected.package.eslint": "(autodetect)", | |||||
| "node.js.selected.package.tslint": "(autodetect)", | |||||
| "vue.rearranger.settings.migration": "true" | |||||
| } | |||||
| }</component> | |||||
| <component name="RecentsManager"> | |||||
| <key name="CopyFile.RECENT_KEYS"> | |||||
| <recent name="C:\Users\lw\Desktop\seeingData\static\img" /> | |||||
| <recent name="C:\Users\lw\Desktop\seeingData" /> | |||||
| <recent name="C:\Users\lw\Desktop\seeingData\static" /> | |||||
| <recent name="C:\Users\lw\Desktop\seeingData\templates" /> | |||||
| <recent name="C:\Users\lw\Desktop\seeingData\Data" /> | |||||
| </key> | |||||
| <key name="MoveFile.RECENT_KEYS"> | |||||
| <recent name="C:\Users\lw\Desktop\seeingData\static" /> | |||||
| </key> | |||||
| </component> | |||||
| <component name="RunManager" selected="Python.app"> | |||||
| <configuration name="main.html" type="JavascriptDebugType" temporary="true" nameIsGenerated="true" uri="http://localhost:63342/seeingData/templates/main.html" useBuiltInWebServerPort="true"> | |||||
| <method v="2" /> | |||||
| </configuration> | |||||
| <configuration name="app" type="PythonConfigurationType" factoryName="Python" temporary="true" nameIsGenerated="true"> | |||||
| <module name="seeingData" /> | |||||
| <option name="INTERPRETER_OPTIONS" value="" /> | |||||
| <option name="PARENT_ENVS" value="true" /> | |||||
| <envs> | |||||
| <env name="PYTHONUNBUFFERED" value="1" /> | |||||
| </envs> | |||||
| <option name="SDK_HOME" value="" /> | |||||
| <option name="WORKING_DIRECTORY" value="$PROJECT_DIR$" /> | |||||
| <option name="IS_MODULE_SDK" value="true" /> | |||||
| <option name="ADD_CONTENT_ROOTS" value="true" /> | |||||
| <option name="ADD_SOURCE_ROOTS" value="true" /> | |||||
| <EXTENSION ID="PythonCoverageRunConfigurationExtension" runner="coverage.py" /> | |||||
| <option name="SCRIPT_NAME" value="$PROJECT_DIR$/app.py" /> | |||||
| <option name="PARAMETERS" value="" /> | |||||
| <option name="SHOW_COMMAND_LINE" value="false" /> | |||||
| <option name="EMULATE_TERMINAL" value="false" /> | |||||
| <option name="MODULE_MODE" value="false" /> | |||||
| <option name="REDIRECT_INPUT" value="false" /> | |||||
| <option name="INPUT_FILE" value="" /> | |||||
| <method v="2" /> | |||||
| </configuration> | |||||
| <configuration name="cal (1)" type="PythonConfigurationType" factoryName="Python" temporary="true" nameIsGenerated="true"> | |||||
| <module name="seeingData" /> | |||||
| <option name="INTERPRETER_OPTIONS" value="" /> | |||||
| <option name="PARENT_ENVS" value="true" /> | |||||
| <envs> | |||||
| <env name="PYTHONUNBUFFERED" value="1" /> | |||||
| </envs> | |||||
| <option name="SDK_HOME" value="" /> | |||||
| <option name="WORKING_DIRECTORY" value="$PROJECT_DIR$/calculate" /> | |||||
| <option name="IS_MODULE_SDK" value="true" /> | |||||
| <option name="ADD_CONTENT_ROOTS" value="true" /> | |||||
| <option name="ADD_SOURCE_ROOTS" value="true" /> | |||||
| <EXTENSION ID="PythonCoverageRunConfigurationExtension" runner="coverage.py" /> | |||||
| <option name="SCRIPT_NAME" value="$PROJECT_DIR$/calculate/cal.py" /> | |||||
| <option name="PARAMETERS" value="" /> | |||||
| <option name="SHOW_COMMAND_LINE" value="false" /> | |||||
| <option name="EMULATE_TERMINAL" value="false" /> | |||||
| <option name="MODULE_MODE" value="false" /> | |||||
| <option name="REDIRECT_INPUT" value="false" /> | |||||
| <option name="INPUT_FILE" value="" /> | |||||
| <method v="2" /> | |||||
| </configuration> | |||||
| <configuration name="exploitabilityMSE" type="PythonConfigurationType" factoryName="Python" temporary="true" nameIsGenerated="true"> | |||||
| <module name="seeingData" /> | |||||
| <option name="INTERPRETER_OPTIONS" value="" /> | |||||
| <option name="PARENT_ENVS" value="true" /> | |||||
| <envs> | |||||
| <env name="PYTHONUNBUFFERED" value="1" /> | |||||
| </envs> | |||||
| <option name="SDK_HOME" value="" /> | |||||
| <option name="WORKING_DIRECTORY" value="$PROJECT_DIR$/calculate" /> | |||||
| <option name="IS_MODULE_SDK" value="true" /> | |||||
| <option name="ADD_CONTENT_ROOTS" value="true" /> | |||||
| <option name="ADD_SOURCE_ROOTS" value="true" /> | |||||
| <EXTENSION ID="PythonCoverageRunConfigurationExtension" runner="coverage.py" /> | |||||
| <option name="SCRIPT_NAME" value="$PROJECT_DIR$/calculate/exploitabilityMSE.py" /> | |||||
| <option name="PARAMETERS" value="" /> | |||||
| <option name="SHOW_COMMAND_LINE" value="false" /> | |||||
| <option name="EMULATE_TERMINAL" value="false" /> | |||||
| <option name="MODULE_MODE" value="false" /> | |||||
| <option name="REDIRECT_INPUT" value="false" /> | |||||
| <option name="INPUT_FILE" value="" /> | |||||
| <method v="2" /> | |||||
| </configuration> | |||||
| <configuration name="impactMse" type="PythonConfigurationType" factoryName="Python" temporary="true" nameIsGenerated="true"> | |||||
| <module name="seeingData" /> | |||||
| <option name="INTERPRETER_OPTIONS" value="" /> | |||||
| <option name="PARENT_ENVS" value="true" /> | |||||
| <envs> | |||||
| <env name="PYTHONUNBUFFERED" value="1" /> | |||||
| </envs> | |||||
| <option name="SDK_HOME" value="" /> | |||||
| <option name="WORKING_DIRECTORY" value="$PROJECT_DIR$/calculate" /> | |||||
| <option name="IS_MODULE_SDK" value="true" /> | |||||
| <option name="ADD_CONTENT_ROOTS" value="true" /> | |||||
| <option name="ADD_SOURCE_ROOTS" value="true" /> | |||||
| <EXTENSION ID="PythonCoverageRunConfigurationExtension" runner="coverage.py" /> | |||||
| <option name="SCRIPT_NAME" value="$PROJECT_DIR$/calculate/impactMse.py" /> | |||||
| <option name="PARAMETERS" value="" /> | |||||
| <option name="SHOW_COMMAND_LINE" value="false" /> | |||||
| <option name="EMULATE_TERMINAL" value="false" /> | |||||
| <option name="MODULE_MODE" value="false" /> | |||||
| <option name="REDIRECT_INPUT" value="false" /> | |||||
| <option name="INPUT_FILE" value="" /> | |||||
| <method v="2" /> | |||||
| </configuration> | |||||
| <configuration name="main" type="PythonConfigurationType" factoryName="Python" nameIsGenerated="true"> | |||||
| <module name="seeingData" /> | |||||
| <option name="INTERPRETER_OPTIONS" value="" /> | |||||
| <option name="PARENT_ENVS" value="true" /> | |||||
| <envs> | |||||
| <env name="PYTHONUNBUFFERED" value="1" /> | |||||
| </envs> | |||||
| <option name="SDK_HOME" value="" /> | |||||
| <option name="WORKING_DIRECTORY" value="$PROJECT_DIR$" /> | |||||
| <option name="IS_MODULE_SDK" value="true" /> | |||||
| <option name="ADD_CONTENT_ROOTS" value="true" /> | |||||
| <option name="ADD_SOURCE_ROOTS" value="true" /> | |||||
| <EXTENSION ID="PythonCoverageRunConfigurationExtension" runner="coverage.py" /> | |||||
| <option name="SCRIPT_NAME" value="$PROJECT_DIR$/main.py" /> | |||||
| <option name="PARAMETERS" value="" /> | |||||
| <option name="SHOW_COMMAND_LINE" value="false" /> | |||||
| <option name="EMULATE_TERMINAL" value="false" /> | |||||
| <option name="MODULE_MODE" value="false" /> | |||||
| <option name="REDIRECT_INPUT" value="false" /> | |||||
| <option name="INPUT_FILE" value="" /> | |||||
| <method v="2" /> | |||||
| </configuration> | |||||
| <recent_temporary> | |||||
| <list> | |||||
| <item itemvalue="Python.app" /> | |||||
| <item itemvalue="JavaScript 调试.main.html" /> | |||||
| <item itemvalue="Python.cal (1)" /> | |||||
| <item itemvalue="Python.impactMse" /> | |||||
| <item itemvalue="Python.exploitabilityMSE" /> | |||||
| </list> | |||||
| </recent_temporary> | |||||
| </component> | |||||
| <component name="SpellCheckerSettings" RuntimeDictionaries="0" Folders="0" CustomDictionaries="0" DefaultDictionary="应用程序级" UseSingleDictionary="true" transferred="true" /> | |||||
| <component name="TaskManager"> | |||||
| <task active="true" id="Default" summary="默认任务"> | |||||
| <changelist id="7cb15b16-868b-48e5-9f8c-d95327a0b928" name="更改" comment="" /> | |||||
| <created>1745968754647</created> | |||||
| <option name="number" value="Default" /> | |||||
| <option name="presentableId" value="Default" /> | |||||
| <updated>1745968754647</updated> | |||||
| <workItem from="1745968756808" duration="1718000" /> | |||||
| <workItem from="1746000490114" duration="1219000" /> | |||||
| <workItem from="1746001738667" duration="2829000" /> | |||||
| <workItem from="1746004674142" duration="14725000" /> | |||||
| <workItem from="1746060084499" duration="29737000" /> | |||||
| <workItem from="1746112547099" duration="661000" /> | |||||
| <workItem from="1746113230998" duration="18000" /> | |||||
| <workItem from="1746113446889" duration="943000" /> | |||||
| <workItem from="1746114706813" duration="101000" /> | |||||
| <workItem from="1746126263703" duration="720000" /> | |||||
| <workItem from="1746127669568" duration="1287000" /> | |||||
| <workItem from="1746445549616" duration="1180000" /> | |||||
| <workItem from="1746448252115" duration="616000" /> | |||||
| <workItem from="1746457783724" duration="5000" /> | |||||
| <workItem from="1746460056528" duration="148000" /> | |||||
| <workItem from="1746460254314" duration="24000" /> | |||||
| <workItem from="1746631090475" duration="142000" /> | |||||
| <workItem from="1747312456214" duration="701000" /> | |||||
| </task> | |||||
| <servers /> | |||||
| </component> | |||||
| <component name="TypeScriptGeneratedFilesManager"> | |||||
| <option name="version" value="3" /> | |||||
| </component> | |||||
| <component name="com.intellij.coverage.CoverageDataManagerImpl"> | |||||
| <SUITE FILE_PATH="coverage/seeingData$exploitabilityMSE.coverage" NAME="exploitabilityMSE 覆盖结果" MODIFIED="1746109799847" SOURCE_PROVIDER="com.intellij.coverage.DefaultCoverageFileProvider" RUNNER="coverage.py" COVERAGE_BY_TEST_ENABLED="true" COVERAGE_TRACING_ENABLED="false" WORKING_DIRECTORY="$PROJECT_DIR$/calculate" /> | |||||
| <SUITE FILE_PATH="coverage/seeingData$calbase.coverage" NAME="calbase 覆盖结果" MODIFIED="1746108928046" SOURCE_PROVIDER="com.intellij.coverage.DefaultCoverageFileProvider" RUNNER="coverage.py" COVERAGE_BY_TEST_ENABLED="true" COVERAGE_TRACING_ENABLED="false" WORKING_DIRECTORY="$PROJECT_DIR$/calculate" /> | |||||
| <SUITE FILE_PATH="coverage/seeingData$cal__1_.coverage" NAME="cal (1) 覆盖结果" MODIFIED="1746110303519" SOURCE_PROVIDER="com.intellij.coverage.DefaultCoverageFileProvider" RUNNER="coverage.py" COVERAGE_BY_TEST_ENABLED="true" COVERAGE_TRACING_ENABLED="false" WORKING_DIRECTORY="$PROJECT_DIR$/calculate" /> | |||||
| <SUITE FILE_PATH="coverage/seeingData$main.coverage" NAME="main 覆盖结果" MODIFIED="1745968761559" SOURCE_PROVIDER="com.intellij.coverage.DefaultCoverageFileProvider" RUNNER="coverage.py" COVERAGE_BY_TEST_ENABLED="true" COVERAGE_TRACING_ENABLED="false" WORKING_DIRECTORY="$PROJECT_DIR$" /> | |||||
| <SUITE FILE_PATH="coverage/seeingData$impactMse.coverage" NAME="impactMse 覆盖结果" MODIFIED="1746110275202" SOURCE_PROVIDER="com.intellij.coverage.DefaultCoverageFileProvider" RUNNER="coverage.py" COVERAGE_BY_TEST_ENABLED="true" COVERAGE_TRACING_ENABLED="false" WORKING_DIRECTORY="$PROJECT_DIR$/calculate" /> | |||||
| <SUITE FILE_PATH="coverage/seeingData$accurate.coverage" NAME="accurate 覆盖结果" MODIFIED="1746020524862" SOURCE_PROVIDER="com.intellij.coverage.DefaultCoverageFileProvider" RUNNER="coverage.py" COVERAGE_BY_TEST_ENABLED="true" COVERAGE_TRACING_ENABLED="false" WORKING_DIRECTORY="$PROJECT_DIR$/calculate" /> | |||||
| <SUITE FILE_PATH="coverage/seeingData$baseMse.coverage" NAME="baseMse 覆盖结果" MODIFIED="1746108872502" SOURCE_PROVIDER="com.intellij.coverage.DefaultCoverageFileProvider" RUNNER="coverage.py" COVERAGE_BY_TEST_ENABLED="true" COVERAGE_TRACING_ENABLED="false" WORKING_DIRECTORY="$PROJECT_DIR$/calculate" /> | |||||
| <SUITE FILE_PATH="coverage/seeingData$app.coverage" NAME="app 覆盖结果" MODIFIED="1746631107684" SOURCE_PROVIDER="com.intellij.coverage.DefaultCoverageFileProvider" RUNNER="coverage.py" COVERAGE_BY_TEST_ENABLED="true" COVERAGE_TRACING_ENABLED="false" WORKING_DIRECTORY="$PROJECT_DIR$" /> | |||||
| </component> | |||||
| </project> | |||||
+ 91483
- 0
Models+K-Means/data/SIR_dataset_processed.json
File diff suppressed because it is too large
View File
+ 9232
- 0
Models+K-Means/data/SIR_test_set.json
File diff suppressed because it is too large
View File
+ 73115
- 0
Models+K-Means/data/SIR_train_set.json
File diff suppressed because it is too large
View File
+ 9141
- 0
Models+K-Means/data/SIR_validation_set.json
File diff suppressed because it is too large
View File
+ 46
- 0
Models+K-Means/data/label_word_ids.json
View File
| @@ -0,0 +1,46 @@ | |||||
| { | |||||
| "AV": { | |||||
| "network": 2897, | |||||
| "adjacent": 5516, | |||||
| "local": 2334, | |||||
| "physical": 3558 | |||||
| }, | |||||
| "AC": { | |||||
| "low": 2659, | |||||
| "high": 2152 | |||||
| }, | |||||
| "PR": { | |||||
| "none": 3904, | |||||
| "low": 2659, | |||||
| "high": 2152 | |||||
| }, | |||||
| "UI": { | |||||
| "none": 3904, | |||||
| "required": 3223 | |||||
| }, | |||||
| "S": { | |||||
| "unchanged": 15704, | |||||
| "changed": 2904 | |||||
| }, | |||||
| "C": { | |||||
| "none": 3904, | |||||
| "low": 2659, | |||||
| "high": 2152 | |||||
| }, | |||||
| "I": { | |||||
| "none": 3904, | |||||
| "low": 2659, | |||||
| "high": 2152 | |||||
| }, | |||||
| "A": { | |||||
| "none": 3904, | |||||
| "low": 2659, | |||||
| "high": 2152 | |||||
| }, | |||||
| "severity": { | |||||
| "low": 2659, | |||||
| "medium": 5396, | |||||
| "high": 2152, | |||||
| "critical": 4187 | |||||
| } | |||||
| } | |||||
+ 37
- 0
Models+K-Means/data/label_word_ids_CVSS2.json
View File
| @@ -0,0 +1,37 @@ | |||||
| { | |||||
| "AV": { | |||||
| "network": 2897, | |||||
| "adjacent": 5516, | |||||
| "local": 2334 | |||||
| }, | |||||
| "AC": { | |||||
| "low": 2659, | |||||
| "medium": 5396, | |||||
| "high": 2152 | |||||
| }, | |||||
| "Au": { | |||||
| "none": 3904, | |||||
| "single": 2309, | |||||
| "multiple": 3674 | |||||
| }, | |||||
| "C": { | |||||
| "none": 3904, | |||||
| "partial": 7704, | |||||
| "complete": 3143 | |||||
| }, | |||||
| "I": { | |||||
| "none": 3904, | |||||
| "partial": 7704, | |||||
| "complete": 3143 | |||||
| }, | |||||
| "A": { | |||||
| "none": 3904, | |||||
| "partial": 7704, | |||||
| "complete": 3143 | |||||
| }, | |||||
| "severity": { | |||||
| "low": 2659, | |||||
| "medium": 5396, | |||||
| "high": 2152 | |||||
| } | |||||
| } | |||||
+ 9742
- 0
Models+K-Means/dataset_more/test.csv
File diff suppressed because it is too large
View File
+ 63856
- 0
Models+K-Means/dataset_more/train.csv
File diff suppressed because it is too large
View File
+ 51
- 0
Models+K-Means/main/CVSSDataset.py
View File
| @@ -0,0 +1,51 @@ | |||||
| from pathlib import Path | |||||
| from sklearn.model_selection import train_test_split | |||||
| import torch | |||||
| import csv | |||||
| class CVSSDataset(torch.utils.data.Dataset): | |||||
| def __init__(self, encodings, labels): | |||||
| self.encodings = encodings | |||||
| self.labels = labels | |||||
| def __getitem__(self, idx): | |||||
| item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()} | |||||
| item['labels'] = torch.tensor(self.labels[idx]) | |||||
| return item | |||||
| def __len__(self): | |||||
| return len(self.labels) | |||||
| def read_cvss_txt(split_dir, list_classes): | |||||
| split_dir = Path(split_dir) | |||||
| texts = [] | |||||
| labels = [] | |||||
| for label_dir in ["LOW", "HIGH"]: | |||||
| for text_file in (split_dir/label_dir).iterdir(): | |||||
| texts.append(text_file.read_text()) | |||||
| for i in range(len(list_classes)): | |||||
| if list_classes[i] == label_dir: | |||||
| labels.append(i) | |||||
| else: | |||||
| continue | |||||
| return texts, labels | |||||
| def read_cvss_csv(file_name, num_label, list_classes): | |||||
| texts = [] | |||||
| labels = [] | |||||
| csv_file = open(file_name, 'r+',encoding='UTF-8') | |||||
| csv_reader = csv.reader(csv_file, delimiter=',', quotechar='"') | |||||
| for row in csv_reader: | |||||
| texts.append(row[0]) | |||||
| for i in range(len(list_classes)): | |||||
| if list_classes[i] == row[num_label]: | |||||
| labels.append(i) | |||||
| else: | |||||
| continue | |||||
| csv_file.close() | |||||
| return texts, labels | |||||
+ 38
- 0
Models+K-Means/main/CVSS_Calculator.py
View File
| @@ -0,0 +1,38 @@ | |||||
| import math | |||||
| from cvss import CVSS2 | |||||
| from cvss import CVSS3 | |||||
| from cvss import CVSS4 | |||||
| import re | |||||
| import pandas as pd | |||||
| import numpy as np | |||||
| data1 = pd.DataFrame(pd.read_json(r"E:\pythonProject_open\data\SIR_dataset_processed.json")) | |||||
| vecStr = data1["vectorString"] | |||||
| impactScores = data1["impactScore"] | |||||
| exploitabilityScores = data1["exploitabilityScore"] | |||||
| print("----") | |||||
| for i, j, k in zip(vecStr, impactScores, exploitabilityScores) : | |||||
| cvssVer = re.findall(':(.*?)/', i) | |||||
| impactScore = float(j) | |||||
| exploitabilityScore = float(k) | |||||
| if float(cvssVer[0]) == 2: | |||||
| cvss = CVSS2(i) | |||||
| elif 2 <= float(cvssVer[0]) < 4: | |||||
| cvss = CVSS3(i) | |||||
| else: | |||||
| cvss = CVSS4(i) | |||||
| cvss_baseScore = cvss.base_score | |||||
| print(cvss_baseScore) | |||||
| if impactScore <= 0: | |||||
| cvss_baseScore = 0 | |||||
| elif 0 < impactScore + exploitabilityScore < 10: | |||||
| cvss_baseScore = math.ceil((impactScore + exploitabilityScore) * 10) / 10 | |||||
| else: | |||||
| cvss_baseScore = 10 | |||||
| print(f"baseScore:{cvss_baseScore}, impactScore:{impactScore}, exploitabilityScore:{exploitabilityScore}") | |||||
+ 530
- 0
Models+K-Means/main/K-Means/K-Means_cluster.ipynb
File diff suppressed because it is too large
View File
+ 690
- 0
Models+K-Means/main/K-Means/KMeans+vectorString.ipynb
File diff suppressed because it is too large
View File
+ 7038
- 0
Models+K-Means/main/K-Means/PCA+KMeans_cluster.csv
File diff suppressed because it is too large
View File
+ 7038
- 0
Models+K-Means/main/K-Means/PCA+KMeans聚类.csv
File diff suppressed because it is too large
View File
BIN
Models+K-Means/main/K-Means/cluster.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 640 | Height: 480 | Size: 27 kB |
+ 17227
- 0
Models+K-Means/main/K-Means/cluster.svg
File diff suppressed because it is too large
View File
{kind=link}
+ 5966
- 0
Models+K-Means/main/K-Means/cluster1.svg
File diff suppressed because it is too large
View File
{kind=link}
+ 999
- 0
Models+K-Means/main/K-Means/hard.ipynb
File diff suppressed because it is too large
View File
BIN
Models+K-Means/main/K-Means/heatmap.png
View File
{kind=link}
| Before | After |
|---|---|
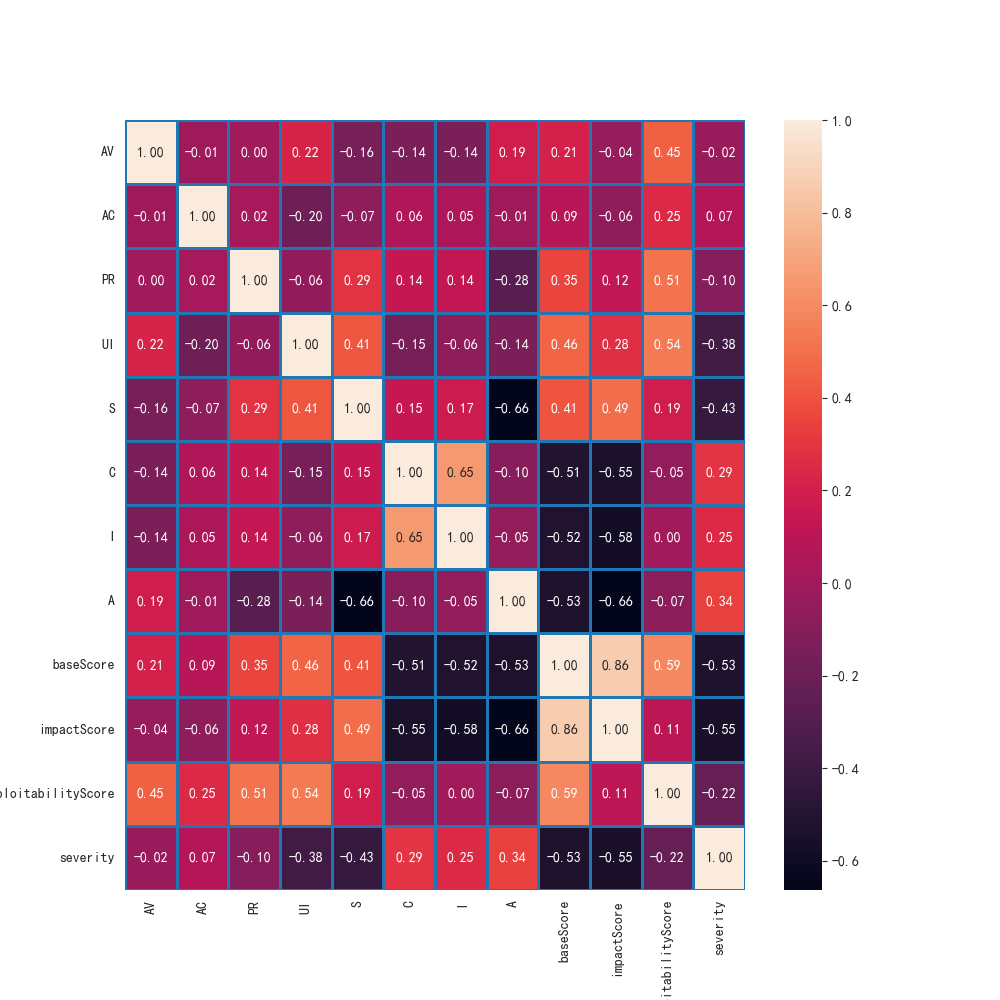
|
|
| Width: 1000 | Height: 1000 | Size: 112 kB |
+ 3387
- 0
Models+K-Means/main/K-Means/heatmap.svg
File diff suppressed because it is too large
View File
{kind=link}
BIN
Models+K-Means/main/__pycache__/CVSSDataset.cpython-39.pyc
View File
BIN
Models+K-Means/main/__pycache__/lemmatization.cpython-39.pyc
View File
BIN
Models+K-Means/main/__pycache__/remove_stop_words.cpython-39.pyc
View File
BIN
Models+K-Means/main/__pycache__/stemmatization.cpython-39.pyc
View File
+ 687
- 0
Models+K-Means/main/csv_process.ipynb
View File
| @@ -0,0 +1,687 @@ | |||||
| { | |||||
| "cells": [ | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 1, | |||||
| "id": "676be61a-bd65-4510-8357-94859f596330", | |||||
| "metadata": {}, | |||||
| "outputs": [], | |||||
| "source": [ | |||||
| "import pandas as pd\n", | |||||
| "import json" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 2, | |||||
| "id": "94f312ae-87d2-4d5e-ae75-9fc85a2a980c", | |||||
| "metadata": {}, | |||||
| "outputs": [], | |||||
| "source": [ | |||||
| "data = pd.read_json('../data/SIR_test_set.json')" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 3, | |||||
| "id": "7d949b04-4929-4921-a818-4e8cbb57826b", | |||||
| "metadata": {}, | |||||
| "outputs": [ | |||||
| { | |||||
| "name": "stdout", | |||||
| "output_type": "stream", | |||||
| "text": [ | |||||
| " CVE_ID Issue_Url_old \\\n", | |||||
| "0 CVE-2021-45822 https://github.com/btiteam/xbtit-3.1/issues/7 \n", | |||||
| "1 CVE-2021-45769 https://github.com/mz-automation/libiec61850/i... \n", | |||||
| "2 CVE-2021-45773 https://github.com/mz-automation/lib60870/issu... \n", | |||||
| "3 CVE-2022-25014 https://github.com/gamonoid/icehrm/issues/283 \n", | |||||
| "4 CVE-2022-25013 https://github.com/gamonoid/icehrm/issues/284 \n", | |||||
| ".. ... ... \n", | |||||
| "705 CVE-2022-32417 https://github.com/Snakinya/Vuln/issues/1 \n", | |||||
| "706 CVE-2021-34485 https://github.com/github/advisory-database/is... \n", | |||||
| "707 CVE-2021-44906 https://github.com/minimistjs/minimist/issues/11 \n", | |||||
| "708 CVE-2020-8927 https://github.com/github/advisory-database/is... \n", | |||||
| "709 CVE-2021-31402 https://github.com/cfug/dio/issues/1752 \n", | |||||
| "\n", | |||||
| " Issue_Url_new \\\n", | |||||
| "0 https://github.com/btiteam/xbtit-3.1/issues/7 \n", | |||||
| "1 https://github.com/mz-automation/libiec61850/i... \n", | |||||
| "2 https://github.com/mz-automation/lib60870/issu... \n", | |||||
| "3 https://github.com/gamonoid/icehrm/issues/283 \n", | |||||
| "4 https://github.com/gamonoid/icehrm/issues/284 \n", | |||||
| ".. ... \n", | |||||
| "705 https://github.com/snakinya/vuln/issues/1 \n", | |||||
| "706 https://github.com/github/advisory-database/is... \n", | |||||
| "707 https://github.com/minimistjs/minimist/issues/11 \n", | |||||
| "708 https://github.com/github/advisory-database/is... \n", | |||||
| "709 https://github.com/cfug/dio/issues/1752 \n", | |||||
| "\n", | |||||
| " Repo_new Issue_Created_At \\\n", | |||||
| "0 btiteam/xbtit-3.1 2021-12-22 20:25:58+00:00 \n", | |||||
| "1 mz-automation/libiec61850 2021-12-23 00:53:55+00:00 \n", | |||||
| "2 mz-automation/lib60870 2021-12-23 06:01:26+00:00 \n", | |||||
| "3 gamonoid/icehrm 2021-12-23 08:09:18+00:00 \n", | |||||
| "4 gamonoid/icehrm 2021-12-23 08:13:20+00:00 \n", | |||||
| ".. ... ... \n", | |||||
| "705 Snakinya/Vuln 2022-08-04 10:38:48+00:00 \n", | |||||
| "706 github/advisory-database 2022-10-12 20:44:32+00:00 \n", | |||||
| "707 minimistjs/minimist 2022-10-19 14:23:14+00:00 \n", | |||||
| "708 github/advisory-database 2022-10-31 20:04:11+00:00 \n", | |||||
| "709 cfug/dio 2023-03-21 16:54:52+00:00 \n", | |||||
| "\n", | |||||
| " description \\\n", | |||||
| "0 Stored & Reflected XSS affecting Xbtit NUMBERT... \n", | |||||
| "1 NULL Pointer Dereference in APITAG NULL Pointe... \n", | |||||
| "2 NULL Pointer Dereference in APITAG NULL Pointe... \n", | |||||
| "3 Reflected XSS vulnerability NUMBERTAG in icehr... \n", | |||||
| "4 Reflected XSS vulnerabilities NUMBERTAG in ice... \n", | |||||
| ".. ... \n", | |||||
| "705 pboot cms NUMBERTAG RCE. 漏洞详情: URLTAG 声明 APITA... \n", | |||||
| "706 .NET CVE backfill round NUMBERTAG Hello, Pleas... \n", | |||||
| "707 Backport of NUMBERTAG fixes to NUMBERTAG Thank... \n", | |||||
| "708 Update impacted packages for CVETAG . Hi, This... \n", | |||||
| "709 CVE Dio NUMBERTAG Google OVS Scanner. Package ... \n", | |||||
| "\n", | |||||
| " vectorString severity baseScore \\\n", | |||||
| "0 CVSS:3.1/AV:N/AC:L/PR:N/UI:R/S:C/C:L/I:L/A:N MEDIUM 6.1 \n", | |||||
| "1 CVSS:3.1/AV:N/AC:L/PR:N/UI:N/S:U/C:N/I:N/A:H HIGH 7.5 \n", | |||||
| "2 CVSS:3.1/AV:N/AC:L/PR:N/UI:N/S:U/C:N/I:N/A:H HIGH 7.5 \n", | |||||
| "3 CVSS:3.1/AV:N/AC:L/PR:N/UI:R/S:C/C:L/I:L/A:N MEDIUM 6.1 \n", | |||||
| "4 CVSS:3.1/AV:N/AC:L/PR:N/UI:R/S:C/C:L/I:L/A:N MEDIUM 6.1 \n", | |||||
| ".. ... ... ... \n", | |||||
| "705 CVSS:3.1/AV:N/AC:L/PR:N/UI:N/S:U/C:H/I:H/A:H CRITICAL 9.8 \n", | |||||
| "706 CVSS:3.1/AV:L/AC:L/PR:L/UI:N/S:U/C:H/I:N/A:N MEDIUM 5.5 \n", | |||||
| "707 CVSS:3.1/AV:N/AC:L/PR:N/UI:N/S:U/C:H/I:H/A:H CRITICAL 9.8 \n", | |||||
| "708 CVSS:3.1/AV:N/AC:L/PR:N/UI:N/S:U/C:N/I:L/A:L MEDIUM 6.5 \n", | |||||
| "709 CVSS:3.1/AV:N/AC:L/PR:N/UI:N/S:U/C:H/I:N/A:N HIGH 7.5 \n", | |||||
| "\n", | |||||
| " impactScore exploitabilityScore \n", | |||||
| "0 2.7 2.8 \n", | |||||
| "1 3.6 3.9 \n", | |||||
| "2 3.6 3.9 \n", | |||||
| "3 2.7 2.8 \n", | |||||
| "4 2.7 2.8 \n", | |||||
| ".. ... ... \n", | |||||
| "705 5.9 3.9 \n", | |||||
| "706 3.6 1.8 \n", | |||||
| "707 5.9 3.9 \n", | |||||
| "708 2.5 3.9 \n", | |||||
| "709 3.6 3.9 \n", | |||||
| "\n", | |||||
| "[710 rows x 11 columns]\n" | |||||
| ] | |||||
| } | |||||
| ], | |||||
| "source": [ | |||||
| "train_data_temp = pd.DataFrame()\n", | |||||
| "print(data)" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 4, | |||||
| "id": "d4272d23-2c40-416a-aa83-40b09817ea0a", | |||||
| "metadata": {}, | |||||
| "outputs": [], | |||||
| "source": [ | |||||
| "train_data_temp['description'] = data['description']" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 5, | |||||
| "id": "101f87d6-38d7-4562-a572-49ab74eec58d", | |||||
| "metadata": {}, | |||||
| "outputs": [ | |||||
| { | |||||
| "name": "stdout", | |||||
| "output_type": "stream", | |||||
| "text": [ | |||||
| "0 False\n", | |||||
| "1 False\n", | |||||
| "2 False\n", | |||||
| "3 False\n", | |||||
| "4 False\n", | |||||
| " ... \n", | |||||
| "705 False\n", | |||||
| "706 False\n", | |||||
| "707 False\n", | |||||
| "708 False\n", | |||||
| "709 False\n", | |||||
| "Name: description, Length: 710, dtype: bool\n" | |||||
| ] | |||||
| } | |||||
| ], | |||||
| "source": [ | |||||
| "print(train_data_temp['description'].isna())" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 6, | |||||
| "id": "85b0cd35-3862-43fb-b4ab-d88c0ceae6da", | |||||
| "metadata": {}, | |||||
| "outputs": [ | |||||
| { | |||||
| "name": "stdout", | |||||
| "output_type": "stream", | |||||
| "text": [ | |||||
| "Empty DataFrame\n", | |||||
| "Columns: [description]\n", | |||||
| "Index: []\n" | |||||
| ] | |||||
| } | |||||
| ], | |||||
| "source": [ | |||||
| "# 获取 NaN 值的行索引\n", | |||||
| "nan_rows = train_data_temp[train_data_temp['description'].isna()]\n", | |||||
| "print(nan_rows)" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 7, | |||||
| "id": "8eaf202e-b96b-4f79-8b3b-89e4757add04", | |||||
| "metadata": {}, | |||||
| "outputs": [], | |||||
| "source": [ | |||||
| "vectorString = data['vectorString']" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 8, | |||||
| "id": "49331613-93f9-4d86-9e43-384c16ff8813", | |||||
| "metadata": {}, | |||||
| "outputs": [ | |||||
| { | |||||
| "name": "stdout", | |||||
| "output_type": "stream", | |||||
| "text": [ | |||||
| " AV AC PR UI S C I A\n", | |||||
| "0 N L N R C L L N\n", | |||||
| "1 N L N N U N N H\n", | |||||
| "2 N L N N U N N H\n", | |||||
| "3 N L N R C L L N\n", | |||||
| "4 N L N R C L L N\n", | |||||
| ".. .. .. .. .. .. .. .. ..\n", | |||||
| "705 N L N N U H H H\n", | |||||
| "706 L L L N U H N N\n", | |||||
| "707 N L N N U H H H\n", | |||||
| "708 N L N N U N L L\n", | |||||
| "709 N L N N U H N N\n", | |||||
| "\n", | |||||
| "[710 rows x 8 columns]\n" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "name": "stderr", | |||||
| "output_type": "stream", | |||||
| "text": [ | |||||
| "C:\\Users\\lx\\AppData\\Local\\Temp\\ipykernel_38864\\3052899741.py:14: FutureWarning: DataFrame.applymap has been deprecated. Use DataFrame.map instead.\n", | |||||
| " train_data = train_data.applymap(transform_value)\n" | |||||
| ] | |||||
| } | |||||
| ], | |||||
| "source": [ | |||||
| "#转换数据\n", | |||||
| "def transform_value(val):\n", | |||||
| " return val.split(':')[1]\n", | |||||
| " \n", | |||||
| "columns = ['AV', 'AC', 'PR', 'UI', 'S', 'C', 'I', 'A']\n", | |||||
| "\n", | |||||
| "temp = []\n", | |||||
| "\n", | |||||
| "for i in range(vectorString.size):\n", | |||||
| " part = vectorString[i].split('/')\n", | |||||
| " list_items = part[1::]\n", | |||||
| " temp.append(list_items)\n", | |||||
| "train_data = pd.DataFrame(temp, columns=columns)\n", | |||||
| "train_data = train_data.applymap(transform_value)\n", | |||||
| "print(train_data)" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 9, | |||||
| "id": "79a6f3ee-0517-4a4f-b26a-6f2dabf9d3b0", | |||||
| "metadata": {}, | |||||
| "outputs": [], | |||||
| "source": [ | |||||
| "def calculate_cvss_score(params):\n", | |||||
| " # 字典映射分值\n", | |||||
| " AV = {'N': 0.85, 'A': 0.62, 'L': 0.55, 'P': 0.2}\n", | |||||
| " AC = {'L': 0.77, 'H': 0.44}\n", | |||||
| " PR = {'N': 0.85, 'L': 0.68, 'H': 0.5}\n", | |||||
| " UI = {'N': 0.85, 'R': 0.62}\n", | |||||
| " S = {'U': 1, 'C': 1.08}\n", | |||||
| " C = {'N': 0, 'L': 0.22, 'H': 0.56}\n", | |||||
| " I = {'N': 0, 'L': 0.22, 'H': 0.56}\n", | |||||
| " A = {'N': 0, 'L': 0.22, 'H': 0.56}\n", | |||||
| "\n", | |||||
| " # 获取参数值\n", | |||||
| " av = AV[params['AV']]\n", | |||||
| " ac = AC[params['AC']]\n", | |||||
| " pr = PR[params['PR']]\n", | |||||
| " ui = UI[params['UI']]\n", | |||||
| " s = S[params['S']]\n", | |||||
| " c = C[params['C']]\n", | |||||
| " i = I[params['I']]\n", | |||||
| " a = A[params['A']]\n", | |||||
| "\n", | |||||
| " # 计算临时分数\n", | |||||
| " impact = 1 - (1 - c) * (1 - i) * (1 - a)\n", | |||||
| " exploitability = 8.22 * av * ac * pr * ui\n", | |||||
| "\n", | |||||
| " if impact == 0:\n", | |||||
| " base_score = 0\n", | |||||
| " else:\n", | |||||
| " if s == 1: # 未改变\n", | |||||
| " base_score = round(min(1.176 * (exploitability + impact), 10), 1)\n", | |||||
| " else: # 改变\n", | |||||
| " base_score = round(min(1.08 * (exploitability + impact), 10), 1)\n", | |||||
| "\n", | |||||
| " return base_score" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 10, | |||||
| "id": "622cf1dd-082c-4d2a-a880-34d22e96d053", | |||||
| "metadata": {}, | |||||
| "outputs": [ | |||||
| { | |||||
| "name": "stdout", | |||||
| "output_type": "stream", | |||||
| "text": [ | |||||
| " AV AC PR UI S C I A score\n", | |||||
| "0 N L N R C L L N 3.5\n", | |||||
| "1 N L N N U N N H 5.2\n", | |||||
| "2 N L N N U N N H 5.2\n", | |||||
| "3 N L N R C L L N 3.5\n", | |||||
| "4 N L N R C L L N 3.5\n", | |||||
| ".. .. .. .. .. .. .. .. .. ...\n", | |||||
| "705 N L N N U H H H 5.6\n", | |||||
| "706 L L L N U H N N 3.0\n", | |||||
| "707 N L N N U H H H 5.6\n", | |||||
| "708 N L N N U N L L 5.0\n", | |||||
| "709 N L N N U H N N 5.2\n", | |||||
| "\n", | |||||
| "[710 rows x 9 columns]\n" | |||||
| ] | |||||
| } | |||||
| ], | |||||
| "source": [ | |||||
| "# 为每一行创建字典\n", | |||||
| "train_dicts = train_data.apply(lambda row: {col: row[col][0] for col in train_data.columns}, axis=1)\n", | |||||
| "train_score = train_dicts.apply(calculate_cvss_score)\n", | |||||
| "train_data['score'] = train_score\n", | |||||
| "print(train_data)" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 11, | |||||
| "id": "f767e3c9-634b-4c0d-9145-eb4c013e1a6e", | |||||
| "metadata": {}, | |||||
| "outputs": [], | |||||
| "source": [ | |||||
| "dict = {\n", | |||||
| " 'AV': {\n", | |||||
| " 'N': 'NETWORK',\n", | |||||
| " 'A': 'ADJACENT',\n", | |||||
| " 'L': 'LOCAL',\n", | |||||
| " 'P': 'PHYSICAL'\n", | |||||
| " },\n", | |||||
| " 'AC': {\n", | |||||
| " 'L': 'LOW',\n", | |||||
| " 'H': 'HIGH'\n", | |||||
| " }, \n", | |||||
| " 'PR': {\n", | |||||
| " 'N': 'NONE',\n", | |||||
| " 'L': 'LOW',\n", | |||||
| " 'H': 'HIGH'\n", | |||||
| " }, \n", | |||||
| " 'UI': {\n", | |||||
| " 'N': 'NONE',\n", | |||||
| " 'R': 'REQUIRED'\n", | |||||
| " },\n", | |||||
| " 'S': {\n", | |||||
| " 'U': 'UNCHANGED',\n", | |||||
| " 'C': 'CHANGED'\n", | |||||
| " },\n", | |||||
| " 'C': {\n", | |||||
| " 'N': 'NONE',\n", | |||||
| " 'L': 'LOW',\n", | |||||
| " 'H': 'HIGH'\n", | |||||
| " },\n", | |||||
| " 'I': {\n", | |||||
| " 'N': 'NONE',\n", | |||||
| " 'L': 'LOW',\n", | |||||
| " 'H': 'HIGH'\n", | |||||
| " },\n", | |||||
| " 'A': {\n", | |||||
| " 'N': 'NONE', \n", | |||||
| " 'L': 'LOW',\n", | |||||
| " 'H': 'HIGH'\n", | |||||
| " }\n", | |||||
| "}" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 12, | |||||
| "id": "d42106a3-9eb5-4580-9143-d7ae061b6d4c", | |||||
| "metadata": {}, | |||||
| "outputs": [ | |||||
| { | |||||
| "data": { | |||||
| "text/plain": " AV AC PR UI S C I A score\n0 NETWORK LOW NONE REQUIRED CHANGED LOW LOW NONE 3.5\n1 NETWORK LOW NONE NONE UNCHANGED NONE NONE HIGH 5.2\n2 NETWORK LOW NONE NONE UNCHANGED NONE NONE HIGH 5.2\n3 NETWORK LOW NONE REQUIRED CHANGED LOW LOW NONE 3.5\n4 NETWORK LOW NONE REQUIRED CHANGED LOW LOW NONE 3.5\n.. ... ... ... ... ... ... ... ... ...\n705 NETWORK LOW NONE NONE UNCHANGED HIGH HIGH HIGH 5.6\n706 LOCAL LOW LOW NONE UNCHANGED HIGH NONE NONE 3.0\n707 NETWORK LOW NONE NONE UNCHANGED HIGH HIGH HIGH 5.6\n708 NETWORK LOW NONE NONE UNCHANGED NONE LOW LOW 5.0\n709 NETWORK LOW NONE NONE UNCHANGED HIGH NONE NONE 5.2\n\n[710 rows x 9 columns]", | |||||
| "text/html": "<div>\n<style scoped>\n .dataframe tbody tr th:only-of-type {\n vertical-align: middle;\n }\n\n .dataframe tbody tr th {\n vertical-align: top;\n }\n\n .dataframe thead th {\n text-align: right;\n }\n</style>\n<table border=\"1\" class=\"dataframe\">\n <thead>\n <tr style=\"text-align: right;\">\n <th></th>\n <th>AV</th>\n <th>AC</th>\n <th>PR</th>\n <th>UI</th>\n <th>S</th>\n <th>C</th>\n <th>I</th>\n <th>A</th>\n <th>score</th>\n </tr>\n </thead>\n <tbody>\n <tr>\n <th>0</th>\n <td>NETWORK</td>\n <td>LOW</td>\n <td>NONE</td>\n <td>REQUIRED</td>\n <td>CHANGED</td>\n <td>LOW</td>\n <td>LOW</td>\n <td>NONE</td>\n <td>3.5</td>\n </tr>\n <tr>\n <th>1</th>\n <td>NETWORK</td>\n <td>LOW</td>\n <td>NONE</td>\n <td>NONE</td>\n <td>UNCHANGED</td>\n <td>NONE</td>\n <td>NONE</td>\n <td>HIGH</td>\n <td>5.2</td>\n </tr>\n <tr>\n <th>2</th>\n <td>NETWORK</td>\n <td>LOW</td>\n <td>NONE</td>\n <td>NONE</td>\n <td>UNCHANGED</td>\n <td>NONE</td>\n <td>NONE</td>\n <td>HIGH</td>\n <td>5.2</td>\n </tr>\n <tr>\n <th>3</th>\n <td>NETWORK</td>\n <td>LOW</td>\n <td>NONE</td>\n <td>REQUIRED</td>\n <td>CHANGED</td>\n <td>LOW</td>\n <td>LOW</td>\n <td>NONE</td>\n <td>3.5</td>\n </tr>\n <tr>\n <th>4</th>\n <td>NETWORK</td>\n <td>LOW</td>\n <td>NONE</td>\n <td>REQUIRED</td>\n <td>CHANGED</td>\n <td>LOW</td>\n <td>LOW</td>\n <td>NONE</td>\n <td>3.5</td>\n </tr>\n <tr>\n <th>...</th>\n <td>...</td>\n <td>...</td>\n <td>...</td>\n <td>...</td>\n <td>...</td>\n <td>...</td>\n <td>...</td>\n <td>...</td>\n <td>...</td>\n </tr>\n <tr>\n <th>705</th>\n <td>NETWORK</td>\n <td>LOW</td>\n <td>NONE</td>\n <td>NONE</td>\n <td>UNCHANGED</td>\n <td>HIGH</td>\n <td>HIGH</td>\n <td>HIGH</td>\n <td>5.6</td>\n </tr>\n <tr>\n <th>706</th>\n <td>LOCAL</td>\n <td>LOW</td>\n <td>LOW</td>\n <td>NONE</td>\n <td>UNCHANGED</td>\n <td>HIGH</td>\n <td>NONE</td>\n <td>NONE</td>\n <td>3.0</td>\n </tr>\n <tr>\n <th>707</th>\n <td>NETWORK</td>\n <td>LOW</td>\n <td>NONE</td>\n <td>NONE</td>\n <td>UNCHANGED</td>\n <td>HIGH</td>\n <td>HIGH</td>\n <td>HIGH</td>\n <td>5.6</td>\n </tr>\n <tr>\n <th>708</th>\n <td>NETWORK</td>\n <td>LOW</td>\n <td>NONE</td>\n <td>NONE</td>\n <td>UNCHANGED</td>\n <td>NONE</td>\n <td>LOW</td>\n <td>LOW</td>\n <td>5.0</td>\n </tr>\n <tr>\n <th>709</th>\n <td>NETWORK</td>\n <td>LOW</td>\n <td>NONE</td>\n <td>NONE</td>\n <td>UNCHANGED</td>\n <td>HIGH</td>\n <td>NONE</td>\n <td>NONE</td>\n <td>5.2</td>\n </tr>\n </tbody>\n</table>\n<p>710 rows × 9 columns</p>\n</div>" | |||||
| }, | |||||
| "execution_count": 12, | |||||
| "metadata": {}, | |||||
| "output_type": "execute_result" | |||||
| } | |||||
| ], | |||||
| "source": [ | |||||
| "# 替换 DataFrame 中的值\n", | |||||
| "train_data.replace(dict, inplace=True)\n", | |||||
| "train_data" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 13, | |||||
| "id": "f07b2d92-8271-46c8-ab90-a19570dd2566", | |||||
| "metadata": {}, | |||||
| "outputs": [], | |||||
| "source": [ | |||||
| "train_data.insert(0, 'description', train_data_temp)" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 14, | |||||
| "id": "5ca97546-e120-4e80-b7dc-67a00c1bbf45", | |||||
| "metadata": {}, | |||||
| "outputs": [ | |||||
| { | |||||
| "name": "stdout", | |||||
| "output_type": "stream", | |||||
| "text": [ | |||||
| " description AV AC PR \\\n", | |||||
| "0 Stored & Reflected XSS affecting Xbtit NUMBERT... NETWORK LOW NONE \n", | |||||
| "1 NULL Pointer Dereference in APITAG NULL Pointe... NETWORK LOW NONE \n", | |||||
| "2 NULL Pointer Dereference in APITAG NULL Pointe... NETWORK LOW NONE \n", | |||||
| "3 Reflected XSS vulnerability NUMBERTAG in icehr... NETWORK LOW NONE \n", | |||||
| "4 Reflected XSS vulnerabilities NUMBERTAG in ice... NETWORK LOW NONE \n", | |||||
| ".. ... ... ... ... \n", | |||||
| "705 pboot cms NUMBERTAG RCE. 漏洞详情: URLTAG 声明 APITA... NETWORK LOW NONE \n", | |||||
| "706 .NET CVE backfill round NUMBERTAG Hello, Pleas... LOCAL LOW LOW \n", | |||||
| "707 Backport of NUMBERTAG fixes to NUMBERTAG Thank... NETWORK LOW NONE \n", | |||||
| "708 Update impacted packages for CVETAG . Hi, This... NETWORK LOW NONE \n", | |||||
| "709 CVE Dio NUMBERTAG Google OVS Scanner. Package ... NETWORK LOW NONE \n", | |||||
| "\n", | |||||
| " UI S C I A score \n", | |||||
| "0 REQUIRED CHANGED LOW LOW NONE 3.5 \n", | |||||
| "1 NONE UNCHANGED NONE NONE HIGH 5.2 \n", | |||||
| "2 NONE UNCHANGED NONE NONE HIGH 5.2 \n", | |||||
| "3 REQUIRED CHANGED LOW LOW NONE 3.5 \n", | |||||
| "4 REQUIRED CHANGED LOW LOW NONE 3.5 \n", | |||||
| ".. ... ... ... ... ... ... \n", | |||||
| "705 NONE UNCHANGED HIGH HIGH HIGH 5.6 \n", | |||||
| "706 NONE UNCHANGED HIGH NONE NONE 3.0 \n", | |||||
| "707 NONE UNCHANGED HIGH HIGH HIGH 5.6 \n", | |||||
| "708 NONE UNCHANGED NONE LOW LOW 5.0 \n", | |||||
| "709 NONE UNCHANGED HIGH NONE NONE 5.2 \n", | |||||
| "\n", | |||||
| "[710 rows x 10 columns]\n" | |||||
| ] | |||||
| } | |||||
| ], | |||||
| "source": [ | |||||
| "print(train_data)" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 15, | |||||
| "id": "3e5e14c5-8f88-43d3-945c-1505e11a2490", | |||||
| "metadata": {}, | |||||
| "outputs": [ | |||||
| { | |||||
| "name": "stdout", | |||||
| "output_type": "stream", | |||||
| "text": [ | |||||
| " description AV AC PR \\\n", | |||||
| "0 Stored & Reflected XSS affecting Xbtit NUMBERT... NETWORK LOW NONE \n", | |||||
| "10 illegal memcpy during njs_vmcode_typeof in PAT... NETWORK LOW NONE \n", | |||||
| "11 Heap UAF in njs_await_fulfilled. Env CODETAG P... NETWORK LOW NONE \n", | |||||
| "48 Add nonce to the logout link. The logout link ... NETWORK LOW NONE \n", | |||||
| "50 Divide By Zero in H5T__complete_copy () at PAT... NETWORK LOW NONE \n", | |||||
| ".. ... ... ... ... \n", | |||||
| "705 pboot cms NUMBERTAG RCE. 漏洞详情: URLTAG 声明 APITA... NETWORK LOW NONE \n", | |||||
| "706 .NET CVE backfill round NUMBERTAG Hello, Pleas... LOCAL LOW LOW \n", | |||||
| "707 Backport of NUMBERTAG fixes to NUMBERTAG Thank... NETWORK LOW NONE \n", | |||||
| "708 Update impacted packages for CVETAG . Hi, This... NETWORK LOW NONE \n", | |||||
| "709 CVE Dio NUMBERTAG Google OVS Scanner. Package ... NETWORK LOW NONE \n", | |||||
| "\n", | |||||
| " UI S C I A score prefix \n", | |||||
| "0 REQUIRED CHANGED LOW LOW NONE 3.5 Stored & R \n", | |||||
| "10 NONE UNCHANGED HIGH HIGH HIGH 5.6 illegal me \n", | |||||
| "11 NONE UNCHANGED HIGH HIGH HIGH 5.6 Heap UAF i \n", | |||||
| "48 REQUIRED CHANGED NONE HIGH NONE 3.7 Add nonce \n", | |||||
| "50 REQUIRED UNCHANGED NONE NONE HIGH 4.0 Divide By \n", | |||||
| ".. ... ... ... ... ... ... ... \n", | |||||
| "705 NONE UNCHANGED HIGH HIGH HIGH 5.6 pboot cms \n", | |||||
| "706 NONE UNCHANGED HIGH NONE NONE 3.0 .NET CVE b \n", | |||||
| "707 NONE UNCHANGED HIGH HIGH HIGH 5.6 Backport o \n", | |||||
| "708 NONE UNCHANGED NONE LOW LOW 5.0 Update imp \n", | |||||
| "709 NONE UNCHANGED HIGH NONE NONE 5.2 CVE Dio NU \n", | |||||
| "\n", | |||||
| "[264 rows x 11 columns]\n" | |||||
| ] | |||||
| } | |||||
| ], | |||||
| "source": [ | |||||
| "# 提取前20个字符\n", | |||||
| "train_data['prefix'] = train_data['description'].str[:10]\n", | |||||
| "\n", | |||||
| "# 计算每个前20个字符的出现次数\n", | |||||
| "prefix_counts = train_data['prefix'].value_counts()\n", | |||||
| "\n", | |||||
| "# 只保留那些前20个字符出现次数为1的描述\n", | |||||
| "unique_prefixes = prefix_counts[prefix_counts == 1].index\n", | |||||
| "unique_descriptions = train_data[train_data['prefix'].isin(unique_prefixes)]\n", | |||||
| "print(unique_descriptions)" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 16, | |||||
| "id": "d660a495-fdab-41fc-932c-6e593babc88e", | |||||
| "metadata": {}, | |||||
| "outputs": [ | |||||
| { | |||||
| "name": "stdout", | |||||
| "output_type": "stream", | |||||
| "text": [ | |||||
| " description AV AC PR \\\n", | |||||
| "0 Stored & Reflected XSS affecting Xbtit NUMBERT... NETWORK LOW NONE \n", | |||||
| "10 illegal memcpy during njs_vmcode_typeof in PAT... NETWORK LOW NONE \n", | |||||
| "11 Heap UAF in njs_await_fulfilled. Env CODETAG P... NETWORK LOW NONE \n", | |||||
| "48 Add nonce to the logout link. The logout link ... NETWORK LOW NONE \n", | |||||
| "50 Divide By Zero in H5T__complete_copy () at PAT... NETWORK LOW NONE \n", | |||||
| ".. ... ... ... ... \n", | |||||
| "698 A NUMBERTAG specific heap buffer overflow with... NETWORK LOW NONE \n", | |||||
| "699 Mitigation for CVETAG . Hi there. It appears a... NETWORK LOW NONE \n", | |||||
| "703 Contact APITAG Product Security Team and ask t... NETWORK LOW NONE \n", | |||||
| "707 Backport of NUMBERTAG fixes to NUMBERTAG Thank... NETWORK LOW NONE \n", | |||||
| "709 CVE Dio NUMBERTAG Google OVS Scanner. Package ... NETWORK LOW NONE \n", | |||||
| "\n", | |||||
| " UI S C I A score prefix \n", | |||||
| "0 REQUIRED CHANGED LOW LOW NONE 3.5 Stored & R \n", | |||||
| "10 NONE UNCHANGED HIGH HIGH HIGH 5.6 illegal me \n", | |||||
| "11 NONE UNCHANGED HIGH HIGH HIGH 5.6 Heap UAF i \n", | |||||
| "48 REQUIRED CHANGED NONE HIGH NONE 3.7 Add nonce \n", | |||||
| "50 REQUIRED UNCHANGED NONE NONE HIGH 4.0 Divide By \n", | |||||
| ".. ... ... ... ... ... ... ... \n", | |||||
| "698 NONE UNCHANGED HIGH HIGH HIGH 5.6 A NUMBERTA \n", | |||||
| "699 NONE UNCHANGED NONE NONE HIGH 5.2 Mitigation \n", | |||||
| "703 NONE UNCHANGED LOW LOW LOW 5.2 Contact AP \n", | |||||
| "707 NONE UNCHANGED HIGH HIGH HIGH 5.6 Backport o \n", | |||||
| "709 NONE UNCHANGED HIGH NONE NONE 5.2 CVE Dio NU \n", | |||||
| "\n", | |||||
| "[197 rows x 11 columns]\n" | |||||
| ] | |||||
| } | |||||
| ], | |||||
| "source": [ | |||||
| "# 删除描述长度大于1000的行\n", | |||||
| "temp = pd.DataFrame()\n", | |||||
| "filtered_train_data = pd.DataFrame()\n", | |||||
| "temp = unique_descriptions[unique_descriptions['description'].str.len() <= 1000]\n", | |||||
| "filtered_train_data = temp[temp['description'].str.len() > 100]\n", | |||||
| "print(filtered_train_data)" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 17, | |||||
| "id": "eaa6e29e-7fc1-45b9-809b-a4d43686362c", | |||||
| "metadata": {}, | |||||
| "outputs": [ | |||||
| { | |||||
| "name": "stderr", | |||||
| "output_type": "stream", | |||||
| "text": [ | |||||
| "C:\\Users\\lx\\AppData\\Local\\Temp\\ipykernel_38864\\3885197511.py:1: SettingWithCopyWarning: \n", | |||||
| "A value is trying to be set on a copy of a slice from a DataFrame\n", | |||||
| "\n", | |||||
| "See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n", | |||||
| " filtered_train_data.sort_values(by='prefix', inplace=True)\n" | |||||
| ] | |||||
| } | |||||
| ], | |||||
| "source": [ | |||||
| "filtered_train_data.sort_values(by='prefix', inplace=True)" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 18, | |||||
| "id": "db7adb10-83a9-438f-9681-ac02293cba3e", | |||||
| "metadata": {}, | |||||
| "outputs": [ | |||||
| { | |||||
| "name": "stdout", | |||||
| "output_type": "stream", | |||||
| "text": [ | |||||
| " description AV AC PR \\\n", | |||||
| "698 A NUMBERTAG specific heap buffer overflow with... NETWORK LOW NONE \n", | |||||
| "488 A Remote Code Execution (RCE) vulnerability ex... NETWORK LOW HIGH \n", | |||||
| "51 A heap use after free in in H5AC_unpin_entry. ... NETWORK LOW NONE \n", | |||||
| "408 A package should never try to do unrelated thi... NETWORK LOW NONE \n", | |||||
| "236 A security vulnerability which will lead to co... NETWORK LOW NONE \n", | |||||
| ".. ... ... ... ... \n", | |||||
| "480 一个后台存储型xss漏洞. When adding movie names, malicio... NETWORK LOW LOW \n", | |||||
| "639 关于 CVETAG 漏洞,不要在发 issues 了!!!. APITAG 如果你从前端传递... NETWORK LOW NONE \n", | |||||
| "606 后台服务器组中存在XSS漏洞. 进入后台,点击视频 >服务器组 >添加, 在名称框插入pay... NETWORK LOW LOW \n", | |||||
| "509 固定的cookie NUMBERTAG APITAG FILETAG NUMBERTAG H... NETWORK LOW NONE \n", | |||||
| "52 默认的 APITAG 为什么选择 APITAG 呢?. 版本情况 JDK版本: corret... NETWORK LOW NONE \n", | |||||
| "\n", | |||||
| " UI S C I A score \n", | |||||
| "698 NONE UNCHANGED HIGH HIGH HIGH 5.6 \n", | |||||
| "488 NONE UNCHANGED HIGH HIGH HIGH 3.8 \n", | |||||
| "51 REQUIRED UNCHANGED HIGH HIGH HIGH 4.4 \n", | |||||
| "408 NONE UNCHANGED HIGH HIGH HIGH 5.6 \n", | |||||
| "236 NONE UNCHANGED HIGH HIGH HIGH 5.6 \n", | |||||
| ".. ... ... ... ... ... ... \n", | |||||
| "480 REQUIRED CHANGED LOW LOW NONE 2.9 \n", | |||||
| "639 NONE UNCHANGED HIGH HIGH HIGH 5.6 \n", | |||||
| "606 REQUIRED CHANGED LOW LOW NONE 2.9 \n", | |||||
| "509 NONE UNCHANGED HIGH HIGH HIGH 5.6 \n", | |||||
| "52 NONE UNCHANGED HIGH HIGH HIGH 5.6 \n", | |||||
| "\n", | |||||
| "[197 rows x 10 columns]\n" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "name": "stderr", | |||||
| "output_type": "stream", | |||||
| "text": [ | |||||
| "C:\\Users\\lx\\AppData\\Local\\Temp\\ipykernel_38864\\3846312463.py:1: SettingWithCopyWarning: \n", | |||||
| "A value is trying to be set on a copy of a slice from a DataFrame\n", | |||||
| "\n", | |||||
| "See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n", | |||||
| " filtered_train_data.drop('prefix', axis=1, inplace=True)\n" | |||||
| ] | |||||
| } | |||||
| ], | |||||
| "source": [ | |||||
| "filtered_train_data.drop('prefix', axis=1, inplace=True)\n", | |||||
| "print(filtered_train_data)" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 19, | |||||
| "id": "9cc98bb5-1ae4-4024-b9cc-d3db88996221", | |||||
| "metadata": {}, | |||||
| "outputs": [ | |||||
| { | |||||
| "data": { | |||||
| "text/plain": "2.0" | |||||
| }, | |||||
| "execution_count": 19, | |||||
| "metadata": {}, | |||||
| "output_type": "execute_result" | |||||
| } | |||||
| ], | |||||
| "source": [ | |||||
| "filtered_train_data['score'].min()" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 20, | |||||
| "id": "0c2e00f4-cf7b-4b15-8901-537abb4524e5", | |||||
| "metadata": {}, | |||||
| "outputs": [], | |||||
| "source": [ | |||||
| "filtered_train_data.to_csv(r\"../dataset/filtered_test_dataset.csv\",header=None,index=None)" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 20, | |||||
| "id": "080b3051-8eb8-4c4f-81ad-d3a215c2f693", | |||||
| "metadata": {}, | |||||
| "outputs": [], | |||||
| "source": [] | |||||
| } | |||||
| ], | |||||
| "metadata": { | |||||
| "kernelspec": { | |||||
| "display_name": "Python 3 (ipykernel)", | |||||
| "language": "python", | |||||
| "name": "python3" | |||||
| }, | |||||
| "language_info": { | |||||
| "codemirror_mode": { | |||||
| "name": "ipython", | |||||
| "version": 3 | |||||
| }, | |||||
| "file_extension": ".py", | |||||
| "mimetype": "text/x-python", | |||||
| "name": "python", | |||||
| "nbconvert_exporter": "python", | |||||
| "pygments_lexer": "ipython3", | |||||
| "version": "3.11.4" | |||||
| } | |||||
| }, | |||||
| "nbformat": 4, | |||||
| "nbformat_minor": 5 | |||||
| } | |||||
+ 533
- 0
Models+K-Means/main/decisionTree/test_decisionTree.ipynb
View File
| @@ -0,0 +1,533 @@ | |||||
| { | |||||
| "cells": [ | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 8, | |||||
| "id": "64ff4cb2-6a11-4558-9b58-02d23d391b34", | |||||
| "metadata": {}, | |||||
| "outputs": [], | |||||
| "source": [ | |||||
| "import pandas as pd\n", | |||||
| "import json\n", | |||||
| "from sklearn import tree\n", | |||||
| "from sklearn.model_selection import train_test_split as tsplit \n", | |||||
| "from sklearn.metrics import classification_report\n", | |||||
| "from sklearn.metrics import accuracy_score, classification_report, confusion_matrix\n", | |||||
| "from sklearn.preprocessing import OneHotEncoder" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 9, | |||||
| "id": "4afcae4b-305f-4ce6-af54-08edba088e0b", | |||||
| "metadata": {}, | |||||
| "outputs": [], | |||||
| "source": [ | |||||
| "def transform_value(val):\n", | |||||
| " return val.split(':')[1]" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 10, | |||||
| "id": "1b1287ad-40c8-4059-ad05-097bad2feac7", | |||||
| "metadata": {}, | |||||
| "outputs": [], | |||||
| "source": [ | |||||
| "def extract_data(s):\n", | |||||
| " data_temp = pd.read_json(s)\n", | |||||
| " columns = ['AV', 'AC', 'PR', 'UI', 'S', 'C', 'I', 'A']\n", | |||||
| " vectorString = data_temp['vectorString']\n", | |||||
| " temp = []\n", | |||||
| " for i in range(vectorString.size):\n", | |||||
| " part = vectorString[i].split('/')\n", | |||||
| " list_items = part[1::]\n", | |||||
| " temp.append(list_items)\n", | |||||
| " data = pd.DataFrame(temp, columns=columns)\n", | |||||
| " data = data.applymap(transform_value)\n", | |||||
| " data['severity'] = data_temp['severity']\n", | |||||
| " return data" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 11, | |||||
| "id": "6962b88e-2523-4bde-8fa6-df96bfbc5221", | |||||
| "metadata": {}, | |||||
| "outputs": [ | |||||
| { | |||||
| "name": "stdout", | |||||
| "output_type": "stream", | |||||
| "text": [ | |||||
| " AV AC PR UI S C I A severity\n", | |||||
| "0 N L N R C L L N MEDIUM\n", | |||||
| "1 N L N N U N N H HIGH\n", | |||||
| "2 N L N N U N N H HIGH\n", | |||||
| "3 N L N R C L L N MEDIUM\n", | |||||
| "4 N L N R C L L N MEDIUM\n", | |||||
| ".. .. .. .. .. .. .. .. .. ...\n", | |||||
| "705 N L N N U H H H CRITICAL\n", | |||||
| "706 L L L N U H N N MEDIUM\n", | |||||
| "707 N L N N U H H H CRITICAL\n", | |||||
| "708 N L N N U N L L MEDIUM\n", | |||||
| "709 N L N N U H N N HIGH\n", | |||||
| "\n", | |||||
| "[710 rows x 9 columns]\n" | |||||
| ] | |||||
| } | |||||
| ], | |||||
| "source": [ | |||||
| "data_train = extract_data('SIR_train_set.json')\n", | |||||
| "data_test = extract_data('SIR_test_set.json')\n", | |||||
| "data_validation = extract_data('SIR_validation_set.json')\n", | |||||
| "data_train\n", | |||||
| "print(data_test)" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 12, | |||||
| "id": "49ccfdf6-99f0-4c5e-9772-03e500e6b6d6", | |||||
| "metadata": {}, | |||||
| "outputs": [ | |||||
| { | |||||
| "data": { | |||||
| "text/html": [ | |||||
| "<div>\n", | |||||
| "<style scoped>\n", | |||||
| " .dataframe tbody tr th:only-of-type {\n", | |||||
| " vertical-align: middle;\n", | |||||
| " }\n", | |||||
| "\n", | |||||
| " .dataframe tbody tr th {\n", | |||||
| " vertical-align: top;\n", | |||||
| " }\n", | |||||
| "\n", | |||||
| " .dataframe thead th {\n", | |||||
| " text-align: right;\n", | |||||
| " }\n", | |||||
| "</style>\n", | |||||
| "<table border=\"1\" class=\"dataframe\">\n", | |||||
| " <thead>\n", | |||||
| " <tr style=\"text-align: right;\">\n", | |||||
| " <th></th>\n", | |||||
| " <th>AV</th>\n", | |||||
| " <th>AC</th>\n", | |||||
| " <th>PR</th>\n", | |||||
| " <th>UI</th>\n", | |||||
| " <th>S</th>\n", | |||||
| " <th>C</th>\n", | |||||
| " <th>I</th>\n", | |||||
| " <th>A</th>\n", | |||||
| " </tr>\n", | |||||
| " </thead>\n", | |||||
| " <tbody>\n", | |||||
| " <tr>\n", | |||||
| " <th>0</th>\n", | |||||
| " <td>N</td>\n", | |||||
| " <td>L</td>\n", | |||||
| " <td>N</td>\n", | |||||
| " <td>N</td>\n", | |||||
| " <td>U</td>\n", | |||||
| " <td>H</td>\n", | |||||
| " <td>N</td>\n", | |||||
| " <td>N</td>\n", | |||||
| " </tr>\n", | |||||
| " <tr>\n", | |||||
| " <th>1</th>\n", | |||||
| " <td>N</td>\n", | |||||
| " <td>L</td>\n", | |||||
| " <td>N</td>\n", | |||||
| " <td>N</td>\n", | |||||
| " <td>U</td>\n", | |||||
| " <td>H</td>\n", | |||||
| " <td>H</td>\n", | |||||
| " <td>H</td>\n", | |||||
| " </tr>\n", | |||||
| " <tr>\n", | |||||
| " <th>2</th>\n", | |||||
| " <td>N</td>\n", | |||||
| " <td>L</td>\n", | |||||
| " <td>N</td>\n", | |||||
| " <td>N</td>\n", | |||||
| " <td>U</td>\n", | |||||
| " <td>H</td>\n", | |||||
| " <td>N</td>\n", | |||||
| " <td>N</td>\n", | |||||
| " </tr>\n", | |||||
| " <tr>\n", | |||||
| " <th>3</th>\n", | |||||
| " <td>N</td>\n", | |||||
| " <td>H</td>\n", | |||||
| " <td>N</td>\n", | |||||
| " <td>N</td>\n", | |||||
| " <td>U</td>\n", | |||||
| " <td>H</td>\n", | |||||
| " <td>H</td>\n", | |||||
| " <td>H</td>\n", | |||||
| " </tr>\n", | |||||
| " <tr>\n", | |||||
| " <th>4</th>\n", | |||||
| " <td>N</td>\n", | |||||
| " <td>L</td>\n", | |||||
| " <td>N</td>\n", | |||||
| " <td>R</td>\n", | |||||
| " <td>U</td>\n", | |||||
| " <td>H</td>\n", | |||||
| " <td>H</td>\n", | |||||
| " <td>H</td>\n", | |||||
| " </tr>\n", | |||||
| " <tr>\n", | |||||
| " <th>...</th>\n", | |||||
| " <td>...</td>\n", | |||||
| " <td>...</td>\n", | |||||
| " <td>...</td>\n", | |||||
| " <td>...</td>\n", | |||||
| " <td>...</td>\n", | |||||
| " <td>...</td>\n", | |||||
| " <td>...</td>\n", | |||||
| " <td>...</td>\n", | |||||
| " </tr>\n", | |||||
| " <tr>\n", | |||||
| " <th>5619</th>\n", | |||||
| " <td>N</td>\n", | |||||
| " <td>L</td>\n", | |||||
| " <td>N</td>\n", | |||||
| " <td>N</td>\n", | |||||
| " <td>U</td>\n", | |||||
| " <td>N</td>\n", | |||||
| " <td>N</td>\n", | |||||
| " <td>H</td>\n", | |||||
| " </tr>\n", | |||||
| " <tr>\n", | |||||
| " <th>5620</th>\n", | |||||
| " <td>N</td>\n", | |||||
| " <td>L</td>\n", | |||||
| " <td>N</td>\n", | |||||
| " <td>R</td>\n", | |||||
| " <td>C</td>\n", | |||||
| " <td>L</td>\n", | |||||
| " <td>L</td>\n", | |||||
| " <td>N</td>\n", | |||||
| " </tr>\n", | |||||
| " <tr>\n", | |||||
| " <th>5621</th>\n", | |||||
| " <td>N</td>\n", | |||||
| " <td>L</td>\n", | |||||
| " <td>N</td>\n", | |||||
| " <td>R</td>\n", | |||||
| " <td>U</td>\n", | |||||
| " <td>N</td>\n", | |||||
| " <td>H</td>\n", | |||||
| " <td>N</td>\n", | |||||
| " </tr>\n", | |||||
| " <tr>\n", | |||||
| " <th>5622</th>\n", | |||||
| " <td>N</td>\n", | |||||
| " <td>L</td>\n", | |||||
| " <td>N</td>\n", | |||||
| " <td>R</td>\n", | |||||
| " <td>U</td>\n", | |||||
| " <td>N</td>\n", | |||||
| " <td>H</td>\n", | |||||
| " <td>N</td>\n", | |||||
| " </tr>\n", | |||||
| " <tr>\n", | |||||
| " <th>5623</th>\n", | |||||
| " <td>N</td>\n", | |||||
| " <td>L</td>\n", | |||||
| " <td>L</td>\n", | |||||
| " <td>R</td>\n", | |||||
| " <td>C</td>\n", | |||||
| " <td>L</td>\n", | |||||
| " <td>L</td>\n", | |||||
| " <td>N</td>\n", | |||||
| " </tr>\n", | |||||
| " </tbody>\n", | |||||
| "</table>\n", | |||||
| "<p>5624 rows × 8 columns</p>\n", | |||||
| "</div>" | |||||
| ], | |||||
| "text/plain": [ | |||||
| " AV AC PR UI S C I A\n", | |||||
| "0 N L N N U H N N\n", | |||||
| "1 N L N N U H H H\n", | |||||
| "2 N L N N U H N N\n", | |||||
| "3 N H N N U H H H\n", | |||||
| "4 N L N R U H H H\n", | |||||
| "... .. .. .. .. .. .. .. ..\n", | |||||
| "5619 N L N N U N N H\n", | |||||
| "5620 N L N R C L L N\n", | |||||
| "5621 N L N R U N H N\n", | |||||
| "5622 N L N R U N H N\n", | |||||
| "5623 N L L R C L L N\n", | |||||
| "\n", | |||||
| "[5624 rows x 8 columns]" | |||||
| ] | |||||
| }, | |||||
| "execution_count": 12, | |||||
| "metadata": {}, | |||||
| "output_type": "execute_result" | |||||
| } | |||||
| ], | |||||
| "source": [ | |||||
| "lw = data_train[['AV', 'AC', 'PR', 'UI', 'S', 'C', 'I', 'A']]\n", | |||||
| "lw" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 13, | |||||
| "id": "eef35137-c9f8-49cb-8232-506d564f1fb4", | |||||
| "metadata": {}, | |||||
| "outputs": [ | |||||
| { | |||||
| "name": "stdout", | |||||
| "output_type": "stream", | |||||
| "text": [ | |||||
| " AV_A AV_L AV_N AV_P AC_H AC_L PR_H PR_L PR_N UI_N ... S_U \\\n", | |||||
| "0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 1.0 ... 1.0 \n", | |||||
| "1 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 1.0 ... 1.0 \n", | |||||
| "2 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 1.0 ... 1.0 \n", | |||||
| "3 0.0 0.0 1.0 0.0 1.0 0.0 0.0 0.0 1.0 1.0 ... 1.0 \n", | |||||
| "4 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 ... 1.0 \n", | |||||
| "... ... ... ... ... ... ... ... ... ... ... ... ... \n", | |||||
| "5619 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 1.0 ... 1.0 \n", | |||||
| "5620 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 ... 0.0 \n", | |||||
| "5621 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 ... 1.0 \n", | |||||
| "5622 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 ... 1.0 \n", | |||||
| "5623 0.0 0.0 1.0 0.0 0.0 1.0 0.0 1.0 0.0 0.0 ... 0.0 \n", | |||||
| "\n", | |||||
| " C_H C_L C_N I_H I_L I_N A_H A_L A_N \n", | |||||
| "0 1.0 0.0 0.0 0.0 0.0 1.0 0.0 0.0 1.0 \n", | |||||
| "1 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 \n", | |||||
| "2 1.0 0.0 0.0 0.0 0.0 1.0 0.0 0.0 1.0 \n", | |||||
| "3 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 \n", | |||||
| "4 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 \n", | |||||
| "... ... ... ... ... ... ... ... ... ... \n", | |||||
| "5619 0.0 0.0 1.0 0.0 0.0 1.0 1.0 0.0 0.0 \n", | |||||
| "5620 0.0 1.0 0.0 0.0 1.0 0.0 0.0 0.0 1.0 \n", | |||||
| "5621 0.0 0.0 1.0 1.0 0.0 0.0 0.0 0.0 1.0 \n", | |||||
| "5622 0.0 0.0 1.0 1.0 0.0 0.0 0.0 0.0 1.0 \n", | |||||
| "5623 0.0 1.0 0.0 0.0 1.0 0.0 0.0 0.0 1.0 \n", | |||||
| "\n", | |||||
| "[5624 rows x 22 columns]\n" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "name": "stderr", | |||||
| "output_type": "stream", | |||||
| "text": [ | |||||
| "C:\\Users\\lw\\AppData\\Local\\Programs\\Python\\Python311\\Lib\\site-packages\\sklearn\\preprocessing\\_encoders.py:972: FutureWarning: `sparse` was renamed to `sparse_output` in version 1.2 and will be removed in 1.4. `sparse_output` is ignored unless you leave `sparse` to its default value.\n", | |||||
| " warnings.warn(\n" | |||||
| ] | |||||
| } | |||||
| ], | |||||
| "source": [ | |||||
| "def encode(data):\n", | |||||
| " # 初始化 OneHotEncoder\n", | |||||
| " encoder = OneHotEncoder(sparse=False)\n", | |||||
| "\n", | |||||
| " # 转换字符数据为数值\n", | |||||
| " encoded_features = encoder.fit_transform(data[['AV', 'AC', 'PR', 'UI', 'S', 'C', 'I', 'A']])\n", | |||||
| " encoded_data = pd.DataFrame(encoded_features, columns=encoder.get_feature_names_out(['AV', 'AC', 'PR', 'UI', 'S', 'C', 'I', 'A']))\n", | |||||
| " return encoded_data\n", | |||||
| "print(encode(lw))\n" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 16, | |||||
| "id": "25bbd901-d4aa-44cb-8f1f-2720c553bfad", | |||||
| "metadata": {}, | |||||
| "outputs": [ | |||||
| { | |||||
| "name": "stdout", | |||||
| "output_type": "stream", | |||||
| "text": [ | |||||
| " AV_A AV_L AV_N AV_P AC_H AC_L PR_H PR_L PR_N UI_N ... S_U \\\n", | |||||
| "0 0 0.0 1.0 0 0.0 1.0 0.0 0.0 1.0 0.0 ... 0.0 \n", | |||||
| "1 0 0.0 1.0 0 0.0 1.0 0.0 0.0 1.0 1.0 ... 1.0 \n", | |||||
| "2 0 0.0 1.0 0 0.0 1.0 0.0 0.0 1.0 1.0 ... 1.0 \n", | |||||
| "3 0 0.0 1.0 0 0.0 1.0 0.0 0.0 1.0 0.0 ... 0.0 \n", | |||||
| "4 0 0.0 1.0 0 0.0 1.0 0.0 0.0 1.0 0.0 ... 0.0 \n", | |||||
| ".. ... ... ... ... ... ... ... ... ... ... ... ... \n", | |||||
| "705 0 0.0 1.0 0 0.0 1.0 0.0 0.0 1.0 1.0 ... 1.0 \n", | |||||
| "706 0 1.0 0.0 0 0.0 1.0 0.0 1.0 0.0 1.0 ... 1.0 \n", | |||||
| "707 0 0.0 1.0 0 0.0 1.0 0.0 0.0 1.0 1.0 ... 1.0 \n", | |||||
| "708 0 0.0 1.0 0 0.0 1.0 0.0 0.0 1.0 1.0 ... 1.0 \n", | |||||
| "709 0 0.0 1.0 0 0.0 1.0 0.0 0.0 1.0 1.0 ... 1.0 \n", | |||||
| "\n", | |||||
| " C_H C_L C_N I_H I_L I_N A_H A_L A_N \n", | |||||
| "0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 0.0 1.0 \n", | |||||
| "1 0.0 0.0 1.0 0.0 0.0 1.0 1.0 0.0 0.0 \n", | |||||
| "2 0.0 0.0 1.0 0.0 0.0 1.0 1.0 0.0 0.0 \n", | |||||
| "3 0.0 1.0 0.0 0.0 1.0 0.0 0.0 0.0 1.0 \n", | |||||
| "4 0.0 1.0 0.0 0.0 1.0 0.0 0.0 0.0 1.0 \n", | |||||
| ".. ... ... ... ... ... ... ... ... ... \n", | |||||
| "705 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 \n", | |||||
| "706 1.0 0.0 0.0 0.0 0.0 1.0 0.0 0.0 1.0 \n", | |||||
| "707 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 \n", | |||||
| "708 0.0 0.0 1.0 0.0 1.0 0.0 0.0 1.0 0.0 \n", | |||||
| "709 1.0 0.0 0.0 0.0 0.0 1.0 0.0 0.0 1.0 \n", | |||||
| "\n", | |||||
| "[710 rows x 22 columns]\n" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "name": "stderr", | |||||
| "output_type": "stream", | |||||
| "text": [ | |||||
| "C:\\Users\\lw\\AppData\\Local\\Programs\\Python\\Python311\\Lib\\site-packages\\sklearn\\preprocessing\\_encoders.py:972: FutureWarning: `sparse` was renamed to `sparse_output` in version 1.2 and will be removed in 1.4. `sparse_output` is ignored unless you leave `sparse` to its default value.\n", | |||||
| " warnings.warn(\n" | |||||
| ] | |||||
| } | |||||
| ], | |||||
| "source": [ | |||||
| "x_test = encode(data_test[['AV', 'AC', 'PR', 'UI', 'S', 'C', 'I', 'A']])\n", | |||||
| "x_test.insert(0, 'AV_A', 0)\n", | |||||
| "x_test.insert(3, 'AV_P', 0)\n", | |||||
| "print(x_test)" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 15, | |||||
| "id": "12c94e10-99e6-48ed-b659-6d99bd41d049", | |||||
| "metadata": {}, | |||||
| "outputs": [ | |||||
| { | |||||
| "name": "stdout", | |||||
| "output_type": "stream", | |||||
| "text": [ | |||||
| "分类报告:\n", | |||||
| " precision recall f1-score support\n", | |||||
| "\n", | |||||
| " CRITICAL 0.99 0.97 0.98 155\n", | |||||
| " HIGH 0.98 1.00 0.99 241\n", | |||||
| " LOW 0.00 0.00 0.00 0\n", | |||||
| " MEDIUM 1.00 0.99 1.00 314\n", | |||||
| "\n", | |||||
| " accuracy 0.99 710\n", | |||||
| " macro avg 0.74 0.74 0.74 710\n", | |||||
| "weighted avg 0.99 0.99 0.99 710\n", | |||||
| "\n", | |||||
| "测试集分类的准确率:0.9901\n", | |||||
| "\n", | |||||
| "分类报告:\n", | |||||
| " precision recall f1-score support\n", | |||||
| "\n", | |||||
| " CRITICAL 1.00 1.00 1.00 137\n", | |||||
| " HIGH 1.00 1.00 1.00 228\n", | |||||
| " LOW 0.67 0.80 0.73 5\n", | |||||
| " MEDIUM 0.99 0.99 0.99 333\n", | |||||
| "\n", | |||||
| " accuracy 0.99 703\n", | |||||
| " macro avg 0.92 0.95 0.93 703\n", | |||||
| "weighted avg 0.99 0.99 0.99 703\n", | |||||
| "\n", | |||||
| "验证集分类的准确率:0.9943\n" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "name": "stderr", | |||||
| "output_type": "stream", | |||||
| "text": [ | |||||
| "C:\\Users\\lw\\AppData\\Local\\Programs\\Python\\Python311\\Lib\\site-packages\\sklearn\\preprocessing\\_encoders.py:972: FutureWarning: `sparse` was renamed to `sparse_output` in version 1.2 and will be removed in 1.4. `sparse_output` is ignored unless you leave `sparse` to its default value.\n", | |||||
| " warnings.warn(\n", | |||||
| "C:\\Users\\lw\\AppData\\Local\\Programs\\Python\\Python311\\Lib\\site-packages\\sklearn\\preprocessing\\_encoders.py:972: FutureWarning: `sparse` was renamed to `sparse_output` in version 1.2 and will be removed in 1.4. `sparse_output` is ignored unless you leave `sparse` to its default value.\n", | |||||
| " warnings.warn(\n", | |||||
| "C:\\Users\\lw\\AppData\\Local\\Programs\\Python\\Python311\\Lib\\site-packages\\sklearn\\preprocessing\\_encoders.py:972: FutureWarning: `sparse` was renamed to `sparse_output` in version 1.2 and will be removed in 1.4. `sparse_output` is ignored unless you leave `sparse` to its default value.\n", | |||||
| " warnings.warn(\n", | |||||
| "C:\\Users\\lw\\AppData\\Local\\Programs\\Python\\Python311\\Lib\\site-packages\\sklearn\\metrics\\_classification.py:1469: UndefinedMetricWarning: Recall and F-score are ill-defined and being set to 0.0 in labels with no true samples. Use `zero_division` parameter to control this behavior.\n", | |||||
| " _warn_prf(average, modifier, msg_start, len(result))\n", | |||||
| "C:\\Users\\lw\\AppData\\Local\\Programs\\Python\\Python311\\Lib\\site-packages\\sklearn\\metrics\\_classification.py:1469: UndefinedMetricWarning: Recall and F-score are ill-defined and being set to 0.0 in labels with no true samples. Use `zero_division` parameter to control this behavior.\n", | |||||
| " _warn_prf(average, modifier, msg_start, len(result))\n", | |||||
| "C:\\Users\\lw\\AppData\\Local\\Programs\\Python\\Python311\\Lib\\site-packages\\sklearn\\metrics\\_classification.py:1469: UndefinedMetricWarning: Recall and F-score are ill-defined and being set to 0.0 in labels with no true samples. Use `zero_division` parameter to control this behavior.\n", | |||||
| " _warn_prf(average, modifier, msg_start, len(result))\n" | |||||
| ] | |||||
| } | |||||
| ], | |||||
| "source": [ | |||||
| "x_train = encode(data_train[['AV', 'AC', 'PR', 'UI', 'S', 'C', 'I', 'A']])\n", | |||||
| "y_train = data_train['severity']\n", | |||||
| "x_test = encode(data_test[['AV', 'AC', 'PR', 'UI', 'S', 'C', 'I', 'A']])\n", | |||||
| "x_test.insert(0, 'AV_A', 0)\n", | |||||
| "x_test.insert(3, 'AV_P', 0)\n", | |||||
| "y_test = data_test['severity']\n", | |||||
| "x_validation = encode(data_validation[['AV', 'AC', 'PR', 'UI', 'S', 'C', 'I', 'A']])\n", | |||||
| "y_validation = data_validation['severity']\n", | |||||
| "# 创建并训练决策树分类器\n", | |||||
| "m = tree.DecisionTreeClassifier()\n", | |||||
| "m.fit(x_train, y_train)\n", | |||||
| "\n", | |||||
| "# 使用模型进行预测\n", | |||||
| "y_test_pred = m.predict(x_test)\n", | |||||
| "\n", | |||||
| "# 打印测试集分类报告\n", | |||||
| "print('分类报告:\\n', classification_report(y_test, y_test_pred))\n", | |||||
| "\n", | |||||
| "# 打印准确率\n", | |||||
| "test_accuracy = m.score(x_test, y_test)\n", | |||||
| "print('测试集分类的准确率:%0.4f' % test_accuracy)\n", | |||||
| "\n", | |||||
| "print()\n", | |||||
| "\n", | |||||
| "# 使用模型进行预测\n", | |||||
| "y_validation_pred = m.predict(x_validation)\n", | |||||
| "\n", | |||||
| "# 打印测试集分类报告\n", | |||||
| "print('分类报告:\\n', classification_report(y_validation, y_validation_pred))\n", | |||||
| "\n", | |||||
| "# 打印准确率\n", | |||||
| "validation_accuracy = m.score(x_validation, y_validation)\n", | |||||
| "print('验证集分类的准确率:%0.4f' % validation_accuracy)" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": null, | |||||
| "id": "98e4b40f-8269-4c7b-94a3-567c5f48184d", | |||||
| "metadata": {}, | |||||
| "outputs": [], | |||||
| "source": [] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": null, | |||||
| "id": "9d307a7e-c229-4eb1-8376-0366cbcc961b", | |||||
| "metadata": {}, | |||||
| "outputs": [], | |||||
| "source": [] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": null, | |||||
| "id": "29780f8c-bbc1-4bb3-8c4d-bb1fec7ab7e3", | |||||
| "metadata": {}, | |||||
| "outputs": [], | |||||
| "source": [] | |||||
| } | |||||
| ], | |||||
| "metadata": { | |||||
| "kernelspec": { | |||||
| "display_name": "Python 3 (ipykernel)", | |||||
| "language": "python", | |||||
| "name": "python3" | |||||
| }, | |||||
| "language_info": { | |||||
| "codemirror_mode": { | |||||
| "name": "ipython", | |||||
| "version": 3 | |||||
| }, | |||||
| "file_extension": ".py", | |||||
| "mimetype": "text/x-python", | |||||
| "name": "python", | |||||
| "nbconvert_exporter": "python", | |||||
| "pygments_lexer": "ipython3", | |||||
| "version": "3.11.4" | |||||
| } | |||||
| }, | |||||
| "nbformat": 4, | |||||
| "nbformat_minor": 5 | |||||
| } | |||||
+ 67
- 0
Models+K-Means/main/json2csv.py
View File
| @@ -0,0 +1,67 @@ | |||||
| import json | |||||
| import csv | |||||
| import pandas as pd | |||||
| import re | |||||
| def process_unicode_escape(text): | |||||
| return re.sub(r'\\u([\da-fA-F]{4})', lambda x: chr(int(x.group(1), 16)), text) | |||||
| def main(): | |||||
| jsonToCsv() | |||||
| dataProcess() | |||||
| dataProcess2() | |||||
| dataProcess3() | |||||
| def jsonToCsv(): | |||||
| with open('../data/SIR_train_set.json', 'r', encoding='UTF-8') as json_file: | |||||
| data = json.load(json_file) | |||||
| # 如果 data 是列表,遍历每一项 | |||||
| if isinstance(data, list): | |||||
| for item in data: | |||||
| if 'description' in item: | |||||
| item['description'] = process_unicode_escape(item['description']) | |||||
| # 写入 CSV 文件 | |||||
| with open('../data_process_cache/SIR_train_set.csv', 'w', newline='', encoding='UTF-8') as csv_file: | |||||
| if isinstance(data, list) and len(data) > 0: | |||||
| fieldnames = data[0].keys() | |||||
| writer = csv.DictWriter(csv_file, fieldnames=fieldnames) | |||||
| writer.writeheader() | |||||
| writer.writerows(data) | |||||
| def dataProcess(): | |||||
| columns_to_keep = ['description', 'vectorString'] | |||||
| with open('../data_process_cache/SIR_train_set.csv', 'r', encoding='UTF-8') as infile: | |||||
| reader = csv.DictReader(infile) | |||||
| filtered_rows = [{col: row[col] for col in columns_to_keep} for row in reader] | |||||
| with open('../data_process_cache/train_vecStr.csv', 'w', newline='', encoding='utf-8') as outfile: | |||||
| if filtered_rows: | |||||
| writer = csv.DictWriter(outfile, fieldnames=columns_to_keep) | |||||
| writer.writeheader() # Ensure headers are written | |||||
| writer.writerows(filtered_rows) | |||||
| def dataProcess2(): | |||||
| df = pd.read_csv('../data_process_cache/train_vecStr.csv', encoding='UTF-8') | |||||
| df_expanded = df['vectorString'].str.split('/', expand=True) | |||||
| df = pd.concat([df, df_expanded], axis=1) | |||||
| df.to_csv('../data_process_cache/output_train.csv', index=False, encoding='UTF-8') | |||||
| def dataProcess3(): | |||||
| df = pd.read_csv('../data_process_cache/output_train.csv', encoding='UTF-8') | |||||
| df.replace({ | |||||
| 'AV:L': 'LOCAL', 'AV:N': 'NETWORK', 'AV:A': 'ADJACENT', 'AV:P': 'PHYSICAL', | |||||
| 'AC:L': 'LOW', 'AC:H': 'HIGH', | |||||
| 'PR:N': 'NONE', 'PR:L': 'LOW', 'PR:H': 'HIGH', | |||||
| 'UI:N': 'NONE', 'UI:R': 'REQUIRED', | |||||
| 'S:U': 'UNCHANGED', 'S:C': 'CHANGED', | |||||
| 'C:N': 'NONE', 'C:L': 'LOW', 'C:H': 'HIGH', | |||||
| 'I:N': 'NONE', 'I:L': 'LOW', 'I:H': 'HIGH', | |||||
| 'A:N': 'NONE', 'A:L': 'LOW', 'A:H': 'HIGH' | |||||
| }, inplace=True) | |||||
| df.to_csv('../dataset/SIR_train_set.csv', index=False, encoding='UTF-8') | |||||
| if __name__ == '__main__': | |||||
| main() | |||||
+ 66
- 0
Models+K-Means/main/jsonToCsv.py
View File
| @@ -0,0 +1,66 @@ | |||||
| import json | |||||
| import csv | |||||
| import pandas as pd | |||||
| import re | |||||
| def main(): | |||||
| jsonToCsv() | |||||
| dataProcess() | |||||
| dataProcess2() | |||||
| dataProcess3() | |||||
| def jsonToCsv(): | |||||
| with open('../data/SIR_validation_set.json', 'r', encoding='UTF-8') as json_file: | |||||
| data = json.load(json_file) | |||||
| with open('../data_process_cache/SIR_validation_set.csv', 'w', newline='', encoding='UTF-8') as csv_file: | |||||
| if data: | |||||
| fieldnames = data[0].keys() | |||||
| writer = csv.DictWriter(csv_file, fieldnames=fieldnames) | |||||
| writer.writeheader() | |||||
| writer.writerows(data) | |||||
| def dataProcess(): | |||||
| columns_to_keep = ['description', 'vectorString'] | |||||
| with open('../data_process_cache/SIR_validation_set.csv', 'r', encoding='UTF-8') as infile: | |||||
| reader = csv.DictReader(infile) | |||||
| filtered_rows = [{col: row[col] for col in columns_to_keep} for row in reader] | |||||
| # 将选择的列写入到新 CSV 文件 | |||||
| with open('../data_process_cache/validation_vecStr.csv', 'w', newline='', encoding='utf-8') as outfile: | |||||
| if filtered_rows: | |||||
| writer = csv.DictWriter(outfile, fieldnames=columns_to_keep) | |||||
| writer.writerows(filtered_rows) # 写入选择的列 | |||||
| def dataProcess2(): | |||||
| import pandas as pd | |||||
| df = pd.read_csv('../data_process_cache/validation_vecStr.csv', header=None, encoding='UTF-8') | |||||
| df_expanded = df[1].str.split('/', expand=True) | |||||
| df = pd.concat([df, df_expanded], axis=1) | |||||
| print(df.head()) | |||||
| df.to_csv('../data_process_cache/output_validation.csv', index=False, header=False, encoding='UTF-8') | |||||
| df = pd.read_csv('../data_process_cache/output_validation.csv', header=None, encoding='UTF-8') | |||||
| df = df.drop(columns=[1, 2]) | |||||
| df.to_csv('../data_process_cache/output_validation.csv',index=False, header=False, encoding='UTF-8') | |||||
| def dataProcess3(): | |||||
| df = pd.read_csv('../data_process_cache/output_validation.csv', header=None, encoding='UTF-8') | |||||
| print(df.head()) | |||||
| df.replace({'AV:L': 'LOCAL', 'AV:N': 'NETWORK', 'AV:A': 'ADJACENT', 'AV:P': 'PHYSICAL'}, inplace=True) | |||||
| df.replace({'AC:L': 'LOW', 'AC:H': 'HIGH'}, inplace=True) | |||||
| df.replace({'PR:N': 'NONE', 'PR:L': 'LOW', 'PR:H': 'HIGH'}, inplace=True) | |||||
| df.replace({'UI:N': 'NONE', 'UI:R': 'REQUIRED'}, inplace=True) | |||||
| df.replace({'S:U': 'UNCHANGED', 'S:C': 'CHANGED'}, inplace=True) | |||||
| df.replace({'C:N': 'NONE', 'C:L': 'LOW', 'C:H': 'HIGH'}, inplace=True) | |||||
| df.replace({'I:N': 'NONE', 'I:L': 'LOW', 'I:H': 'HIGH'}, inplace=True) | |||||
| df.replace({'A:N': 'NONE', 'A:L': 'LOW', 'A:H': 'HIGH'}, inplace=True) | |||||
| df.to_csv('../dataset/SIR_validation_set.csv', index=False, header=False, encoding='UTF-8') | |||||
| if __name__ == '__main__': | |||||
| main() | |||||
+ 56
- 0
Models+K-Means/main/lemmatization.py
View File
| @@ -0,0 +1,56 @@ | |||||
| from nltk.tokenize import word_tokenize | |||||
| from nltk.stem import WordNetLemmatizer | |||||
| from nltk.corpus import wordnet | |||||
| from nltk import pos_tag | |||||
| def get_wordnet_pos(word): | |||||
| """Map POS tag to first character lemmatize() accepts""" | |||||
| tag = pos_tag([word])[0][1][0].upper() | |||||
| tag_dict = {"J": wordnet.ADJ, | |||||
| "N": wordnet.NOUN, | |||||
| "V": wordnet.VERB, | |||||
| "R": wordnet.ADV} | |||||
| return tag_dict.get(tag, wordnet.NOUN) | |||||
| def lemmatize_sentence(sentence): | |||||
| word_list = word_tokenize(sentence) | |||||
| # lemmatized_output = ' '.join([lemmatize_word(w) for w in word_list]) # ALL LEMMATIZATION | |||||
| lemmatized_output = ' '.join([lemmatize_noun(w) for w in word_list]) # NOUN LEMMATIZATION (OLD) | |||||
| return lemmatized_output | |||||
| def lemmatize(train_texts, test_texts=None): | |||||
| ### Lemmatize Sentences | |||||
| lemmatized_texts_train = [] | |||||
| lemmatized_texts_test = [] | |||||
| for text in train_texts: | |||||
| lemmatized_texts_train.append(lemmatize_sentence(text)) | |||||
| if test_texts is not None: | |||||
| for text in test_texts: | |||||
| lemmatized_texts_test.append(lemmatize_sentence(text)) | |||||
| return lemmatized_texts_train, lemmatized_texts_test | |||||
| def lemmatize_word(word): | |||||
| lemmatizer = WordNetLemmatizer() | |||||
| pos_tag = get_wordnet_pos(word) | |||||
| word_lemmatized = lemmatizer.lemmatize(word, pos_tag) | |||||
| if pos_tag == "r" or pos_tag == "R": | |||||
| try: | |||||
| lemmas = wordnet.synset(word+'.r.1').lemmas() | |||||
| pertainyms = lemmas[0].pertainyms() | |||||
| name = pertainyms[0].name() | |||||
| return name | |||||
| except Exception: | |||||
| return word_lemmatized | |||||
| else: | |||||
| return word_lemmatized | |||||
| def lemmatize_noun(word): | |||||
| lemmatizer = WordNetLemmatizer() | |||||
| word_lemmatized = lemmatizer.lemmatize(word) | |||||
| return word_lemmatized | |||||
BIN
Models+K-Means/main/output/cluster.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 640 | Height: 480 | Size: 27 kB |
BIN
Models+K-Means/main/output/heatmap.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 1000 | Height: 1000 | Size: 112 kB |
+ 0
- 0
Models+K-Means/main/output/output1.csv
View File
+ 6331
- 0
Models+K-Means/main/output/output1_bert_nvd.csv
File diff suppressed because it is too large
View File
+ 6331
- 0
Models+K-Means/main/output/output1_distilbert_nvd.csv
File diff suppressed because it is too large
View File
+ 15962
- 0
Models+K-Means/main/output/output1_last.csv
File diff suppressed because it is too large
View File
+ 6331
- 0
Models+K-Means/main/output/output_albert.csv
File diff suppressed because it is too large
View File
+ 6331
- 0
Models+K-Means/main/output/roberta.csv
File diff suppressed because it is too large
View File
+ 20
- 0
Models+K-Means/main/remove_stop_words.py
View File
| @@ -0,0 +1,20 @@ | |||||
| from nltk.corpus import stopwords | |||||
| from nltk.tokenize import word_tokenize | |||||
| def remove_stop_words_from_sentence(sentence): | |||||
| stop_words = set(stopwords.words('english')) | |||||
| word_tokens = word_tokenize(sentence) | |||||
| filtered_ouput = ' '.join([w for w in word_tokens if not w in stop_words]) | |||||
| return filtered_ouput | |||||
| def remove_stop_words(train_texts, test_texts=None): | |||||
| ### Remove stop words from sentences | |||||
| filtered_texts_train = [] | |||||
| filtered_texts_test = [] | |||||
| for text in train_texts: | |||||
| filtered_texts_train.append(remove_stop_words_from_sentence(text)) | |||||
| if test_texts is not None: | |||||
| for text in test_texts: | |||||
| filtered_texts_test.append(remove_stop_words_from_sentence(text)) | |||||
| return filtered_texts_train, filtered_texts_test | |||||
BIN
Models+K-Means/main/requirements.txt
View File
+ 20
- 0
Models+K-Means/main/stemmatization.py
View File
| @@ -0,0 +1,20 @@ | |||||
| from nltk.tokenize import word_tokenize | |||||
| from nltk.stem import PorterStemmer | |||||
| def stemmatize_sentence(sentence): | |||||
| stemmer = PorterStemmer() | |||||
| word_list = word_tokenize(sentence) | |||||
| stemmatized_ouput = ' '.join([stemmer.stem(w) for w in word_list]) | |||||
| return stemmatized_ouput | |||||
| def stemmatize(train_texts, test_texts=None): | |||||
| ### Stemmatize Sentences | |||||
| stemmatized_texts_train = [] | |||||
| stemmatized_texts_test = [] | |||||
| for text in train_texts: | |||||
| stemmatized_texts_train.append(stemmatize_sentence(text)) | |||||
| if test_texts is not None: | |||||
| for text in test_texts: | |||||
| stemmatized_texts_test.append(stemmatize_sentence(text)) | |||||
| return stemmatized_texts_train, stemmatized_texts_test | |||||
+ 11
- 0
Models+K-Means/main/tagRemove.py
View File
| @@ -0,0 +1,11 @@ | |||||
| import pandas as pd | |||||
| df = pd.read_csv('../dataset/final_train_data.csv', header=None) | |||||
| print(df.head(10)) | |||||
| df.replace(r'\b\w+TAG\b', '', regex=True, inplace=True) | |||||
| print(df.head(10)) | |||||
| df.to_csv('../dataset/final_train_data.csv', index=False, header=None) | |||||
+ 291
- 0
Models+K-Means/main/test.py
View File
| @@ -0,0 +1,291 @@ | |||||
| import csv | |||||
| from pathlib import Path | |||||
| import safetensors.torch | |||||
| from nltk import tokenize | |||||
| from sklearn.model_selection import train_test_split | |||||
| from safetensors.torch import load | |||||
| import torch | |||||
| from torch.utils.data import DataLoader | |||||
| from tqdm import tqdm | |||||
| from CVSSDataset import CVSSDataset, read_cvss_csv, read_cvss_txt | |||||
| import numpy as np | |||||
| import argparse | |||||
| from sklearn.metrics import f1_score, precision_score, recall_score, balanced_accuracy_score, accuracy_score | |||||
| from lemmatization import lemmatize, lemmatize_noun | |||||
| from remove_stop_words import remove_stop_words | |||||
| from stemmatization import stemmatize | |||||
| import pandas as pd | |||||
| # -------------------------------------- MODEL ------------------------------------- | |||||
| def load_model(model_path, model): | |||||
| with open(model_path, "rb") as f: | |||||
| data = f.read() | |||||
| loaded = load(data) | |||||
| model.load_state_dict(loaded) | |||||
| return model | |||||
| def select_tokenizer_model(model_name, extra_tokens, token_file, model_path, config_path): | |||||
| global lemmatization | |||||
| if model_name == 'distilbert': | |||||
| from transformers import DistilBertTokenizerFast, DistilBertForSequenceClassification, DistilBertConfig | |||||
| config = DistilBertConfig.from_pretrained(config_path) | |||||
| tokenizer = DistilBertTokenizerFast.from_pretrained('distilbert-base-cased') | |||||
| model = DistilBertForSequenceClassification(config) | |||||
| elif model_name == 'bert': | |||||
| from transformers import BertTokenizerFast, BertForSequenceClassification, BertConfig | |||||
| config = BertConfig.from_pretrained(config_path) | |||||
| tokenizer = BertTokenizerFast.from_pretrained('bert-base-uncased') | |||||
| model = BertForSequenceClassification(config) | |||||
| elif model_name == 'deberta': | |||||
| from transformers import DebertaConfig, DebertaTokenizerFast, DebertaForSequenceClassification | |||||
| config = DebertaConfig.from_pretrained(config_path) | |||||
| tokenizer = DebertaTokenizerFast.from_pretrained('microsoft/deberta-base') | |||||
| model = DebertaForSequenceClassification(config) | |||||
| elif model_name == 'albert': | |||||
| from transformers import AlbertConfig, AlbertTokenizerFast, AlbertForSequenceClassification | |||||
| config = AlbertConfig.from_pretrained(config_path) | |||||
| tokenizer = AlbertTokenizerFast.from_pretrained('albert-base-v1') | |||||
| model = AlbertForSequenceClassification(config) | |||||
| elif model_name == 'roberta': | |||||
| from transformers import RobertaConfig, RobertaTokenizerFast, RobertaForSequenceClassification | |||||
| config = RobertaConfig.from_pretrained(config_path) | |||||
| tokenizer = RobertaTokenizerFast.from_pretrained('roberta-base') | |||||
| model = RobertaForSequenceClassification(config) | |||||
| elif model_name == 'Llama': | |||||
| from transformers import LlamaConfig, LlamaTokenizerFast, LlamaForSequenceClassification | |||||
| config = LlamaConfig.from_pretrained(config_path) | |||||
| tokenizer = LlamaTokenizerFast.from_pretrained('meta-llama/Prompt-Guard-86M') | |||||
| model = LlamaForSequenceClassification(config) | |||||
| ### Add Tokens | |||||
| if extra_tokens: | |||||
| add_tokens_from_file(token_file, tokenizer, lemmatization) | |||||
| number_tokens = len(tokenizer) | |||||
| print("### Number of tokens in Tokenizer: " + str(number_tokens)) | |||||
| model.resize_token_embeddings(number_tokens) | |||||
| return tokenizer, model | |||||
| def add_tokens_from_file(token_file, tokenizer, lemmatize=False): | |||||
| print("### Adding Tokens") | |||||
| file_ = open(token_file, 'r', encoding='UTF-8') | |||||
| token_list = [] | |||||
| for line in file_: | |||||
| if lemmatize: | |||||
| token_list.append(lemmatize_noun(line.rstrip("\n"))) | |||||
| else: | |||||
| token_list.append(line.rstrip("\n")) | |||||
| file_.close() | |||||
| tokenizer.add_tokens(token_list) | |||||
| # -------------------------------------- METRICS ----------------------------------- | |||||
| def get_pred_accuracy(target, output): | |||||
| output = output.argmax(axis=1) # -> multi label | |||||
| tot_right = np.sum(target == output) | |||||
| tot = target.size | |||||
| return (tot_right / tot) * 100 | |||||
| def get_accuracy_score(target, output): | |||||
| return accuracy_score(target, output) | |||||
| def get_f1_score(target, output): | |||||
| return f1_score(target, output, average='weighted') | |||||
| def get_precision_score(target, output): | |||||
| return precision_score(target, output, average='weighted') | |||||
| def get_recall_score(target, output): | |||||
| return recall_score(target, output, average='weighted') | |||||
| def get_mean_accuracy(target, output): | |||||
| eps = 1e-20 | |||||
| output = output.argmax(axis=1) | |||||
| # TP + FN | |||||
| gt_pos = np.sum((target == 1), axis=0).astype(float) | |||||
| # TN + FP | |||||
| gt_neg = np.sum((target == 0), axis=0).astype(float) | |||||
| # TP | |||||
| true_pos = np.sum((target == 1) * (output == 1), axis=0).astype(float) | |||||
| # TN | |||||
| true_neg = np.sum((target == 0) * (output == 0), axis=0).astype(float) | |||||
| label_pos_recall = 1.0 * true_pos / (gt_pos + eps) # true positive | |||||
| label_neg_recall = 1.0 * true_neg / (gt_neg + eps) # true negative | |||||
| # mean accuracy | |||||
| return (label_pos_recall + label_neg_recall) / 2 | |||||
| def get_balanced_accuracy(target, output): | |||||
| return balanced_accuracy_score(target, output) | |||||
| def disLabel(classNames, pred_props, labelPosition): | |||||
| data = [] | |||||
| for i in pred_props: | |||||
| data.append(classNames[i]) | |||||
| file_name = "../data_process_cache/output.csv" | |||||
| with open(file_name, mode='w', newline='') as file: | |||||
| writer = csv.writer(file) | |||||
| writer.writerows([data]) | |||||
| df = pd.read_csv('../data_process_cache/output.csv', header=None) | |||||
| if labelPosition > 1: | |||||
| df_exist = pd.read_csv('output/output1_last.csv', header=None) | |||||
| # print(df_exist.head(10)) | |||||
| df_exist_transposed = df_exist.T | |||||
| # print(df_exist_transposed.head(10)) | |||||
| df_combined = pd.concat([df_exist_transposed, df], ignore_index=True) | |||||
| df_combined = df_combined.T | |||||
| df_combined.to_csv('output/output1_last.csv', index=False, header=False) | |||||
| else: | |||||
| df_transposed = df.T | |||||
| df_transposed.to_csv('output/output1_last.csv', index=False, header=False) | |||||
| return | |||||
| # -------------------------------------- MAIN ----------------------------------- | |||||
| def main(): | |||||
| global lemmatization | |||||
| parser = argparse.ArgumentParser() | |||||
| parser.add_argument('--classes_names', type=str, required=True, help='Names used to distinguish class values') | |||||
| parser.add_argument('--label_position', type=int, required=True, help='The label position in CSV file') | |||||
| parser.add_argument('--root_dir', type=str, required=True, help='Path to model and config files') | |||||
| parser.add_argument('--model', type=str, help='The name of the model to use') | |||||
| parser.add_argument('--test_batch', type=int, help='Batch size for test') | |||||
| parser.add_argument('--extra_tokens', type=int, help='Extra tokens') | |||||
| parser.add_argument('--lemmatization', type=int, help='Lemmatization') | |||||
| parser.add_argument('--stemming', type=int, help='Stemming') | |||||
| parser.add_argument('--rem_stop_words', type=int, help='Remove Stop Words') | |||||
| parser.add_argument('--token_file', type=str, help='Tokens file') | |||||
| args = parser.parse_args() | |||||
| string = args.classes_names | |||||
| classNames = string.split(',') | |||||
| labelPosition = args.label_position | |||||
| print(classNames) | |||||
| model_name = args.model if args.model else 'distilbert' | |||||
| extra_tokens = bool(args.extra_tokens) if args.extra_tokens else False | |||||
| token_file = args.token_file | |||||
| lemmatization = bool(args.lemmatization) if args.lemmatization else False | |||||
| stemming = bool(args.stemming) if args.stemming else False | |||||
| rem_stop_words = bool(args.rem_stop_words) if args.rem_stop_words else False | |||||
| root_dir = args.root_dir | |||||
| model_path = root_dir + 'model.safetensors' | |||||
| config_path = root_dir + 'config.json' | |||||
| batch_size = args.test_batch if args.test_batch else 2 | |||||
| list_classes = args.classes_names.rsplit(",") | |||||
| label_position = args.label_position | |||||
| print("### modelName: " + model_name) | |||||
| # device = torch.device('cpu') | |||||
| device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu') | |||||
| print("### Device: ", device) | |||||
| ### Select Model | |||||
| tokenizer, model = select_tokenizer_model(model_name, extra_tokens, token_file, model_path, config_path) | |||||
| ### Load Dataset | |||||
| print("### Loading Dataset") | |||||
| test_texts, test_labels = read_cvss_csv(r'E:\pythonProject_open\dataset_more\test.csv', label_position, list_classes) | |||||
| ### Lemmatize Sentences | |||||
| if lemmatization: | |||||
| print("### Lemmatizing Sentences") | |||||
| lemmatized_test, _ = lemmatize(test_texts) | |||||
| if stemming: | |||||
| print("### Stemmatize Sentences") | |||||
| stemmatized_test, _ = stemmatize(test_texts) | |||||
| if rem_stop_words: | |||||
| print("### Remove Stop Words from Sentences") | |||||
| filtered_test, _ = remove_stop_words(test_texts) | |||||
| ### Tokenize Sentences | |||||
| print("### Tokenizing Sentences") | |||||
| if lemmatization: | |||||
| test_encodings = tokenizer(lemmatized_test, truncation=True, padding=True) | |||||
| elif stemming: | |||||
| test_encodings = tokenizer(stemmatized_test, truncation=True, padding=True) | |||||
| elif rem_stop_words: | |||||
| test_encodings = tokenizer(filtered_test, truncation=True, padding=True) | |||||
| else: | |||||
| test_encodings = tokenizer(test_texts, truncation=True, padding=True) | |||||
| ### Dataset Encodings | |||||
| test_dataset = CVSSDataset(test_encodings, test_labels) | |||||
| print("### Dataset Encodings") | |||||
| model = load_model(model_path, model) | |||||
| model.to(device) | |||||
| test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False) | |||||
| model.eval() | |||||
| pred_probs = [] | |||||
| gt_list = [] | |||||
| for batch in tqdm(test_loader): | |||||
| input_ids = batch['input_ids'].to(device) | |||||
| attention_mask = batch['attention_mask'].to(device) | |||||
| labels = batch['labels'].to(device) | |||||
| outputs = model(input_ids, attention_mask=attention_mask, labels=labels) | |||||
| soft = torch.nn.Softmax(dim=1) | |||||
| output_logits = soft(outputs.logits) | |||||
| gt_list.append(labels.cpu().detach().numpy()) | |||||
| pred_probs.append(output_logits.cpu().detach().numpy()) | |||||
| # print(pred_probs) # 0001001000 | |||||
| gt_list = np.concatenate(gt_list, axis=0) | |||||
| pred_probs = np.concatenate(pred_probs, axis=0) | |||||
| pred_probs = pred_probs.argmax(axis=1) | |||||
| # print(pred_probs) | |||||
| disLabel(classNames, pred_probs,labelPosition) | |||||
| print( | |||||
| "Accuracy = {:.6f} F1-score = {:.6f} Precision = {:.6f} Recall = {:.6f} mean Accuracy = {:.6f}".format( | |||||
| get_accuracy_score(gt_list, pred_probs), get_f1_score(gt_list, pred_probs), | |||||
| get_precision_score(gt_list, pred_probs), get_recall_score(gt_list, pred_probs), | |||||
| balanced_accuracy_score(gt_list, pred_probs))) | |||||
| if __name__ == '__main__': | |||||
| main() | |||||
+ 19
- 0
Models+K-Means/main/test.sh
View File
| @@ -0,0 +1,19 @@ | |||||
| ROOTDIR=output/ | |||||
| MODELO=distilbert | |||||
| LEMMATIZATION=0 | |||||
| EXTRAVOCAB=0 | |||||
| REMOVESTOPWORDS=0 | |||||
| STEM=1 | |||||
| python test.py --classes_names NETWORK,LOCAL,PHYSICAL,ADJACENT --label_position 1 --root_dir ${ROOTDIR}attackVector/ --model ${MODELO} --lemmatization ${LEMMATIZATION} --rem_stop_words ${REMOVESTOPWORDS} --stemming ${STEM} --extra_tokens ${EXTRAVOCAB} | |||||
| python test.py --classes_names LOW,HIGH --label_position 2 --root_dir ${ROOTDIR}attackComplexity/ --model ${MODELO} --lemmatization ${LEMMATIZATION} --rem_stop_words ${REMOVESTOPWORDS} --stemming ${STEM} --extra_tokens ${EXTRAVOCAB} | |||||
| python test.py --classes_names NONE,LOW,HIGH --label_position 3 --root_dir ${ROOTDIR}privilegeReq/ --model ${MODELO} --lemmatization ${LEMMATIZATION} --rem_stop_words ${REMOVESTOPWORDS} --stemming ${STEM} --extra_tokens ${EXTRAVOCAB} | |||||
| python test.py --classes_names NONE,REQUIRED --label_position 4 --root_dir ${ROOTDIR}userInteraction/ --model ${MODELO} --lemmatization ${LEMMATIZATION} --rem_stop_words ${REMOVESTOPWORDS} --stemming ${STEM} --extra_tokens ${EXTRAVOCAB} | |||||
| python test.py --classes_names UNCHANGED,CHANGED --label_position 5 --root_dir ${ROOTDIR}scope/ --model ${MODELO} --lemmatization ${LEMMATIZATION} --rem_stop_words ${REMOVESTOPWORDS} --stemming ${STEM} --extra_tokens ${EXTRAVOCAB} | |||||
| python test.py --classes_names NONE,LOW,HIGH --label_position 6 --root_dir ${ROOTDIR}confidentiality/ --model ${MODELO} --lemmatization ${LEMMATIZATION} --rem_stop_words ${REMOVESTOPWORDS} --stemming ${STEM} --extra_tokens ${EXTRAVOCAB} | |||||
| python test.py --classes_names NONE,LOW,HIGH --label_position 7 --root_dir ${ROOTDIR}Integrity/ --model ${MODELO} --lemmatization ${LEMMATIZATION} --rem_stop_words ${REMOVESTOPWORDS} --stemming ${STEM} --extra_tokens ${EXTRAVOCAB} | |||||
| python test.py --classes_names NONE,LOW,HIGH --label_position 8 --root_dir ${ROOTDIR}availability/ --model ${MODELO} --lemmatization ${LEMMATIZATION} --rem_stop_words ${REMOVESTOPWORDS} --stemming ${STEM} --extra_tokens ${EXTRAVOCAB} | |||||
| echo press any | |||||
| read -n 1 | |||||
| echo 继续运行 | |||||
+ 2
- 0
Models+K-Means/main/test_sh.py
View File
| @@ -0,0 +1,2 @@ | |||||
| import os | |||||
| os.system("train.sh") | |||||
+ 269
- 0
Models+K-Means/main/train.py
View File
| @@ -0,0 +1,269 @@ | |||||
| from transformers import Trainer, TrainingArguments, AdamW | |||||
| from transformers.optimization import get_linear_schedule_with_warmup | |||||
| from pathlib import Path | |||||
| import torch | |||||
| import nltk | |||||
| from torch.optim import Adam, lr_scheduler | |||||
| from torch.utils.data import DataLoader | |||||
| from tqdm import tqdm | |||||
| from CVSSDataset import CVSSDataset, read_cvss_csv | |||||
| from lemmatization import lemmatize, lemmatize_word, lemmatize_noun | |||||
| from remove_stop_words import remove_stop_words | |||||
| from stemmatization import stemmatize | |||||
| import numpy as np | |||||
| import argparse | |||||
| import os | |||||
| def select_tokenizer_model(model_name, extra_tokens, token_file, num_labels): | |||||
| global lemmatization | |||||
| print("### Selecting Model and Tokenizer") | |||||
| if model_name == 'distilbert': | |||||
| from transformers import DistilBertTokenizerFast, DistilBertForSequenceClassification, DistilBertConfig | |||||
| config = DistilBertConfig.from_pretrained('distilbert-base-cased') | |||||
| tokenizer = DistilBertTokenizerFast.from_pretrained('distilbert-base-cased') | |||||
| model = DistilBertForSequenceClassification(config) | |||||
| elif model_name == 'bert': | |||||
| from transformers import BertTokenizerFast, BertForSequenceClassification, BertConfig | |||||
| config = BertConfig.from_pretrained('bert-base-uncased') | |||||
| tokenizer = BertTokenizerFast.from_pretrained('bert-base-uncased') | |||||
| model = BertForSequenceClassification(config) | |||||
| elif model_name == 'deberta': | |||||
| from transformers import DebertaConfig, DebertaTokenizerFast, DebertaForSequenceClassification | |||||
| config = DebertaConfig.from_pretrained('microsoft/deberta-base') | |||||
| tokenizer = DebertaTokenizerFast.from_pretrained('microsoft/deberta-base') | |||||
| model = DebertaForSequenceClassification(config) | |||||
| elif model_name == 'albert': | |||||
| from transformers import AlbertConfig, AlbertTokenizerFast, AlbertForSequenceClassification | |||||
| config = AlbertConfig.from_pretrained('albert-base-v1') | |||||
| tokenizer = AlbertTokenizerFast.from_pretrained('albert-base-v1') | |||||
| model = AlbertForSequenceClassification(config) | |||||
| elif model_name == 'roberta': | |||||
| from transformers import RobertaConfig, RobertaTokenizerFast, RobertaForSequenceClassification | |||||
| config = RobertaConfig.from_pretrained('roberta-base') | |||||
| tokenizer = RobertaTokenizerFast.from_pretrained('roberta-base') | |||||
| model = RobertaForSequenceClassification(config) | |||||
| ### Add Tokens | |||||
| if extra_tokens: | |||||
| add_tokens_from_file(token_file, tokenizer, lemmatization) | |||||
| number_tokens = len(tokenizer) | |||||
| print("### Number of tokens in Tokenizer") | |||||
| print(number_tokens) | |||||
| # print("### Configuration") | |||||
| # print(model.config) | |||||
| model.resize_token_embeddings(number_tokens) | |||||
| return tokenizer, model | |||||
| def add_tokens_from_file(token_file, tokenizer, lemmatize=False): | |||||
| print("### Adding Tokens") | |||||
| file_ = open(token_file, 'r', encoding='UTF-8') | |||||
| token_list = [] | |||||
| for line in file_: | |||||
| if lemmatize: | |||||
| token_list.append(lemmatize_noun(line.rstrip("\n"))) | |||||
| else: | |||||
| token_list.append(line.rstrip("\n")) | |||||
| file_.close() | |||||
| tokenizer.add_tokens(token_list) | |||||
| def get_pred_accuracy(target, output): | |||||
| output = output.argmax(axis=1) # -> multi label | |||||
| tot_right = np.sum(target == output) | |||||
| tot = target.size | |||||
| return (tot_right/tot) * 100 | |||||
| def get_binary_mean_accuracy(target, output): | |||||
| eps = 1e-20 | |||||
| output = output.argmax(axis=1) | |||||
| # TP + FN | |||||
| gt_pos = np.sum((target == 1), axis=0).astype(float) | |||||
| # TN + FP | |||||
| gt_neg = np.sum((target == 0), axis=0).astype(float) | |||||
| # TP | |||||
| true_pos = np.sum((target == 1) * (output == 1), axis=0).astype(float) | |||||
| # TN | |||||
| true_neg = np.sum((target == 0) * (output == 0), axis=0).astype(float) | |||||
| label_pos_recall = 1.0 * true_pos / (gt_pos + eps) # true positive | |||||
| label_neg_recall = 1.0 * true_neg / (gt_neg + eps) # true negative | |||||
| # mean accuracy | |||||
| return (label_pos_recall + label_neg_recall) / 2 | |||||
| def get_evaluation_metrics(target, output, num_labels): | |||||
| accuracy = get_pred_accuracy(target, output, num_labels) | |||||
| return accuracy | |||||
| def infer(trainer, test_loader, num_labels): | |||||
| predicts = trainer.predict(test_loader) | |||||
| soft = torch.nn.Softmax(dim=1) | |||||
| pred_probs = torch.from_numpy(predicts.predictions) | |||||
| pred_probs = soft(pred_probs).numpy() | |||||
| gt_list = predicts.label_ids | |||||
| return get_pred_accuracy(gt_list, pred_probs) | |||||
| def main(): | |||||
| # nltk.download('stopwords') | |||||
| # nltk.download('punkt_tab') | |||||
| global lemmatization | |||||
| parser = argparse.ArgumentParser() | |||||
| parser.add_argument('--num_labels', type=int, required=True, default=2, help='Number of classes in 1 label') | |||||
| parser.add_argument('--classes_names', type=str, required=True, help='Names used to distinguish class values') | |||||
| parser.add_argument('--label_position', type=int, required=True, help='The label position in CSV file') | |||||
| parser.add_argument('--output_dir', type=str, required=True) | |||||
| parser.add_argument('--model', type=str, help='The name of the model to use') | |||||
| parser.add_argument('--train_batch', type=int, help='Batch size for training') | |||||
| parser.add_argument('--epochs', type=int, help='Epochs for training') | |||||
| parser.add_argument('--lr', type=float, help='Learning rate for training') | |||||
| parser.add_argument('--weight_decay', type=float, help='Weight decay for training') | |||||
| parser.add_argument('--warmup_steps', type=int, help='Warmup steps for training') | |||||
| parser.add_argument('--warmup_ratio', type=float, help='Warmup ratio for training') | |||||
| parser.add_argument('--extra_tokens', type=int, help='Extra tokens') | |||||
| parser.add_argument('--lemmatization', type=int, help='Lemmatization') | |||||
| parser.add_argument('--stemming', type=int, help='Stemming') | |||||
| parser.add_argument('--rem_stop_words', type=int, help='Remove Stop Words') | |||||
| parser.add_argument('--token_file', type=str, help='Tokens file') | |||||
| args = parser.parse_args() | |||||
| extra_tokens = bool(args.extra_tokens) if args.extra_tokens else False | |||||
| token_file = args.token_file | |||||
| lemmatization = bool(args.lemmatization) if args.lemmatization else False | |||||
| stemming = bool(args.stemming) if args.stemming else False | |||||
| rem_stop_words = bool(args.rem_stop_words) if args.rem_stop_words else False | |||||
| # Automatic | |||||
| list_classes = args.classes_names.rsplit(",") | |||||
| label_position = args.label_position | |||||
| output_dir = args.output_dir | |||||
| model_name = args.model if args.model else 'distilbert' | |||||
| print("### modelName: "+model_name) | |||||
| num_labels = args.num_labels | |||||
| train_batch_size = args.train_batch if args.train_batch else 8 | |||||
| test_batch_size = 4 | |||||
| epochs = args.epochs if args.epochs else 4 | |||||
| learning_rate = args.lr if args.lr else 5e-5 | |||||
| weight_decay = args.weight_decay if args.weight_decay else 0 | |||||
| warmup_steps = args.warmup_steps if args.warmup_steps else 0 | |||||
| warmup_ratio = args.warmup_ratio if args.warmup_ratio else 0 | |||||
| device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu') | |||||
| print("### Device: ", device) | |||||
| os.makedirs(output_dir, exist_ok=True) | |||||
| ### Select Model | |||||
| tokenizer, model = select_tokenizer_model(model_name, extra_tokens, token_file, num_labels) | |||||
| ### Split Dataset | |||||
| print("### Splitting Dataset") | |||||
| train_texts, train_labels = read_cvss_csv(r'../dataset/SIR_train_set.csv', label_position, list_classes) | |||||
| test_texts, test_labels = read_cvss_csv(r'../dataset/SIR_test_set.csv', label_position, list_classes) | |||||
| ### Remove Stop Words from Sentences | |||||
| if rem_stop_words: | |||||
| print("### Remove Stop Words from Sentences") | |||||
| filtered_train, filtered_test = remove_stop_words(train_texts, test_texts) | |||||
| ### Lemmatize Sentences | |||||
| if lemmatization: | |||||
| print("### Lemmatizing Sentences") | |||||
| if rem_stop_words: | |||||
| lemmatized_train, lemmatized_test = lemmatize(filtered_train, filtered_test) | |||||
| else: | |||||
| lemmatized_train, lemmatized_test = lemmatize(train_texts, test_texts) | |||||
| ### Stemmatize Sentences | |||||
| if stemming: | |||||
| print("### Stemmatize Sentences") | |||||
| stemmatized_train, stemmatized_test = stemmatize(train_texts, test_texts) | |||||
| ### Tokenize Sentences | |||||
| print("### Tokenizing Sentences") | |||||
| if lemmatization: | |||||
| train_encodings = tokenizer(lemmatized_train, truncation=True, padding=True) # truncate to the model max length and pad all sentences to the same size | |||||
| test_encodings = tokenizer(lemmatized_test, truncation=True, padding=True) | |||||
| elif rem_stop_words: | |||||
| train_encodings = tokenizer(filtered_train, truncation=True, padding=True) # truncate to the model max length and pad all sentences to the same size | |||||
| test_encodings = tokenizer(filtered_test, truncation=True, padding=True) | |||||
| elif stemming: | |||||
| train_encodings = tokenizer(stemmatized_train, truncation=True, padding=True) # truncate to the model max length and pad all sentences to the same size | |||||
| test_encodings = tokenizer(stemmatized_test, truncation=True, padding=True) | |||||
| else: | |||||
| train_encodings = tokenizer(train_texts, truncation=True, padding=True) # truncate to the model max length and pad all sentences to the same size | |||||
| test_encodings = tokenizer(test_texts, truncation=True, padding=True) | |||||
| ### Dataset Encodings | |||||
| print("### Encoding Dataset") | |||||
| train_dataset = CVSSDataset(train_encodings, train_labels) | |||||
| test_dataset = CVSSDataset(test_encodings, test_labels) | |||||
| optimizer = torch.optim.Adam(model.parameters(), learning_rate) | |||||
| scheduler = lr_scheduler.OneCycleLR( | |||||
| optimizer, | |||||
| max_lr=learning_rate, | |||||
| epochs=epochs, | |||||
| steps_per_epoch=len(train_dataset) | |||||
| ) | |||||
| print("### Training") | |||||
| training_args = TrainingArguments( | |||||
| output_dir=output_dir, # output directory | |||||
| num_train_epochs=epochs, # total # of training epochs | |||||
| per_device_train_batch_size=train_batch_size, # batch size per device during training‘ | |||||
| per_device_eval_batch_size=test_batch_size, # batch size for evaluation | |||||
| learning_rate=learning_rate, # learning rate | |||||
| save_strategy="epoch", | |||||
| weight_decay=weight_decay, | |||||
| warmup_steps=warmup_steps, | |||||
| warmup_ratio=warmup_ratio, | |||||
| ) | |||||
| trainer = Trainer( | |||||
| model=model, # the instantiated 🤗 Transformers model to be trained | |||||
| args=training_args, # training arguments, defined above | |||||
| train_dataset=train_dataset, # training dataset | |||||
| eval_dataset=test_dataset, # evaluation dataset | |||||
| optimizers=(optimizer,scheduler), # optimizer and scheduler | |||||
| ) | |||||
| trainer.train() | |||||
| print(len(train_dataset)) | |||||
| trainer.save_model() | |||||
| acc = infer(trainer, test_dataset, num_labels) | |||||
| print("Accuracy = {:.6f}".format(acc)) | |||||
| if __name__ == '__main__': | |||||
| main() | |||||
+ 14
- 0
Models+K-Means/main/train.sh
View File
| @@ -0,0 +1,14 @@ | |||||
| LEMMA=0 | |||||
| EXTRAVOCAB=0 | |||||
| REMOVESTOPWORDS=0 | |||||
| STEM=0 | |||||
| MODELO=distilbert | |||||
| python train.py --num_labels 4 --classes_names NETWORK,LOCAL,PHYSICAL,ADJACENT --label_position 1 --output_dir ../output/attackVector --rem_stop_words ${REMOVESTOPWORDS} --lemmatization ${LEMMA} --stemming ${STEM} --extra_tokens ${EXTRAVOCAB} | |||||
| python train.py --num_labels 2 --classes_names LOW,HIGH --label_position 2 --output_dir ../output/attackComplexity --rem_stop_words ${REMOVESTOPWORDS} --lemmatization ${LEMMA} --stemming ${STEM} --extra_tokens ${EXTRAVOCAB} | |||||
| python train.py --num_labels 3 --classes_names NONE,LOW,HIGH --label_position 3 --output_dir ../output/privilegeReq --rem_stop_words ${REMOVESTOPWORDS} --lemmatization ${LEMMA} --stemming ${STEM} --extra_tokens ${EXTRAVOCAB} | |||||
| python train.py --num_labels 2 --classes_names NONE,REQUIRED --label_position 4 --output_dir ../output/userInteraction --rem_stop_words ${REMOVESTOPWORDS} --lemmatization ${LEMMA} --stemming ${STEM} --extra_tokens ${EXTRAVOCAB} | |||||
| python train.py --num_labels 2 --classes_names UNCHANGED,CHANGED --label_position 5 --output_dir ../output/scope --rem_stop_words ${REMOVESTOPWORDS} --lemmatization ${LEMMA} --stemming ${STEM} --extra_tokens ${EXTRAVOCAB} | |||||
| python train.py --num_labels 3 --classes_names NONE,LOW,HIGH --label_position 6 --output_dir ../output/confidentiality --rem_stop_words ${REMOVESTOPWORDS} --lemmatization ${LEMMA} --stemming ${STEM} --extra_tokens ${EXTRAVOCAB} | |||||
| python train.py --num_labels 3 --classes_names NONE,LOW,HIGH --label_position 7 --output_dir ../output/integrity --rem_stop_words ${REMOVESTOPWORDS} --lemmatization ${LEMMA} --stemming ${STEM} --extra_tokens ${EXTRAVOCAB} | |||||
| python train.py --num_labels 3 --classes_names NONE,LOW,HIGH --label_position 8 --output_dir ../output/availability --rem_stop_words ${REMOVESTOPWORDS} --lemmatization ${LEMMA} --stemming ${STEM} --extra_tokens ${EXTRAVOCAB} | |||||
BIN
Models+K-Means/nltk_data/corpora/stopwords.zip
View File
+ 32
- 0
Models+K-Means/nltk_data/corpora/stopwords/README
View File
| @@ -0,0 +1,32 @@ | |||||
| Stopwords Corpus | |||||
| This corpus contains lists of stop words for several languages. These | |||||
| are high-frequency grammatical words which are usually ignored in text | |||||
| retrieval applications. | |||||
| They were obtained from: | |||||
| http://anoncvs.postgresql.org/cvsweb.cgi/pgsql/src/backend/snowball/stopwords/ | |||||
| The stop words for the Romanian language were obtained from: | |||||
| http://arlc.ro/resources/ | |||||
| The English list has been augmented | |||||
| https://github.com/nltk/nltk_data/issues/22 | |||||
| The German list has been corrected | |||||
| https://github.com/nltk/nltk_data/pull/49 | |||||
| A Kazakh list has been added | |||||
| https://github.com/nltk/nltk_data/pull/52 | |||||
| A Nepali list has been added | |||||
| https://github.com/nltk/nltk_data/pull/83 | |||||
| An Azerbaijani list has been added | |||||
| https://github.com/nltk/nltk_data/pull/100 | |||||
| A Greek list has been added | |||||
| https://github.com/nltk/nltk_data/pull/103 | |||||
| An Indonesian list has been added | |||||
| https://github.com/nltk/nltk_data/pull/112 | |||||
+ 754
- 0
Models+K-Means/nltk_data/corpora/stopwords/arabic
View File
| @@ -0,0 +1,754 @@ | |||||
| إذ | |||||
| إذا | |||||
| إذما | |||||
| إذن | |||||
| أف | |||||
| أقل | |||||
| أكثر | |||||
| ألا | |||||
| إلا | |||||
| التي | |||||
| الذي | |||||
| الذين | |||||
| اللاتي | |||||
| اللائي | |||||
| اللتان | |||||
| اللتيا | |||||
| اللتين | |||||
| اللذان | |||||
| اللذين | |||||
| اللواتي | |||||
| إلى | |||||
| إليك | |||||
| إليكم | |||||
| إليكما | |||||
| إليكن | |||||
| أم | |||||
| أما | |||||
| أما | |||||
| إما | |||||
| أن | |||||
| إن | |||||
| إنا | |||||
| أنا | |||||
| أنت | |||||
| أنتم | |||||
| أنتما | |||||
| أنتن | |||||
| إنما | |||||
| إنه | |||||
| أنى | |||||
| أنى | |||||
| آه | |||||
| آها | |||||
| أو | |||||
| أولاء | |||||
| أولئك | |||||
| أوه | |||||
| آي | |||||
| أي | |||||
| أيها | |||||
| إي | |||||
| أين | |||||
| أين | |||||
| أينما | |||||
| إيه | |||||
| بخ | |||||
| بس | |||||
| بعد | |||||
| بعض | |||||
| بك | |||||
| بكم | |||||
| بكم | |||||
| بكما | |||||
| بكن | |||||
| بل | |||||
| بلى | |||||
| بما | |||||
| بماذا | |||||
| بمن | |||||
| بنا | |||||
| به | |||||
| بها | |||||
| بهم | |||||
| بهما | |||||
| بهن | |||||
| بي | |||||
| بين | |||||
| بيد | |||||
| تلك | |||||
| تلكم | |||||
| تلكما | |||||
| ته | |||||
| تي | |||||
| تين | |||||
| تينك | |||||
| ثم | |||||
| ثمة | |||||
| حاشا | |||||
| حبذا | |||||
| حتى | |||||
| حيث | |||||
| حيثما | |||||
| حين | |||||
| خلا | |||||
| دون | |||||
| ذا | |||||
| ذات | |||||
| ذاك | |||||
| ذان | |||||
| ذانك | |||||
| ذلك | |||||
| ذلكم | |||||
| ذلكما | |||||
| ذلكن | |||||
| ذه | |||||
| ذو | |||||
| ذوا | |||||
| ذواتا | |||||
| ذواتي | |||||
| ذي | |||||
| ذين | |||||
| ذينك | |||||
| ريث | |||||
| سوف | |||||
| سوى | |||||
| شتان | |||||
| عدا | |||||
| عسى | |||||
| عل | |||||
| على | |||||
| عليك | |||||
| عليه | |||||
| عما | |||||
| عن | |||||
| عند | |||||
| غير | |||||
| فإذا | |||||
| فإن | |||||
| فلا | |||||
| فمن | |||||
| في | |||||
| فيم | |||||
| فيما | |||||
| فيه | |||||
| فيها | |||||
| قد | |||||
| كأن | |||||
| كأنما | |||||
| كأي | |||||
| كأين | |||||
| كذا | |||||
| كذلك | |||||
| كل | |||||
| كلا | |||||
| كلاهما | |||||
| كلتا | |||||
| كلما | |||||
| كليكما | |||||
| كليهما | |||||
| كم | |||||
| كم | |||||
| كما | |||||
| كي | |||||
| كيت | |||||
| كيف | |||||
| كيفما | |||||
| لا | |||||
| لاسيما | |||||
| لدى | |||||
| لست | |||||
| لستم | |||||
| لستما | |||||
| لستن | |||||
| لسن | |||||
| لسنا | |||||
| لعل | |||||
| لك | |||||
| لكم | |||||
| لكما | |||||
| لكن | |||||
| لكنما | |||||
| لكي | |||||
| لكيلا | |||||
| لم | |||||
| لما | |||||
| لن | |||||
| لنا | |||||
| له | |||||
| لها | |||||
| لهم | |||||
| لهما | |||||
| لهن | |||||
| لو | |||||
| لولا | |||||
| لوما | |||||
| لي | |||||
| لئن | |||||
| ليت | |||||
| ليس | |||||
| ليسا | |||||
| ليست | |||||
| ليستا | |||||
| ليسوا | |||||
| ما | |||||
| ماذا | |||||
| متى | |||||
| مذ | |||||
| مع | |||||
| مما | |||||
| ممن | |||||
| من | |||||
| منه | |||||
| منها | |||||
| منذ | |||||
| مه | |||||
| مهما | |||||
| نحن | |||||
| نحو | |||||
| نعم | |||||
| ها | |||||
| هاتان | |||||
| هاته | |||||
| هاتي | |||||
| هاتين | |||||
| هاك | |||||
| هاهنا | |||||
| هذا | |||||
| هذان | |||||
| هذه | |||||
| هذي | |||||
| هذين | |||||
| هكذا | |||||
| هل | |||||
| هلا | |||||
| هم | |||||
| هما | |||||
| هن | |||||
| هنا | |||||
| هناك | |||||
| هنالك | |||||
| هو | |||||
| هؤلاء | |||||
| هي | |||||
| هيا | |||||
| هيت | |||||
| هيهات | |||||
| والذي | |||||
| والذين | |||||
| وإذ | |||||
| وإذا | |||||
| وإن | |||||
| ولا | |||||
| ولكن | |||||
| ولو | |||||
| وما | |||||
| ومن | |||||
| وهو | |||||
| يا | |||||
| أبٌ | |||||
| أخٌ | |||||
| حمٌ | |||||
| فو | |||||
| أنتِ | |||||
| يناير | |||||
| فبراير | |||||
| مارس | |||||
| أبريل | |||||
| مايو | |||||
| يونيو | |||||
| يوليو | |||||
| أغسطس | |||||
| سبتمبر | |||||
| أكتوبر | |||||
| نوفمبر | |||||
| ديسمبر | |||||
| جانفي | |||||
| فيفري | |||||
| مارس | |||||
| أفريل | |||||
| ماي | |||||
| جوان | |||||
| جويلية | |||||
| أوت | |||||
| كانون | |||||
| شباط | |||||
| آذار | |||||
| نيسان | |||||
| أيار | |||||
| حزيران | |||||
| تموز | |||||
| آب | |||||
| أيلول | |||||
| تشرين | |||||
| دولار | |||||
| دينار | |||||
| ريال | |||||
| درهم | |||||
| ليرة | |||||
| جنيه | |||||
| قرش | |||||
| مليم | |||||
| فلس | |||||
| هللة | |||||
| سنتيم | |||||
| يورو | |||||
| ين | |||||
| يوان | |||||
| شيكل | |||||
| واحد | |||||
| اثنان | |||||
| ثلاثة | |||||
| أربعة | |||||
| خمسة | |||||
| ستة | |||||
| سبعة | |||||
| ثمانية | |||||
| تسعة | |||||
| عشرة | |||||
| أحد | |||||
| اثنا | |||||
| اثني | |||||
| إحدى | |||||
| ثلاث | |||||
| أربع | |||||
| خمس | |||||
| ست | |||||
| سبع | |||||
| ثماني | |||||
| تسع | |||||
| عشر | |||||
| ثمان | |||||
| سبت | |||||
| أحد | |||||
| اثنين | |||||
| ثلاثاء | |||||
| أربعاء | |||||
| خميس | |||||
| جمعة | |||||
| أول | |||||
| ثان | |||||
| ثاني | |||||
| ثالث | |||||
| رابع | |||||
| خامس | |||||
| سادس | |||||
| سابع | |||||
| ثامن | |||||
| تاسع | |||||
| عاشر | |||||
| حادي | |||||
| أ | |||||
| ب | |||||
| ت | |||||
| ث | |||||
| ج | |||||
| ح | |||||
| خ | |||||
| د | |||||
| ذ | |||||
| ر | |||||
| ز | |||||
| س | |||||
| ش | |||||
| ص | |||||
| ض | |||||
| ط | |||||
| ظ | |||||
| ع | |||||
| غ | |||||
| ف | |||||
| ق | |||||
| ك | |||||
| ل | |||||
| م | |||||
| ن | |||||
| ه | |||||
| و | |||||
| ي | |||||
| ء | |||||
| ى | |||||
| آ | |||||
| ؤ | |||||
| ئ | |||||
| أ | |||||
| ة | |||||
| ألف | |||||
| باء | |||||
| تاء | |||||
| ثاء | |||||
| جيم | |||||
| حاء | |||||
| خاء | |||||
| دال | |||||
| ذال | |||||
| راء | |||||
| زاي | |||||
| سين | |||||
| شين | |||||
| صاد | |||||
| ضاد | |||||
| طاء | |||||
| ظاء | |||||
| عين | |||||
| غين | |||||
| فاء | |||||
| قاف | |||||
| كاف | |||||
| لام | |||||
| ميم | |||||
| نون | |||||
| هاء | |||||
| واو | |||||
| ياء | |||||
| همزة | |||||
| ي | |||||
| نا | |||||
| ك | |||||
| كن | |||||
| ه | |||||
| إياه | |||||
| إياها | |||||
| إياهما | |||||
| إياهم | |||||
| إياهن | |||||
| إياك | |||||
| إياكما | |||||
| إياكم | |||||
| إياك | |||||
| إياكن | |||||
| إياي | |||||
| إيانا | |||||
| أولالك | |||||
| تانِ | |||||
| تانِك | |||||
| تِه | |||||
| تِي | |||||
| تَيْنِ | |||||
| ثمّ | |||||
| ثمّة | |||||
| ذانِ | |||||
| ذِه | |||||
| ذِي | |||||
| ذَيْنِ | |||||
| هَؤلاء | |||||
| هَاتانِ | |||||
| هَاتِه | |||||
| هَاتِي | |||||
| هَاتَيْنِ | |||||
| هَذا | |||||
| هَذانِ | |||||
| هَذِه | |||||
| هَذِي | |||||
| هَذَيْنِ | |||||
| الألى | |||||
| الألاء | |||||
| أل | |||||
| أنّى | |||||
| أيّ | |||||
| ّأيّان | |||||
| أنّى | |||||
| أيّ | |||||
| ّأيّان | |||||
| ذيت | |||||
| كأيّ | |||||
| كأيّن | |||||
| بضع | |||||
| فلان | |||||
| وا | |||||
| آمينَ | |||||
| آهِ | |||||
| آهٍ | |||||
| آهاً | |||||
| أُفٍّ | |||||
| أُفٍّ | |||||
| أفٍّ | |||||
| أمامك | |||||
| أمامكَ | |||||
| أوّهْ | |||||
| إلَيْكَ | |||||
| إلَيْكَ | |||||
| إليكَ | |||||
| إليكنّ | |||||
| إيهٍ | |||||
| بخٍ | |||||
| بسّ | |||||
| بَسْ | |||||
| بطآن | |||||
| بَلْهَ | |||||
| حاي | |||||
| حَذارِ | |||||
| حيَّ | |||||
| حيَّ | |||||
| دونك | |||||
| رويدك | |||||
| سرعان | |||||
| شتانَ | |||||
| شَتَّانَ | |||||
| صهْ | |||||
| صهٍ | |||||
| طاق | |||||
| طَق | |||||
| عَدَسْ | |||||
| كِخ | |||||
| مكانَك | |||||
| مكانَك | |||||
| مكانَك | |||||
| مكانكم | |||||
| مكانكما | |||||
| مكانكنّ | |||||
| نَخْ | |||||
| هاكَ | |||||
| هَجْ | |||||
| هلم | |||||
| هيّا | |||||
| هَيْهات | |||||
| وا | |||||
| واهاً | |||||
| وراءَك | |||||
| وُشْكَانَ | |||||
| وَيْ | |||||
| يفعلان | |||||
| تفعلان | |||||
| يفعلون | |||||
| تفعلون | |||||
| تفعلين | |||||
| اتخذ | |||||
| ألفى | |||||
| تخذ | |||||
| ترك | |||||
| تعلَّم | |||||
| جعل | |||||
| حجا | |||||
| حبيب | |||||
| خال | |||||
| حسب | |||||
| خال | |||||
| درى | |||||
| رأى | |||||
| زعم | |||||
| صبر | |||||
| ظنَّ | |||||
| عدَّ | |||||
| علم | |||||
| غادر | |||||
| ذهب | |||||
| وجد | |||||
| ورد | |||||
| وهب | |||||
| أسكن | |||||
| أطعم | |||||
| أعطى | |||||
| رزق | |||||
| زود | |||||
| سقى | |||||
| كسا | |||||
| أخبر | |||||
| أرى | |||||
| أعلم | |||||
| أنبأ | |||||
| حدَث | |||||
| خبَّر | |||||
| نبَّا | |||||
| أفعل به | |||||
| ما أفعله | |||||
| بئس | |||||
| ساء | |||||
| طالما | |||||
| قلما | |||||
| لات | |||||
| لكنَّ | |||||
| ءَ | |||||
| أجل | |||||
| إذاً | |||||
| أمّا | |||||
| إمّا | |||||
| إنَّ | |||||
| أنًّ | |||||
| أى | |||||
| إى | |||||
| أيا | |||||
| ب | |||||
| ثمَّ | |||||
| جلل | |||||
| جير | |||||
| رُبَّ | |||||
| س | |||||
| علًّ | |||||
| ف | |||||
| كأنّ | |||||
| كلَّا | |||||
| كى | |||||
| ل | |||||
| لات | |||||
| لعلَّ | |||||
| لكنَّ | |||||
| لكنَّ | |||||
| م | |||||
| نَّ | |||||
| هلّا | |||||
| وا | |||||
| أل | |||||
| إلّا | |||||
| ت | |||||
| ك | |||||
| لمّا | |||||
| ن | |||||
| ه | |||||
| و | |||||
| ا | |||||
| ي | |||||
| تجاه | |||||
| تلقاء | |||||
| جميع | |||||
| حسب | |||||
| سبحان | |||||
| شبه | |||||
| لعمر | |||||
| مثل | |||||
| معاذ | |||||
| أبو | |||||
| أخو | |||||
| حمو | |||||
| فو | |||||
| مئة | |||||
| مئتان | |||||
| ثلاثمئة | |||||
| أربعمئة | |||||
| خمسمئة | |||||
| ستمئة | |||||
| سبعمئة | |||||
| ثمنمئة | |||||
| تسعمئة | |||||
| مائة | |||||
| ثلاثمائة | |||||
| أربعمائة | |||||
| خمسمائة | |||||
| ستمائة | |||||
| سبعمائة | |||||
| ثمانمئة | |||||
| تسعمائة | |||||
| عشرون | |||||
| ثلاثون | |||||
| اربعون | |||||
| خمسون | |||||
| ستون | |||||
| سبعون | |||||
| ثمانون | |||||
| تسعون | |||||
| عشرين | |||||
| ثلاثين | |||||
| اربعين | |||||
| خمسين | |||||
| ستين | |||||
| سبعين | |||||
| ثمانين | |||||
| تسعين | |||||
| بضع | |||||
| نيف | |||||
| أجمع | |||||
| جميع | |||||
| عامة | |||||
| عين | |||||
| نفس | |||||
| لا سيما | |||||
| أصلا | |||||
| أهلا | |||||
| أيضا | |||||
| بؤسا | |||||
| بعدا | |||||
| بغتة | |||||
| تعسا | |||||
| حقا | |||||
| حمدا | |||||
| خلافا | |||||
| خاصة | |||||
| دواليك | |||||
| سحقا | |||||
| سرا | |||||
| سمعا | |||||
| صبرا | |||||
| صدقا | |||||
| صراحة | |||||
| طرا | |||||
| عجبا | |||||
| عيانا | |||||
| غالبا | |||||
| فرادى | |||||
| فضلا | |||||
| قاطبة | |||||
| كثيرا | |||||
| لبيك | |||||
| معاذ | |||||
| أبدا | |||||
| إزاء | |||||
| أصلا | |||||
| الآن | |||||
| أمد | |||||
| أمس | |||||
| آنفا | |||||
| آناء | |||||
| أنّى | |||||
| أول | |||||
| أيّان | |||||
| تارة | |||||
| ثمّ | |||||
| ثمّة | |||||
| حقا | |||||
| صباح | |||||
| مساء | |||||
| ضحوة | |||||
| عوض | |||||
| غدا | |||||
| غداة | |||||
| قطّ | |||||
| كلّما | |||||
| لدن | |||||
| لمّا | |||||
| مرّة | |||||
| قبل | |||||
| خلف | |||||
| أمام | |||||
| فوق | |||||
| تحت | |||||
| يمين | |||||
| شمال | |||||
| ارتدّ | |||||
| استحال | |||||
| أصبح | |||||
| أضحى | |||||
| آض | |||||
| أمسى | |||||
| انقلب | |||||
| بات | |||||
| تبدّل | |||||
| تحوّل | |||||
| حار | |||||
| رجع | |||||
| راح | |||||
| صار | |||||
| ظلّ | |||||
| عاد | |||||
| غدا | |||||
| كان | |||||
| ما انفك | |||||
| ما برح | |||||
| مادام | |||||
| مازال | |||||
| مافتئ | |||||
| ابتدأ | |||||
| أخذ | |||||
| اخلولق | |||||
| أقبل | |||||
| انبرى | |||||
| أنشأ | |||||
| أوشك | |||||
| جعل | |||||
| حرى | |||||
| شرع | |||||
| طفق | |||||
| علق | |||||
| قام | |||||
| كرب | |||||
| كاد | |||||
| هبّ | |||||
+ 165
- 0
Models+K-Means/nltk_data/corpora/stopwords/azerbaijani
View File
| @@ -0,0 +1,165 @@ | |||||
| a | |||||
| ad | |||||
| altı | |||||
| altmış | |||||
| amma | |||||
| arasında | |||||
| artıq | |||||
| ay | |||||
| az | |||||
| bax | |||||
| belə | |||||
| bəli | |||||
| bəlkə | |||||
| beş | |||||
| bəy | |||||
| bəzən | |||||
| bəzi | |||||
| bilər | |||||
| bir | |||||
| biraz | |||||
| biri | |||||
| birşey | |||||
| biz | |||||
| bizim | |||||
| bizlər | |||||
| bu | |||||
| buna | |||||
| bundan | |||||
| bunların | |||||
| bunu | |||||
| bunun | |||||
| buradan | |||||
| bütün | |||||
| ci | |||||
| cı | |||||
| çox | |||||
| cu | |||||
| cü | |||||
| çünki | |||||
| da | |||||
| daha | |||||
| də | |||||
| dedi | |||||
| dək | |||||
| dən | |||||
| dəqiqə | |||||
| deyil | |||||
| dir | |||||
| doqquz | |||||
| doqsan | |||||
| dörd | |||||
| düz | |||||
| ə | |||||
| edən | |||||
| edir | |||||
| əgər | |||||
| əlbəttə | |||||
| elə | |||||
| əlli | |||||
| ən | |||||
| əslində | |||||
| et | |||||
| etdi | |||||
| etmə | |||||
| etmək | |||||
| faiz | |||||
| gilə | |||||
| görə | |||||
| ha | |||||
| haqqında | |||||
| harada | |||||
| hə | |||||
| heç | |||||
| həm | |||||
| həmin | |||||
| həmişə | |||||
| hər | |||||
| ı | |||||
| idi | |||||
| iki | |||||
| il | |||||
| ildə | |||||
| ilə | |||||
| ilk | |||||
| in | |||||
| indi | |||||
| isə | |||||
| istifadə | |||||
| iyirmi | |||||
| ki | |||||
| kim | |||||
| kimə | |||||
| kimi | |||||
| lakin | |||||
| lap | |||||
| məhz | |||||
| mən | |||||
| mənə | |||||
| mirşey | |||||
| nə | |||||
| nəhayət | |||||
| niyə | |||||
| o | |||||
| obirisi | |||||
| of | |||||
| olan | |||||
| olar | |||||
| olaraq | |||||
| oldu | |||||
| olduğu | |||||
| olmadı | |||||
| olmaz | |||||
| olmuşdur | |||||
| olsun | |||||
| olur | |||||
| on | |||||
| ona | |||||
| ondan | |||||
| onlar | |||||
| onlardan | |||||
| onların | |||||
| onsuzda | |||||
| onu | |||||
| onun | |||||
| oradan | |||||
| otuz | |||||
| öz | |||||
| özü | |||||
| qarşı | |||||
| qədər | |||||
| qırx | |||||
| saat | |||||
| sadəcə | |||||
| saniyə | |||||
| səhv | |||||
| səkkiz | |||||
| səksən | |||||
| sən | |||||
| sənə | |||||
| sənin | |||||
| siz | |||||
| sizin | |||||
| sizlər | |||||
| sonra | |||||
| təəssüf | |||||
| ü | |||||
| üç | |||||
| üçün | |||||
| var | |||||
| və | |||||
| xan | |||||
| xanım | |||||
| xeyr | |||||
| ya | |||||
| yalnız | |||||
| yaxşı | |||||
| yeddi | |||||
| yenə | |||||
| yəni | |||||
| yetmiş | |||||
| yox | |||||
| yoxdur | |||||
| yoxsa | |||||
| yüz | |||||
| zaman | |||||
+ 326
- 0
Models+K-Means/nltk_data/corpora/stopwords/basque
View File
| @@ -0,0 +1,326 @@ | |||||
| ahala | |||||
| aitzitik | |||||
| al | |||||
| ala | |||||
| alabadere | |||||
| alabaina | |||||
| alabaina | |||||
| aldiz | |||||
| alta | |||||
| amaitu | |||||
| amaitzeko | |||||
| anitz | |||||
| antzina | |||||
| arabera | |||||
| arabera | |||||
| arabera | |||||
| argi | |||||
| arratsaldero | |||||
| arte | |||||
| artean | |||||
| asko | |||||
| aspaldiko | |||||
| aurrera | |||||
| aurrera | |||||
| azkenez | |||||
| azkenik | |||||
| azkenik | |||||
| ba | |||||
| bada | |||||
| bada | |||||
| bada | |||||
| bada | |||||
| badarik | |||||
| badarik | |||||
| badarik | |||||
| badere | |||||
| bai | |||||
| baina | |||||
| baina | |||||
| baina | |||||
| baino | |||||
| baino | |||||
| baino | |||||
| baino | |||||
| baita | |||||
| baizik | |||||
| baldin | |||||
| baldin | |||||
| barren | |||||
| bat | |||||
| batean | |||||
| batean | |||||
| batean | |||||
| batean | |||||
| batek | |||||
| baten | |||||
| batera | |||||
| batez | |||||
| bati | |||||
| batzuei | |||||
| batzuek | |||||
| batzuetan | |||||
| batzuk | |||||
| bazen | |||||
| bederen | |||||
| bederik | |||||
| beharrez | |||||
| behiala | |||||
| behin | |||||
| behin | |||||
| behin | |||||
| behin | |||||
| behinik | |||||
| behinola | |||||
| behintzat | |||||
| bera | |||||
| beraiek | |||||
| beranduago | |||||
| berau | |||||
| berauek | |||||
| beraz | |||||
| beraz | |||||
| bere | |||||
| berean | |||||
| berebat | |||||
| berehala | |||||
| berori | |||||
| beroriek | |||||
| berriro | |||||
| berriz | |||||
| bertzalde | |||||
| bertzenaz | |||||
| bestalde | |||||
| beste | |||||
| bestela | |||||
| besterik | |||||
| bezain | |||||
| bezala | |||||
| bide | |||||
| bien | |||||
| bigarrenez | |||||
| bigarrenik | |||||
| bitartean | |||||
| bitartean | |||||
| bizkitartean | |||||
| bukaeran | |||||
| bukatzeko | |||||
| da | |||||
| dago | |||||
| dago | |||||
| dela | |||||
| dela | |||||
| dela | |||||
| delarik | |||||
| den | |||||
| dena | |||||
| dena | |||||
| dezadan | |||||
| dira | |||||
| ditu | |||||
| du | |||||
| dute | |||||
| edo | |||||
| edo | |||||
| edota | |||||
| egin | |||||
| egin | |||||
| egun | |||||
| egun | |||||
| egunean | |||||
| emateko | |||||
| era | |||||
| erdi | |||||
| ere | |||||
| ere | |||||
| ere | |||||
| ere | |||||
| ere | |||||
| esan | |||||
| esan | |||||
| esanak | |||||
| esandakoaren | |||||
| eta | |||||
| eta | |||||
| eta | |||||
| eta | |||||
| eta | |||||
| eta | |||||
| eurak | |||||
| ez | |||||
| ez | |||||
| ez | |||||
| eze | |||||
| ezen | |||||
| ezer | |||||
| ezezik | |||||
| ezik | |||||
| ezpabere | |||||
| ezpada | |||||
| ezpere | |||||
| ezperen | |||||
| ezta | |||||
| funtsean | |||||
| gabe | |||||
| gain | |||||
| gainera | |||||
| gainera | |||||
| gainerontzean | |||||
| gaur | |||||
| gero | |||||
| gero | |||||
| gero | |||||
| geroago | |||||
| gisa | |||||
| gu | |||||
| gutxi | |||||
| guzti | |||||
| guztia | |||||
| guztiz | |||||
| haatik | |||||
| haiei | |||||
| haiek | |||||
| haietan | |||||
| hain | |||||
| hainbeste | |||||
| hainbestez | |||||
| hala | |||||
| hala | |||||
| hala | |||||
| halaber | |||||
| halako | |||||
| halatan | |||||
| han | |||||
| handik | |||||
| hango | |||||
| hara | |||||
| hargatik | |||||
| hari | |||||
| hark | |||||
| hartan | |||||
| hartan | |||||
| hasi | |||||
| hasi | |||||
| hasiera | |||||
| hasieran | |||||
| hasteaz | |||||
| hasteko | |||||
| hasteko | |||||
| hau | |||||
| hau | |||||
| hau | |||||
| hau | |||||
| hau | |||||
| hau | |||||
| hauei | |||||
| hauek | |||||
| hauetan | |||||
| hemen | |||||
| hemendik | |||||
| hemengo | |||||
| hi | |||||
| hona | |||||
| honebestez | |||||
| honek | |||||
| honela | |||||
| honela | |||||
| honela | |||||
| honen | |||||
| honen | |||||
| honetan | |||||
| honetaz | |||||
| honi | |||||
| hor | |||||
| hori | |||||
| hori | |||||
| hori | |||||
| horiei | |||||
| horiek | |||||
| horietan | |||||
| horko | |||||
| horra | |||||
| horratik | |||||
| horregatik | |||||
| horregatik | |||||
| horrek | |||||
| horrela | |||||
| horrela | |||||
| horrela | |||||
| horren | |||||
| horrenbestez | |||||
| horretan | |||||
| horri | |||||
| hortaz | |||||
| hortaz | |||||
| hortik | |||||
| hura | |||||
| ikusi | |||||
| ikusi | |||||
| izan | |||||
| izan | |||||
| izan | |||||
| jarraituz | |||||
| kariaz | |||||
| kasuaz | |||||
| kontuan | |||||
| laburbilduz | |||||
| laburki | |||||
| laster | |||||
| laster | |||||
| lehen | |||||
| lehen | |||||
| lehen | |||||
| lehen | |||||
| lehenengo | |||||
| lehenengo | |||||
| lehenik | |||||
| lehen-lehenik | |||||
| litzateke | |||||
| medio | |||||
| mendean | |||||
| mundura | |||||
| nahiz | |||||
| ni | |||||
| noiz | |||||
| nola | |||||
| non | |||||
| nondik | |||||
| nongo | |||||
| nor | |||||
| nora | |||||
| on | |||||
| ondoren | |||||
| ondorio | |||||
| ondorioz | |||||
| ondorioz | |||||
| orain | |||||
| ordea | |||||
| orduan | |||||
| orduan | |||||
| orduan | |||||
| orduko | |||||
| ordura | |||||
| orobat | |||||
| ostean | |||||
| ostera | |||||
| osterantzean | |||||
| pentsatuz | |||||
| ustez | |||||
| ze | |||||
| zein | |||||
| zein | |||||
| zen | |||||
| zen | |||||
| zenbait | |||||
| zenbat | |||||
| zer | |||||
| zeren | |||||
| zergatik | |||||
| zergatik | |||||
| ziren | |||||
| zituen | |||||
| zu | |||||
| zuek | |||||
| zuen | |||||
| zuten | |||||
| zuzen | |||||
+ 398
- 0
Models+K-Means/nltk_data/corpora/stopwords/bengali
View File
| @@ -0,0 +1,398 @@ | |||||
| অতএব | |||||
| অথচ | |||||
| অথবা | |||||
| অনুযায়ী | |||||
| অনেক | |||||
| অনেকে | |||||
| অনেকেই | |||||
| অন্তত | |||||
| অন্য | |||||
| অবধি | |||||
| অবশ্য | |||||
| অর্থাত | |||||
| আই | |||||
| আগামী | |||||
| আগে | |||||
| আগেই | |||||
| আছে | |||||
| আজ | |||||
| আদ্যভাগে | |||||
| আপনার | |||||
| আপনি | |||||
| আবার | |||||
| আমরা | |||||
| আমাকে | |||||
| আমাদের | |||||
| আমার | |||||
| আমি | |||||
| আর | |||||
| আরও | |||||
| ই | |||||
| ইত্যাদি | |||||
| ইহা | |||||
| উচিত | |||||
| উত্তর | |||||
| উনি | |||||
| উপর | |||||
| উপরে | |||||
| এ | |||||
| এঁদের | |||||
| এঁরা | |||||
| এই | |||||
| একই | |||||
| একটি | |||||
| একবার | |||||
| একে | |||||
| এক্ | |||||
| এখন | |||||
| এখনও | |||||
| এখানে | |||||
| এখানেই | |||||
| এটা | |||||
| এটাই | |||||
| এটি | |||||
| এত | |||||
| এতটাই | |||||
| এতে | |||||
| এদের | |||||
| এব | |||||
| এবং | |||||
| এবার | |||||
| এমন | |||||
| এমনকী | |||||
| এমনি | |||||
| এর | |||||
| এরা | |||||
| এল | |||||
| এস | |||||
| এসে | |||||
| ঐ | |||||
| ও | |||||
| ওঁদের | |||||
| ওঁর | |||||
| ওঁরা | |||||
| ওই | |||||
| ওকে | |||||
| ওখানে | |||||
| ওদের | |||||
| ওর | |||||
| ওরা | |||||
| কখনও | |||||
| কত | |||||
| কবে | |||||
| কমনে | |||||
| কয়েক | |||||
| কয়েকটি | |||||
| করছে | |||||
| করছেন | |||||
| করতে | |||||
| করবে | |||||
| করবেন | |||||
| করলে | |||||
| করলেন | |||||
| করা | |||||
| করাই | |||||
| করায় | |||||
| করার | |||||
| করি | |||||
| করিতে | |||||
| করিয়া | |||||
| করিয়ে | |||||
| করে | |||||
| করেই | |||||
| করেছিলেন | |||||
| করেছে | |||||
| করেছেন | |||||
| করেন | |||||
| কাউকে | |||||
| কাছ | |||||
| কাছে | |||||
| কাজ | |||||
| কাজে | |||||
| কারও | |||||
| কারণ | |||||
| কি | |||||
| কিংবা | |||||
| কিছু | |||||
| কিছুই | |||||
| কিন্তু | |||||
| কী | |||||
| কে | |||||
| কেউ | |||||
| কেউই | |||||
| কেখা | |||||
| কেন | |||||
| কোটি | |||||
| কোন | |||||
| কোনও | |||||
| কোনো | |||||
| ক্ষেত্রে | |||||
| কয়েক | |||||
| খুব | |||||
| গিয়ে | |||||
| গিয়েছে | |||||
| গিয়ে | |||||
| গুলি | |||||
| গেছে | |||||
| গেল | |||||
| গেলে | |||||
| গোটা | |||||
| চলে | |||||
| চান | |||||
| চায় | |||||
| চার | |||||
| চালু | |||||
| চেয়ে | |||||
| চেষ্টা | |||||
| ছাড়া | |||||
| ছাড়াও | |||||
| ছিল | |||||
| ছিলেন | |||||
| জন | |||||
| জনকে | |||||
| জনের | |||||
| জন্য | |||||
| জন্যওজে | |||||
| জানতে | |||||
| জানা | |||||
| জানানো | |||||
| জানায় | |||||
| জানিয়ে | |||||
| জানিয়েছে | |||||
| জে | |||||
| জ্নজন | |||||
| টি | |||||
| ঠিক | |||||
| তখন | |||||
| তত | |||||
| তথা | |||||
| তবু | |||||
| তবে | |||||
| তা | |||||
| তাঁকে | |||||
| তাঁদের | |||||
| তাঁর | |||||
| তাঁরা | |||||
| তাঁাহারা | |||||
| তাই | |||||
| তাও | |||||
| তাকে | |||||
| তাতে | |||||
| তাদের | |||||
| তার | |||||
| তারপর | |||||
| তারা | |||||
| তারৈ | |||||
| তাহলে | |||||
| তাহা | |||||
| তাহাতে | |||||
| তাহার | |||||
| তিনঐ | |||||
| তিনি | |||||
| তিনিও | |||||
| তুমি | |||||
| তুলে | |||||
| তেমন | |||||
| তো | |||||
| তোমার | |||||
| থাকবে | |||||
| থাকবেন | |||||
| থাকা | |||||
| থাকায় | |||||
| থাকে | |||||
| থাকেন | |||||
| থেকে | |||||
| থেকেই | |||||
| থেকেও | |||||
| দিকে | |||||
| দিতে | |||||
| দিন | |||||
| দিয়ে | |||||
| দিয়েছে | |||||
| দিয়েছেন | |||||
| দিলেন | |||||
| দু | |||||
| দুই | |||||
| দুটি | |||||
| দুটো | |||||
| দেওয়া | |||||
| দেওয়ার | |||||
| দেওয়া | |||||
| দেখতে | |||||
| দেখা | |||||
| দেখে | |||||
| দেন | |||||
| দেয় | |||||
| দ্বারা | |||||
| ধরা | |||||
| ধরে | |||||
| ধামার | |||||
| নতুন | |||||
| নয় | |||||
| না | |||||
| নাই | |||||
| নাকি | |||||
| নাগাদ | |||||
| নানা | |||||
| নিজে | |||||
| নিজেই | |||||
| নিজেদের | |||||
| নিজের | |||||
| নিতে | |||||
| নিয়ে | |||||
| নিয়ে | |||||
| নেই | |||||
| নেওয়া | |||||
| নেওয়ার | |||||
| নেওয়া | |||||
| নয় | |||||
| পক্ষে | |||||
| পর | |||||
| পরে | |||||
| পরেই | |||||
| পরেও | |||||
| পর্যন্ত | |||||
| পাওয়া | |||||
| পাচ | |||||
| পারি | |||||
| পারে | |||||
| পারেন | |||||
| পি | |||||
| পেয়ে | |||||
| পেয়্র্ | |||||
| প্রতি | |||||
| প্রথম | |||||
| প্রভৃতি | |||||
| প্রযন্ত | |||||
| প্রাথমিক | |||||
| প্রায় | |||||
| প্রায় | |||||
| ফলে | |||||
| ফিরে | |||||
| ফের | |||||
| বক্তব্য | |||||
| বদলে | |||||
| বন | |||||
| বরং | |||||
| বলতে | |||||
| বলল | |||||
| বললেন | |||||
| বলা | |||||
| বলে | |||||
| বলেছেন | |||||
| বলেন | |||||
| বসে | |||||
| বহু | |||||
| বা | |||||
| বাদে | |||||
| বার | |||||
| বি | |||||
| বিনা | |||||
| বিভিন্ন | |||||
| বিশেষ | |||||
| বিষয়টি | |||||
| বেশ | |||||
| বেশি | |||||
| ব্যবহার | |||||
| ব্যাপারে | |||||
| ভাবে | |||||
| ভাবেই | |||||
| মতো | |||||
| মতোই | |||||
| মধ্যভাগে | |||||
| মধ্যে | |||||
| মধ্যেই | |||||
| মধ্যেও | |||||
| মনে | |||||
| মাত্র | |||||
| মাধ্যমে | |||||
| মোট | |||||
| মোটেই | |||||
| যখন | |||||
| যত | |||||
| যতটা | |||||
| যথেষ্ট | |||||
| যদি | |||||
| যদিও | |||||
| যা | |||||
| যাঁর | |||||
| যাঁরা | |||||
| যাওয়া | |||||
| যাওয়ার | |||||
| যাওয়া | |||||
| যাকে | |||||
| যাচ্ছে | |||||
| যাতে | |||||
| যাদের | |||||
| যান | |||||
| যাবে | |||||
| যায় | |||||
| যার | |||||
| যারা | |||||
| যিনি | |||||
| যে | |||||
| যেখানে | |||||
| যেতে | |||||
| যেন | |||||
| যেমন | |||||
| র | |||||
| রকম | |||||
| রয়েছে | |||||
| রাখা | |||||
| রেখে | |||||
| লক্ষ | |||||
| শুধু | |||||
| শুরু | |||||
| সঙ্গে | |||||
| সঙ্গেও | |||||
| সব | |||||
| সবার | |||||
| সমস্ত | |||||
| সম্প্রতি | |||||
| সহ | |||||
| সহিত | |||||
| সাধারণ | |||||
| সামনে | |||||
| সি | |||||
| সুতরাং | |||||
| সে | |||||
| সেই | |||||
| সেখান | |||||
| সেখানে | |||||
| সেটা | |||||
| সেটাই | |||||
| সেটাও | |||||
| সেটি | |||||
| স্পষ্ট | |||||
| স্বয়ং | |||||
| হইতে | |||||
| হইবে | |||||
| হইয়া | |||||
| হওয়া | |||||
| হওয়ায় | |||||
| হওয়ার | |||||
| হচ্ছে | |||||
| হত | |||||
| হতে | |||||
| হতেই | |||||
| হন | |||||
| হবে | |||||
| হবেন | |||||
| হয় | |||||
| হয়তো | |||||
| হয়নি | |||||
| হয়ে | |||||
| হয়েই | |||||
| হয়েছিল | |||||
| হয়েছে | |||||
| হয়েছেন | |||||
| হল | |||||
| হলে | |||||
| হলেই | |||||
| হলেও | |||||
| হলো | |||||
| হাজার | |||||
| হিসাবে | |||||
| হৈলে | |||||
| হোক | |||||
| হয় | |||||
+ 278
- 0
Models+K-Means/nltk_data/corpora/stopwords/catalan
View File
| @@ -0,0 +1,278 @@ | |||||
| a | |||||
| abans | |||||
| ací | |||||
| ah | |||||
| així | |||||
| això | |||||
| al | |||||
| aleshores | |||||
| algun | |||||
| alguna | |||||
| algunes | |||||
| alguns | |||||
| alhora | |||||
| allà | |||||
| allí | |||||
| allò | |||||
| als | |||||
| altra | |||||
| altre | |||||
| altres | |||||
| amb | |||||
| ambdues | |||||
| ambdós | |||||
| anar | |||||
| ans | |||||
| apa | |||||
| aquell | |||||
| aquella | |||||
| aquelles | |||||
| aquells | |||||
| aquest | |||||
| aquesta | |||||
| aquestes | |||||
| aquests | |||||
| aquí | |||||
| baix | |||||
| bastant | |||||
| bé | |||||
| cada | |||||
| cadascuna | |||||
| cadascunes | |||||
| cadascuns | |||||
| cadascú | |||||
| com | |||||
| consegueixo | |||||
| conseguim | |||||
| conseguir | |||||
| consigueix | |||||
| consigueixen | |||||
| consigueixes | |||||
| contra | |||||
| d'un | |||||
| d'una | |||||
| d'unes | |||||
| d'uns | |||||
| dalt | |||||
| de | |||||
| del | |||||
| dels | |||||
| des | |||||
| des de | |||||
| després | |||||
| dins | |||||
| dintre | |||||
| donat | |||||
| doncs | |||||
| durant | |||||
| e | |||||
| eh | |||||
| el | |||||
| elles | |||||
| ells | |||||
| els | |||||
| em | |||||
| en | |||||
| encara | |||||
| ens | |||||
| entre | |||||
| era | |||||
| erem | |||||
| eren | |||||
| eres | |||||
| es | |||||
| esta | |||||
| estan | |||||
| estat | |||||
| estava | |||||
| estaven | |||||
| estem | |||||
| esteu | |||||
| estic | |||||
| està | |||||
| estàvem | |||||
| estàveu | |||||
| et | |||||
| etc | |||||
| ets | |||||
| fa | |||||
| faig | |||||
| fan | |||||
| fas | |||||
| fem | |||||
| fer | |||||
| feu | |||||
| fi | |||||
| fins | |||||
| fora | |||||
| gairebé | |||||
| ha | |||||
| han | |||||
| has | |||||
| haver | |||||
| havia | |||||
| he | |||||
| hem | |||||
| heu | |||||
| hi | |||||
| ho | |||||
| i | |||||
| igual | |||||
| iguals | |||||
| inclòs | |||||
| ja | |||||
| jo | |||||
| l'hi | |||||
| la | |||||
| les | |||||
| li | |||||
| li'n | |||||
| llarg | |||||
| llavors | |||||
| m'he | |||||
| ma | |||||
| mal | |||||
| malgrat | |||||
| mateix | |||||
| mateixa | |||||
| mateixes | |||||
| mateixos | |||||
| me | |||||
| mentre | |||||
| meu | |||||
| meus | |||||
| meva | |||||
| meves | |||||
| mode | |||||
| molt | |||||
| molta | |||||
| moltes | |||||
| molts | |||||
| mon | |||||
| mons | |||||
| més | |||||
| n'he | |||||
| n'hi | |||||
| ne | |||||
| ni | |||||
| no | |||||
| nogensmenys | |||||
| només | |||||
| nosaltres | |||||
| nostra | |||||
| nostre | |||||
| nostres | |||||
| o | |||||
| oh | |||||
| oi | |||||
| on | |||||
| pas | |||||
| pel | |||||
| pels | |||||
| per | |||||
| per que | |||||
| perquè | |||||
| però | |||||
| poc | |||||
| poca | |||||
| pocs | |||||
| podem | |||||
| poden | |||||
| poder | |||||
| podeu | |||||
| poques | |||||
| potser | |||||
| primer | |||||
| propi | |||||
| puc | |||||
| qual | |||||
| quals | |||||
| quan | |||||
| quant | |||||
| que | |||||
| quelcom | |||||
| qui | |||||
| quin | |||||
| quina | |||||
| quines | |||||
| quins | |||||
| què | |||||
| s'ha | |||||
| s'han | |||||
| sa | |||||
| sabem | |||||
| saben | |||||
| saber | |||||
| sabeu | |||||
| sap | |||||
| saps | |||||
| semblant | |||||
| semblants | |||||
| sense | |||||
| ser | |||||
| ses | |||||
| seu | |||||
| seus | |||||
| seva | |||||
| seves | |||||
| si | |||||
| sobre | |||||
| sobretot | |||||
| soc | |||||
| solament | |||||
| sols | |||||
| som | |||||
| son | |||||
| sons | |||||
| sota | |||||
| sou | |||||
| sóc | |||||
| són | |||||
| t'ha | |||||
| t'han | |||||
| t'he | |||||
| ta | |||||
| tal | |||||
| també | |||||
| tampoc | |||||
| tan | |||||
| tant | |||||
| tanta | |||||
| tantes | |||||
| te | |||||
| tene | |||||
| tenim | |||||
| tenir | |||||
| teniu | |||||
| teu | |||||
| teus | |||||
| teva | |||||
| teves | |||||
| tinc | |||||
| ton | |||||
| tons | |||||
| tot | |||||
| tota | |||||
| totes | |||||
| tots | |||||
| un | |||||
| una | |||||
| unes | |||||
| uns | |||||
| us | |||||
| va | |||||
| vaig | |||||
| vam | |||||
| van | |||||
| vas | |||||
| veu | |||||
| vosaltres | |||||
| vostra | |||||
| vostre | |||||
| vostres | |||||
| érem | |||||
| éreu | |||||
| és | |||||
| éssent | |||||
| últim | |||||
| ús | |||||
+ 841
- 0
Models+K-Means/nltk_data/corpora/stopwords/chinese
View File
| @@ -0,0 +1,841 @@ | |||||
| 一 | |||||
| 一下 | |||||
| 一些 | |||||
| 一切 | |||||
| 一则 | |||||
| 一天 | |||||
| 一定 | |||||
| 一方面 | |||||
| 一旦 | |||||
| 一时 | |||||
| 一来 | |||||
| 一样 | |||||
| 一次 | |||||
| 一片 | |||||
| 一直 | |||||
| 一致 | |||||
| 一般 | |||||
| 一起 | |||||
| 一边 | |||||
| 一面 | |||||
| 万一 | |||||
| 上下 | |||||
| 上升 | |||||
| 上去 | |||||
| 上来 | |||||
| 上述 | |||||
| 上面 | |||||
| 下列 | |||||
| 下去 | |||||
| 下来 | |||||
| 下面 | |||||
| 不一 | |||||
| 不久 | |||||
| 不仅 | |||||
| 不会 | |||||
| 不但 | |||||
| 不光 | |||||
| 不单 | |||||
| 不变 | |||||
| 不只 | |||||
| 不可 | |||||
| 不同 | |||||
| 不够 | |||||
| 不如 | |||||
| 不得 | |||||
| 不怕 | |||||
| 不惟 | |||||
| 不成 | |||||
| 不拘 | |||||
| 不敢 | |||||
| 不断 | |||||
| 不是 | |||||
| 不比 | |||||
| 不然 | |||||
| 不特 | |||||
| 不独 | |||||
| 不管 | |||||
| 不能 | |||||
| 不要 | |||||
| 不论 | |||||
| 不足 | |||||
| 不过 | |||||
| 不问 | |||||
| 与 | |||||
| 与其 | |||||
| 与否 | |||||
| 与此同时 | |||||
| 专门 | |||||
| 且 | |||||
| 两者 | |||||
| 严格 | |||||
| 严重 | |||||
| 个 | |||||
| 个人 | |||||
| 个别 | |||||
| 中小 | |||||
| 中间 | |||||
| 丰富 | |||||
| 临 | |||||
| 为 | |||||
| 为主 | |||||
| 为了 | |||||
| 为什么 | |||||
| 为什麽 | |||||
| 为何 | |||||
| 为着 | |||||
| 主张 | |||||
| 主要 | |||||
| 举行 | |||||
| 乃 | |||||
| 乃至 | |||||
| 么 | |||||
| 之 | |||||
| 之一 | |||||
| 之前 | |||||
| 之后 | |||||
| 之後 | |||||
| 之所以 | |||||
| 之类 | |||||
| 乌乎 | |||||
| 乎 | |||||
| 乘 | |||||
| 也 | |||||
| 也好 | |||||
| 也是 | |||||
| 也罢 | |||||
| 了 | |||||
| 了解 | |||||
| 争取 | |||||
| 于 | |||||
| 于是 | |||||
| 于是乎 | |||||
| 云云 | |||||
| 互相 | |||||
| 产生 | |||||
| 人们 | |||||
| 人家 | |||||
| 什么 | |||||
| 什么样 | |||||
| 什麽 | |||||
| 今后 | |||||
| 今天 | |||||
| 今年 | |||||
| 今後 | |||||
| 仍然 | |||||
| 从 | |||||
| 从事 | |||||
| 从而 | |||||
| 他 | |||||
| 他人 | |||||
| 他们 | |||||
| 他的 | |||||
| 代替 | |||||
| 以 | |||||
| 以上 | |||||
| 以下 | |||||
| 以为 | |||||
| 以便 | |||||
| 以免 | |||||
| 以前 | |||||
| 以及 | |||||
| 以后 | |||||
| 以外 | |||||
| 以後 | |||||
| 以来 | |||||
| 以至 | |||||
| 以至于 | |||||
| 以致 | |||||
| 们 | |||||
| 任 | |||||
| 任何 | |||||
| 任凭 | |||||
| 任务 | |||||
| 企图 | |||||
| 伟大 | |||||
| 似乎 | |||||
| 似的 | |||||
| 但 | |||||
| 但是 | |||||
| 何 | |||||
| 何况 | |||||
| 何处 | |||||
| 何时 | |||||
| 作为 | |||||
| 你 | |||||
| 你们 | |||||
| 你的 | |||||
| 使得 | |||||
| 使用 | |||||
| 例如 | |||||
| 依 | |||||
| 依照 | |||||
| 依靠 | |||||
| 促进 | |||||
| 保持 | |||||
| 俺 | |||||
| 俺们 | |||||
| 倘 | |||||
| 倘使 | |||||
| 倘或 | |||||
| 倘然 | |||||
| 倘若 | |||||
| 假使 | |||||
| 假如 | |||||
| 假若 | |||||
| 做到 | |||||
| 像 | |||||
| 允许 | |||||
| 充分 | |||||
| 先后 | |||||
| 先後 | |||||
| 先生 | |||||
| 全部 | |||||
| 全面 | |||||
| 兮 | |||||
| 共同 | |||||
| 关于 | |||||
| 其 | |||||
| 其一 | |||||
| 其中 | |||||
| 其二 | |||||
| 其他 | |||||
| 其余 | |||||
| 其它 | |||||
| 其实 | |||||
| 其次 | |||||
| 具体 | |||||
| 具体地说 | |||||
| 具体说来 | |||||
| 具有 | |||||
| 再者 | |||||
| 再说 | |||||
| 冒 | |||||
| 冲 | |||||
| 决定 | |||||
| 况且 | |||||
| 准备 | |||||
| 几 | |||||
| 几乎 | |||||
| 几时 | |||||
| 凭 | |||||
| 凭借 | |||||
| 出去 | |||||
| 出来 | |||||
| 出现 | |||||
| 分别 | |||||
| 则 | |||||
| 别 | |||||
| 别的 | |||||
| 别说 | |||||
| 到 | |||||
| 前后 | |||||
| 前者 | |||||
| 前进 | |||||
| 前面 | |||||
| 加之 | |||||
| 加以 | |||||
| 加入 | |||||
| 加强 | |||||
| 十分 | |||||
| 即 | |||||
| 即令 | |||||
| 即使 | |||||
| 即便 | |||||
| 即或 | |||||
| 即若 | |||||
| 却不 | |||||
| 原来 | |||||
| 又 | |||||
| 及 | |||||
| 及其 | |||||
| 及时 | |||||
| 及至 | |||||
| 双方 | |||||
| 反之 | |||||
| 反应 | |||||
| 反映 | |||||
| 反过来 | |||||
| 反过来说 | |||||
| 取得 | |||||
| 受到 | |||||
| 变成 | |||||
| 另 | |||||
| 另一方面 | |||||
| 另外 | |||||
| 只是 | |||||
| 只有 | |||||
| 只要 | |||||
| 只限 | |||||
| 叫 | |||||
| 叫做 | |||||
| 召开 | |||||
| 叮咚 | |||||
| 可 | |||||
| 可以 | |||||
| 可是 | |||||
| 可能 | |||||
| 可见 | |||||
| 各 | |||||
| 各个 | |||||
| 各人 | |||||
| 各位 | |||||
| 各地 | |||||
| 各种 | |||||
| 各级 | |||||
| 各自 | |||||
| 合理 | |||||
| 同 | |||||
| 同一 | |||||
| 同时 | |||||
| 同样 | |||||
| 后来 | |||||
| 后面 | |||||
| 向 | |||||
| 向着 | |||||
| 吓 | |||||
| 吗 | |||||
| 否则 | |||||
| 吧 | |||||
| 吧哒 | |||||
| 吱 | |||||
| 呀 | |||||
| 呃 | |||||
| 呕 | |||||
| 呗 | |||||
| 呜 | |||||
| 呜呼 | |||||
| 呢 | |||||
| 周围 | |||||
| 呵 | |||||
| 呸 | |||||
| 呼哧 | |||||
| 咋 | |||||
| 和 | |||||
| 咚 | |||||
| 咦 | |||||
| 咱 | |||||
| 咱们 | |||||
| 咳 | |||||
| 哇 | |||||
| 哈 | |||||
| 哈哈 | |||||
| 哉 | |||||
| 哎 | |||||
| 哎呀 | |||||
| 哎哟 | |||||
| 哗 | |||||
| 哟 | |||||
| 哦 | |||||
| 哩 | |||||
| 哪 | |||||
| 哪个 | |||||
| 哪些 | |||||
| 哪儿 | |||||
| 哪天 | |||||
| 哪年 | |||||
| 哪怕 | |||||
| 哪样 | |||||
| 哪边 | |||||
| 哪里 | |||||
| 哼 | |||||
| 哼唷 | |||||
| 唉 | |||||
| 啊 | |||||
| 啐 | |||||
| 啥 | |||||
| 啦 | |||||
| 啪达 | |||||
| 喂 | |||||
| 喏 | |||||
| 喔唷 | |||||
| 嗡嗡 | |||||
| 嗬 | |||||
| 嗯 | |||||
| 嗳 | |||||
| 嘎 | |||||
| 嘎登 | |||||
| 嘘 | |||||
| 嘛 | |||||
| 嘻 | |||||
| 嘿 | |||||
| 因 | |||||
| 因为 | |||||
| 因此 | |||||
| 因而 | |||||
| 固然 | |||||
| 在 | |||||
| 在下 | |||||
| 地 | |||||
| 坚决 | |||||
| 坚持 | |||||
| 基本 | |||||
| 处理 | |||||
| 复杂 | |||||
| 多 | |||||
| 多少 | |||||
| 多数 | |||||
| 多次 | |||||
| 大力 | |||||
| 大多数 | |||||
| 大大 | |||||
| 大家 | |||||
| 大批 | |||||
| 大约 | |||||
| 大量 | |||||
| 失去 | |||||
| 她 | |||||
| 她们 | |||||
| 她的 | |||||
| 好的 | |||||
| 好象 | |||||
| 如 | |||||
| 如上所述 | |||||
| 如下 | |||||
| 如何 | |||||
| 如其 | |||||
| 如果 | |||||
| 如此 | |||||
| 如若 | |||||
| 存在 | |||||
| 宁 | |||||
| 宁可 | |||||
| 宁愿 | |||||
| 宁肯 | |||||
| 它 | |||||
| 它们 | |||||
| 它们的 | |||||
| 它的 | |||||
| 安全 | |||||
| 完全 | |||||
| 完成 | |||||
| 实现 | |||||
| 实际 | |||||
| 宣布 | |||||
| 容易 | |||||
| 密切 | |||||
| 对 | |||||
| 对于 | |||||
| 对应 | |||||
| 将 | |||||
| 少数 | |||||
| 尔后 | |||||
| 尚且 | |||||
| 尤其 | |||||
| 就 | |||||
| 就是 | |||||
| 就是说 | |||||
| 尽 | |||||
| 尽管 | |||||
| 属于 | |||||
| 岂但 | |||||
| 左右 | |||||
| 巨大 | |||||
| 巩固 | |||||
| 己 | |||||
| 已经 | |||||
| 帮助 | |||||
| 常常 | |||||
| 并 | |||||
| 并不 | |||||
| 并不是 | |||||
| 并且 | |||||
| 并没有 | |||||
| 广大 | |||||
| 广泛 | |||||
| 应当 | |||||
| 应用 | |||||
| 应该 | |||||
| 开外 | |||||
| 开始 | |||||
| 开展 | |||||
| 引起 | |||||
| 强烈 | |||||
| 强调 | |||||
| 归 | |||||
| 当 | |||||
| 当前 | |||||
| 当时 | |||||
| 当然 | |||||
| 当着 | |||||
| 形成 | |||||
| 彻底 | |||||
| 彼 | |||||
| 彼此 | |||||
| 往 | |||||
| 往往 | |||||
| 待 | |||||
| 後来 | |||||
| 後面 | |||||
| 得 | |||||
| 得出 | |||||
| 得到 | |||||
| 心里 | |||||
| 必然 | |||||
| 必要 | |||||
| 必须 | |||||
| 怎 | |||||
| 怎么 | |||||
| 怎么办 | |||||
| 怎么样 | |||||
| 怎样 | |||||
| 怎麽 | |||||
| 总之 | |||||
| 总是 | |||||
| 总的来看 | |||||
| 总的来说 | |||||
| 总的说来 | |||||
| 总结 | |||||
| 总而言之 | |||||
| 恰恰相反 | |||||
| 您 | |||||
| 意思 | |||||
| 愿意 | |||||
| 慢说 | |||||
| 成为 | |||||
| 我 | |||||
| 我们 | |||||
| 我的 | |||||
| 或 | |||||
| 或是 | |||||
| 或者 | |||||
| 战斗 | |||||
| 所 | |||||
| 所以 | |||||
| 所有 | |||||
| 所谓 | |||||
| 打 | |||||
| 扩大 | |||||
| 把 | |||||
| 抑或 | |||||
| 拿 | |||||
| 按 | |||||
| 按照 | |||||
| 换句话说 | |||||
| 换言之 | |||||
| 据 | |||||
| 掌握 | |||||
| 接着 | |||||
| 接著 | |||||
| 故 | |||||
| 故此 | |||||
| 整个 | |||||
| 方便 | |||||
| 方面 | |||||
| 旁人 | |||||
| 无宁 | |||||
| 无法 | |||||
| 无论 | |||||
| 既 | |||||
| 既是 | |||||
| 既然 | |||||
| 时候 | |||||
| 明显 | |||||
| 明确 | |||||
| 是 | |||||
| 是否 | |||||
| 是的 | |||||
| 显然 | |||||
| 显著 | |||||
| 普通 | |||||
| 普遍 | |||||
| 更加 | |||||
| 曾经 | |||||
| 替 | |||||
| 最后 | |||||
| 最大 | |||||
| 最好 | |||||
| 最後 | |||||
| 最近 | |||||
| 最高 | |||||
| 有 | |||||
| 有些 | |||||
| 有关 | |||||
| 有利 | |||||
| 有力 | |||||
| 有所 | |||||
| 有效 | |||||
| 有时 | |||||
| 有点 | |||||
| 有的 | |||||
| 有着 | |||||
| 有著 | |||||
| 望 | |||||
| 朝 | |||||
| 朝着 | |||||
| 本 | |||||
| 本着 | |||||
| 来 | |||||
| 来着 | |||||
| 极了 | |||||
| 构成 | |||||
| 果然 | |||||
| 果真 | |||||
| 某 | |||||
| 某个 | |||||
| 某些 | |||||
| 根据 | |||||
| 根本 | |||||
| 欢迎 | |||||
| 正在 | |||||
| 正如 | |||||
| 正常 | |||||
| 此 | |||||
| 此外 | |||||
| 此时 | |||||
| 此间 | |||||
| 毋宁 | |||||
| 每 | |||||
| 每个 | |||||
| 每天 | |||||
| 每年 | |||||
| 每当 | |||||
| 比 | |||||
| 比如 | |||||
| 比方 | |||||
| 比较 | |||||
| 毫不 | |||||
| 没有 | |||||
| 沿 | |||||
| 沿着 | |||||
| 注意 | |||||
| 深入 | |||||
| 清楚 | |||||
| 满足 | |||||
| 漫说 | |||||
| 焉 | |||||
| 然则 | |||||
| 然后 | |||||
| 然後 | |||||
| 然而 | |||||
| 照 | |||||
| 照着 | |||||
| 特别是 | |||||
| 特殊 | |||||
| 特点 | |||||
| 现代 | |||||
| 现在 | |||||
| 甚么 | |||||
| 甚而 | |||||
| 甚至 | |||||
| 用 | |||||
| 由 | |||||
| 由于 | |||||
| 由此可见 | |||||
| 的 | |||||
| 的话 | |||||
| 目前 | |||||
| 直到 | |||||
| 直接 | |||||
| 相似 | |||||
| 相信 | |||||
| 相反 | |||||
| 相同 | |||||
| 相对 | |||||
| 相对而言 | |||||
| 相应 | |||||
| 相当 | |||||
| 相等 | |||||
| 省得 | |||||
| 看出 | |||||
| 看到 | |||||
| 看来 | |||||
| 看看 | |||||
| 看见 | |||||
| 真是 | |||||
| 真正 | |||||
| 着 | |||||
| 着呢 | |||||
| 矣 | |||||
| 知道 | |||||
| 确定 | |||||
| 离 | |||||
| 积极 | |||||
| 移动 | |||||
| 突出 | |||||
| 突然 | |||||
| 立即 | |||||
| 第 | |||||
| 等 | |||||
| 等等 | |||||
| 管 | |||||
| 紧接着 | |||||
| 纵 | |||||
| 纵令 | |||||
| 纵使 | |||||
| 纵然 | |||||
| 练习 | |||||
| 组成 | |||||
| 经 | |||||
| 经常 | |||||
| 经过 | |||||
| 结合 | |||||
| 结果 | |||||
| 给 | |||||
| 绝对 | |||||
| 继续 | |||||
| 继而 | |||||
| 维持 | |||||
| 综上所述 | |||||
| 罢了 | |||||
| 考虑 | |||||
| 者 | |||||
| 而 | |||||
| 而且 | |||||
| 而况 | |||||
| 而外 | |||||
| 而已 | |||||
| 而是 | |||||
| 而言 | |||||
| 联系 | |||||
| 能 | |||||
| 能否 | |||||
| 能够 | |||||
| 腾 | |||||
| 自 | |||||
| 自个儿 | |||||
| 自从 | |||||
| 自各儿 | |||||
| 自家 | |||||
| 自己 | |||||
| 自身 | |||||
| 至 | |||||
| 至于 | |||||
| 良好 | |||||
| 若 | |||||
| 若是 | |||||
| 若非 | |||||
| 范围 | |||||
| 莫若 | |||||
| 获得 | |||||
| 虽 | |||||
| 虽则 | |||||
| 虽然 | |||||
| 虽说 | |||||
| 行为 | |||||
| 行动 | |||||
| 表明 | |||||
| 表示 | |||||
| 被 | |||||
| 要 | |||||
| 要不 | |||||
| 要不是 | |||||
| 要不然 | |||||
| 要么 | |||||
| 要是 | |||||
| 要求 | |||||
| 规定 | |||||
| 觉得 | |||||
| 认为 | |||||
| 认真 | |||||
| 认识 | |||||
| 让 | |||||
| 许多 | |||||
| 论 | |||||
| 设使 | |||||
| 设若 | |||||
| 该 | |||||
| 说明 | |||||
| 诸位 | |||||
| 谁 | |||||
| 谁知 | |||||
| 赶 | |||||
| 起 | |||||
| 起来 | |||||
| 起见 | |||||
| 趁 | |||||
| 趁着 | |||||
| 越是 | |||||
| 跟 | |||||
| 转动 | |||||
| 转变 | |||||
| 转贴 | |||||
| 较 | |||||
| 较之 | |||||
| 边 | |||||
| 达到 | |||||
| 迅速 | |||||
| 过 | |||||
| 过去 | |||||
| 过来 | |||||
| 运用 | |||||
| 还是 | |||||
| 还有 | |||||
| 这 | |||||
| 这个 | |||||
| 这么 | |||||
| 这么些 | |||||
| 这么样 | |||||
| 这么点儿 | |||||
| 这些 | |||||
| 这会儿 | |||||
| 这儿 | |||||
| 这就是说 | |||||
| 这时 | |||||
| 这样 | |||||
| 这点 | |||||
| 这种 | |||||
| 这边 | |||||
| 这里 | |||||
| 这麽 | |||||
| 进入 | |||||
| 进步 | |||||
| 进而 | |||||
| 进行 | |||||
| 连 | |||||
| 连同 | |||||
| 适应 | |||||
| 适当 | |||||
| 适用 | |||||
| 逐步 | |||||
| 逐渐 | |||||
| 通常 | |||||
| 通过 | |||||
| 造成 | |||||
| 遇到 | |||||
| 遭到 | |||||
| 避免 | |||||
| 那 | |||||
| 那个 | |||||
| 那么 | |||||
| 那么些 | |||||
| 那么样 | |||||
| 那些 | |||||
| 那会儿 | |||||
| 那儿 | |||||
| 那时 | |||||
| 那样 | |||||
| 那边 | |||||
| 那里 | |||||
| 那麽 | |||||
| 部分 | |||||
| 鄙人 | |||||
| 采取 | |||||
| 里面 | |||||
| 重大 | |||||
| 重新 | |||||
| 重要 | |||||
| 鉴于 | |||||
| 问题 | |||||
| 防止 | |||||
| 阿 | |||||
| 附近 | |||||
| 限制 | |||||
| 除 | |||||
| 除了 | |||||
| 除此之外 | |||||
| 除非 | |||||
| 随 | |||||
| 随着 | |||||
| 随著 | |||||
| 集中 | |||||
| 需要 | |||||
| 非但 | |||||
| 非常 | |||||
| 非徒 | |||||
| 靠 | |||||
| 顺 | |||||
| 顺着 | |||||
| 首先 | |||||
| 高兴 | |||||
| 是不是 | |||||
+ 94
- 0
Models+K-Means/nltk_data/corpora/stopwords/danish
View File
| @@ -0,0 +1,94 @@ | |||||
| og | |||||
| i | |||||
| jeg | |||||
| det | |||||
| at | |||||
| en | |||||
| den | |||||
| til | |||||
| er | |||||
| som | |||||
| på | |||||
| de | |||||
| med | |||||
| han | |||||
| af | |||||
| for | |||||
| ikke | |||||
| der | |||||
| var | |||||
| mig | |||||
| sig | |||||
| men | |||||
| et | |||||
| har | |||||
| om | |||||
| vi | |||||
| min | |||||
| havde | |||||
| ham | |||||
| hun | |||||
| nu | |||||
| over | |||||
| da | |||||
| fra | |||||
| du | |||||
| ud | |||||
| sin | |||||
| dem | |||||
| os | |||||
| op | |||||
| man | |||||
| hans | |||||
| hvor | |||||
| eller | |||||
| hvad | |||||
| skal | |||||
| selv | |||||
| her | |||||
| alle | |||||
| vil | |||||
| blev | |||||
| kunne | |||||
| ind | |||||
| når | |||||
| være | |||||
| dog | |||||
| noget | |||||
| ville | |||||
| jo | |||||
| deres | |||||
| efter | |||||
| ned | |||||
| skulle | |||||
| denne | |||||
| end | |||||
| dette | |||||
| mit | |||||
| også | |||||
| under | |||||
| have | |||||
| dig | |||||
| anden | |||||
| hende | |||||
| mine | |||||
| alt | |||||
| meget | |||||
| sit | |||||
| sine | |||||
| vor | |||||
| mod | |||||
| disse | |||||
| hvis | |||||
| din | |||||
| nogle | |||||
| hos | |||||
| blive | |||||
| mange | |||||
| ad | |||||
| bliver | |||||
| hendes | |||||
| været | |||||
| thi | |||||
| jer | |||||
| sådan | |||||
+ 101
- 0
Models+K-Means/nltk_data/corpora/stopwords/dutch
View File
| @@ -0,0 +1,101 @@ | |||||
| de | |||||
| en | |||||
| van | |||||
| ik | |||||
| te | |||||
| dat | |||||
| die | |||||
| in | |||||
| een | |||||
| hij | |||||
| het | |||||
| niet | |||||
| zijn | |||||
| is | |||||
| was | |||||
| op | |||||
| aan | |||||
| met | |||||
| als | |||||
| voor | |||||
| had | |||||
| er | |||||
| maar | |||||
| om | |||||
| hem | |||||
| dan | |||||
| zou | |||||
| of | |||||
| wat | |||||
| mijn | |||||
| men | |||||
| dit | |||||
| zo | |||||
| door | |||||
| over | |||||
| ze | |||||
| zich | |||||
| bij | |||||
| ook | |||||
| tot | |||||
| je | |||||
| mij | |||||
| uit | |||||
| der | |||||
| daar | |||||
| haar | |||||
| naar | |||||
| heb | |||||
| hoe | |||||
| heeft | |||||
| hebben | |||||
| deze | |||||
| u | |||||
| want | |||||
| nog | |||||
| zal | |||||
| me | |||||
| zij | |||||
| nu | |||||
| ge | |||||
| geen | |||||
| omdat | |||||
| iets | |||||
| worden | |||||
| toch | |||||
| al | |||||
| waren | |||||
| veel | |||||
| meer | |||||
| doen | |||||
| toen | |||||
| moet | |||||
| ben | |||||
| zonder | |||||
| kan | |||||
| hun | |||||
| dus | |||||
| alles | |||||
| onder | |||||
| ja | |||||
| eens | |||||
| hier | |||||
| wie | |||||
| werd | |||||
| altijd | |||||
| doch | |||||
| wordt | |||||
| wezen | |||||
| kunnen | |||||
| ons | |||||
| zelf | |||||
| tegen | |||||
| na | |||||
| reeds | |||||
| wil | |||||
| kon | |||||
| niets | |||||
| uw | |||||
| iemand | |||||
| geweest | |||||
| andere | |||||
+ 179
- 0
Models+K-Means/nltk_data/corpora/stopwords/english
View File
| @@ -0,0 +1,179 @@ | |||||
| i | |||||
| me | |||||
| my | |||||
| myself | |||||
| we | |||||
| our | |||||
| ours | |||||
| ourselves | |||||
| you | |||||
| you're | |||||
| you've | |||||
| you'll | |||||
| you'd | |||||
| your | |||||
| yours | |||||
| yourself | |||||
| yourselves | |||||
| he | |||||
| him | |||||
| his | |||||
| himself | |||||
| she | |||||
| she's | |||||
| her | |||||
| hers | |||||
| herself | |||||
| it | |||||
| it's | |||||
| its | |||||
| itself | |||||
| they | |||||
| them | |||||
| their | |||||
| theirs | |||||
| themselves | |||||
| what | |||||
| which | |||||
| who | |||||
| whom | |||||
| this | |||||
| that | |||||
| that'll | |||||
| these | |||||
| those | |||||
| am | |||||
| is | |||||
| are | |||||
| was | |||||
| were | |||||
| be | |||||
| been | |||||
| being | |||||
| have | |||||
| has | |||||
| had | |||||
| having | |||||
| do | |||||
| does | |||||
| did | |||||
| doing | |||||
| a | |||||
| an | |||||
| the | |||||
| and | |||||
| but | |||||
| if | |||||
| or | |||||
| because | |||||
| as | |||||
| until | |||||
| while | |||||
| of | |||||
| at | |||||
| by | |||||
| for | |||||
| with | |||||
| about | |||||
| against | |||||
| between | |||||
| into | |||||
| through | |||||
| during | |||||
| before | |||||
| after | |||||
| above | |||||
| below | |||||
| to | |||||
| from | |||||
| up | |||||
| down | |||||
| in | |||||
| out | |||||
| on | |||||
| off | |||||
| over | |||||
| under | |||||
| again | |||||
| further | |||||
| then | |||||
| once | |||||
| here | |||||
| there | |||||
| when | |||||
| where | |||||
| why | |||||
| how | |||||
| all | |||||
| any | |||||
| both | |||||
| each | |||||
| few | |||||
| more | |||||
| most | |||||
| other | |||||
| some | |||||
| such | |||||
| no | |||||
| nor | |||||
| not | |||||
| only | |||||
| own | |||||
| same | |||||
| so | |||||
| than | |||||
| too | |||||
| very | |||||
| s | |||||
| t | |||||
| can | |||||
| will | |||||
| just | |||||
| don | |||||
| don't | |||||
| should | |||||
| should've | |||||
| now | |||||
| d | |||||
| ll | |||||
| m | |||||
| o | |||||
| re | |||||
| ve | |||||
| y | |||||
| ain | |||||
| aren | |||||
| aren't | |||||
| couldn | |||||
| couldn't | |||||
| didn | |||||
| didn't | |||||
| doesn | |||||
| doesn't | |||||
| hadn | |||||
| hadn't | |||||
| hasn | |||||
| hasn't | |||||
| haven | |||||
| haven't | |||||
| isn | |||||
| isn't | |||||
| ma | |||||
| mightn | |||||
| mightn't | |||||
| mustn | |||||
| mustn't | |||||
| needn | |||||
| needn't | |||||
| shan | |||||
| shan't | |||||
| shouldn | |||||
| shouldn't | |||||
| wasn | |||||
| wasn't | |||||
| weren | |||||
| weren't | |||||
| won | |||||
| won't | |||||
| wouldn | |||||
| wouldn't | |||||
+ 235
- 0
Models+K-Means/nltk_data/corpora/stopwords/finnish
View File
| @@ -0,0 +1,235 @@ | |||||
| olla | |||||
| olen | |||||
| olet | |||||
| on | |||||
| olemme | |||||
| olette | |||||
| ovat | |||||
| ole | |||||
| oli | |||||
| olisi | |||||
| olisit | |||||
| olisin | |||||
| olisimme | |||||
| olisitte | |||||
| olisivat | |||||
| olit | |||||
| olin | |||||
| olimme | |||||
| olitte | |||||
| olivat | |||||
| ollut | |||||
| olleet | |||||
| en | |||||
| et | |||||
| ei | |||||
| emme | |||||
| ette | |||||
| eivät | |||||
| minä | |||||
| minun | |||||
| minut | |||||
| minua | |||||
| minussa | |||||
| minusta | |||||
| minuun | |||||
| minulla | |||||
| minulta | |||||
| minulle | |||||
| sinä | |||||
| sinun | |||||
| sinut | |||||
| sinua | |||||
| sinussa | |||||
| sinusta | |||||
| sinuun | |||||
| sinulla | |||||
| sinulta | |||||
| sinulle | |||||
| hän | |||||
| hänen | |||||
| hänet | |||||
| häntä | |||||
| hänessä | |||||
| hänestä | |||||
| häneen | |||||
| hänellä | |||||
| häneltä | |||||
| hänelle | |||||
| me | |||||
| meidän | |||||
| meidät | |||||
| meitä | |||||
| meissä | |||||
| meistä | |||||
| meihin | |||||
| meillä | |||||
| meiltä | |||||
| meille | |||||
| te | |||||
| teidän | |||||
| teidät | |||||
| teitä | |||||
| teissä | |||||
| teistä | |||||
| teihin | |||||
| teillä | |||||
| teiltä | |||||
| teille | |||||
| he | |||||
| heidän | |||||
| heidät | |||||
| heitä | |||||
| heissä | |||||
| heistä | |||||
| heihin | |||||
| heillä | |||||
| heiltä | |||||
| heille | |||||
| tämä | |||||
| tämän | |||||
| tätä | |||||
| tässä | |||||
| tästä | |||||
| tähän | |||||
| tallä | |||||
| tältä | |||||
| tälle | |||||
| tänä | |||||
| täksi | |||||
| tuo | |||||
| tuon | |||||
| tuotä | |||||
| tuossa | |||||
| tuosta | |||||
| tuohon | |||||
| tuolla | |||||
| tuolta | |||||
| tuolle | |||||
| tuona | |||||
| tuoksi | |||||
| se | |||||
| sen | |||||
| sitä | |||||
| siinä | |||||
| siitä | |||||
| siihen | |||||
| sillä | |||||
| siltä | |||||
| sille | |||||
| sinä | |||||
| siksi | |||||
| nämä | |||||
| näiden | |||||
| näitä | |||||
| näissä | |||||
| näistä | |||||
| näihin | |||||
| näillä | |||||
| näiltä | |||||
| näille | |||||
| näinä | |||||
| näiksi | |||||
| nuo | |||||
| noiden | |||||
| noita | |||||
| noissa | |||||
| noista | |||||
| noihin | |||||
| noilla | |||||
| noilta | |||||
| noille | |||||
| noina | |||||
| noiksi | |||||
| ne | |||||
| niiden | |||||
| niitä | |||||
| niissä | |||||
| niistä | |||||
| niihin | |||||
| niillä | |||||
| niiltä | |||||
| niille | |||||
| niinä | |||||
| niiksi | |||||
| kuka | |||||
| kenen | |||||
| kenet | |||||
| ketä | |||||
| kenessä | |||||
| kenestä | |||||
| keneen | |||||
| kenellä | |||||
| keneltä | |||||
| kenelle | |||||
| kenenä | |||||
| keneksi | |||||
| ketkä | |||||
| keiden | |||||
| ketkä | |||||
| keitä | |||||
| keissä | |||||
| keistä | |||||
| keihin | |||||
| keillä | |||||
| keiltä | |||||
| keille | |||||
| keinä | |||||
| keiksi | |||||
| mikä | |||||
| minkä | |||||
| minkä | |||||
| mitä | |||||
| missä | |||||
| mistä | |||||
| mihin | |||||
| millä | |||||
| miltä | |||||
| mille | |||||
| minä | |||||
| miksi | |||||
| mitkä | |||||
| joka | |||||
| jonka | |||||
| jota | |||||
| jossa | |||||
| josta | |||||
| johon | |||||
| jolla | |||||
| jolta | |||||
| jolle | |||||
| jona | |||||
| joksi | |||||
| jotka | |||||
| joiden | |||||
| joita | |||||
| joissa | |||||
| joista | |||||
| joihin | |||||
| joilla | |||||
| joilta | |||||
| joille | |||||
| joina | |||||
| joiksi | |||||
| että | |||||
| ja | |||||
| jos | |||||
| koska | |||||
| kuin | |||||
| mutta | |||||
| niin | |||||
| sekä | |||||
| sillä | |||||
| tai | |||||
| vaan | |||||
| vai | |||||
| vaikka | |||||
| kanssa | |||||
| mukaan | |||||
| noin | |||||
| poikki | |||||
| yli | |||||
| kun | |||||
| niin | |||||
| nyt | |||||
| itse | |||||
+ 157
- 0
Models+K-Means/nltk_data/corpora/stopwords/french
View File
| @@ -0,0 +1,157 @@ | |||||
| au | |||||
| aux | |||||
| avec | |||||
| ce | |||||
| ces | |||||
| dans | |||||
| de | |||||
| des | |||||
| du | |||||
| elle | |||||
| en | |||||
| et | |||||
| eux | |||||
| il | |||||
| ils | |||||
| je | |||||
| la | |||||
| le | |||||
| les | |||||
| leur | |||||
| lui | |||||
| ma | |||||
| mais | |||||
| me | |||||
| même | |||||
| mes | |||||
| moi | |||||
| mon | |||||
| ne | |||||
| nos | |||||
| notre | |||||
| nous | |||||
| on | |||||
| ou | |||||
| par | |||||
| pas | |||||
| pour | |||||
| qu | |||||
| que | |||||
| qui | |||||
| sa | |||||
| se | |||||
| ses | |||||
| son | |||||
| sur | |||||
| ta | |||||
| te | |||||
| tes | |||||
| toi | |||||
| ton | |||||
| tu | |||||
| un | |||||
| une | |||||
| vos | |||||
| votre | |||||
| vous | |||||
| c | |||||
| d | |||||
| j | |||||
| l | |||||
| à | |||||
| m | |||||
| n | |||||
| s | |||||
| t | |||||
| y | |||||
| été | |||||
| étée | |||||
| étées | |||||
| étés | |||||
| étant | |||||
| étante | |||||
| étants | |||||
| étantes | |||||
| suis | |||||
| es | |||||
| est | |||||
| sommes | |||||
| êtes | |||||
| sont | |||||
| serai | |||||
| seras | |||||
| sera | |||||
| serons | |||||
| serez | |||||
| seront | |||||
| serais | |||||
| serait | |||||
| serions | |||||
| seriez | |||||
| seraient | |||||
| étais | |||||
| était | |||||
| étions | |||||
| étiez | |||||
| étaient | |||||
| fus | |||||
| fut | |||||
| fûmes | |||||
| fûtes | |||||
| furent | |||||
| sois | |||||
| soit | |||||
| soyons | |||||
| soyez | |||||
| soient | |||||
| fusse | |||||
| fusses | |||||
| fût | |||||
| fussions | |||||
| fussiez | |||||
| fussent | |||||
| ayant | |||||
| ayante | |||||
| ayantes | |||||
| ayants | |||||
| eu | |||||
| eue | |||||
| eues | |||||
| eus | |||||
| ai | |||||
| as | |||||
| avons | |||||
| avez | |||||
| ont | |||||
| aurai | |||||
| auras | |||||
| aura | |||||
| aurons | |||||
| aurez | |||||
| auront | |||||
| aurais | |||||
| aurait | |||||
| aurions | |||||
| auriez | |||||
| auraient | |||||
| avais | |||||
| avait | |||||
| avions | |||||
| aviez | |||||
| avaient | |||||
| eut | |||||
| eûmes | |||||
| eûtes | |||||
| eurent | |||||
| aie | |||||
| aies | |||||
| ait | |||||
| ayons | |||||
| ayez | |||||
| aient | |||||
| eusse | |||||
| eusses | |||||
| eût | |||||
| eussions | |||||
| eussiez | |||||
| eussent | |||||
+ 232
- 0
Models+K-Means/nltk_data/corpora/stopwords/german
View File
| @@ -0,0 +1,232 @@ | |||||
| aber | |||||
| alle | |||||
| allem | |||||
| allen | |||||
| aller | |||||
| alles | |||||
| als | |||||
| also | |||||
| am | |||||
| an | |||||
| ander | |||||
| andere | |||||
| anderem | |||||
| anderen | |||||
| anderer | |||||
| anderes | |||||
| anderm | |||||
| andern | |||||
| anderr | |||||
| anders | |||||
| auch | |||||
| auf | |||||
| aus | |||||
| bei | |||||
| bin | |||||
| bis | |||||
| bist | |||||
| da | |||||
| damit | |||||
| dann | |||||
| der | |||||
| den | |||||
| des | |||||
| dem | |||||
| die | |||||
| das | |||||
| dass | |||||
| daß | |||||
| derselbe | |||||
| derselben | |||||
| denselben | |||||
| desselben | |||||
| demselben | |||||
| dieselbe | |||||
| dieselben | |||||
| dasselbe | |||||
| dazu | |||||
| dein | |||||
| deine | |||||
| deinem | |||||
| deinen | |||||
| deiner | |||||
| deines | |||||
| denn | |||||
| derer | |||||
| dessen | |||||
| dich | |||||
| dir | |||||
| du | |||||
| dies | |||||
| diese | |||||
| diesem | |||||
| diesen | |||||
| dieser | |||||
| dieses | |||||
| doch | |||||
| dort | |||||
| durch | |||||
| ein | |||||
| eine | |||||
| einem | |||||
| einen | |||||
| einer | |||||
| eines | |||||
| einig | |||||
| einige | |||||
| einigem | |||||
| einigen | |||||
| einiger | |||||
| einiges | |||||
| einmal | |||||
| er | |||||
| ihn | |||||
| ihm | |||||
| es | |||||
| etwas | |||||
| euer | |||||
| eure | |||||
| eurem | |||||
| euren | |||||
| eurer | |||||
| eures | |||||
| für | |||||
| gegen | |||||
| gewesen | |||||
| hab | |||||
| habe | |||||
| haben | |||||
| hat | |||||
| hatte | |||||
| hatten | |||||
| hier | |||||
| hin | |||||
| hinter | |||||
| ich | |||||
| mich | |||||
| mir | |||||
| ihr | |||||
| ihre | |||||
| ihrem | |||||
| ihren | |||||
| ihrer | |||||
| ihres | |||||
| euch | |||||
| im | |||||
| in | |||||
| indem | |||||
| ins | |||||
| ist | |||||
| jede | |||||
| jedem | |||||
| jeden | |||||
| jeder | |||||
| jedes | |||||
| jene | |||||
| jenem | |||||
| jenen | |||||
| jener | |||||
| jenes | |||||
| jetzt | |||||
| kann | |||||
| kein | |||||
| keine | |||||
| keinem | |||||
| keinen | |||||
| keiner | |||||
| keines | |||||
| können | |||||
| könnte | |||||
| machen | |||||
| man | |||||
| manche | |||||
| manchem | |||||
| manchen | |||||
| mancher | |||||
| manches | |||||
| mein | |||||
| meine | |||||
| meinem | |||||
| meinen | |||||
| meiner | |||||
| meines | |||||
| mit | |||||
| muss | |||||
| musste | |||||
| nach | |||||
| nicht | |||||
| nichts | |||||
| noch | |||||
| nun | |||||
| nur | |||||
| ob | |||||
| oder | |||||
| ohne | |||||
| sehr | |||||
| sein | |||||
| seine | |||||
| seinem | |||||
| seinen | |||||
| seiner | |||||
| seines | |||||
| selbst | |||||
| sich | |||||
| sie | |||||
| ihnen | |||||
| sind | |||||
| so | |||||
| solche | |||||
| solchem | |||||
| solchen | |||||
| solcher | |||||
| solches | |||||
| soll | |||||
| sollte | |||||
| sondern | |||||
| sonst | |||||
| über | |||||
| um | |||||
| und | |||||
| uns | |||||
| unsere | |||||
| unserem | |||||
| unseren | |||||
| unser | |||||
| unseres | |||||
| unter | |||||
| viel | |||||
| vom | |||||
| von | |||||
| vor | |||||
| während | |||||
| war | |||||
| waren | |||||
| warst | |||||
| was | |||||
| weg | |||||
| weil | |||||
| weiter | |||||
| welche | |||||
| welchem | |||||
| welchen | |||||
| welcher | |||||
| welches | |||||
| wenn | |||||
| werde | |||||
| werden | |||||
| wie | |||||
| wieder | |||||
| will | |||||
| wir | |||||
| wird | |||||
| wirst | |||||
| wo | |||||
| wollen | |||||
| wollte | |||||
| würde | |||||
| würden | |||||
| zu | |||||
| zum | |||||
| zur | |||||
| zwar | |||||
| zwischen | |||||
+ 265
- 0
Models+K-Means/nltk_data/corpora/stopwords/greek
View File
| @@ -0,0 +1,265 @@ | |||||
| αλλα | |||||
| αν | |||||
| αντι | |||||
| απο | |||||
| αυτα | |||||
| αυτεσ | |||||
| αυτη | |||||
| αυτο | |||||
| αυτοι | |||||
| αυτοσ | |||||
| αυτουσ | |||||
| αυτων | |||||
| αἱ | |||||
| αἳ | |||||
| αἵ | |||||
| αὐτόσ | |||||
| αὐτὸς | |||||
| αὖ | |||||
| γάρ | |||||
| γα | |||||
| γα^ | |||||
| γε | |||||
| για | |||||
| γοῦν | |||||
| γὰρ | |||||
| δ' | |||||
| δέ | |||||
| δή | |||||
| δαί | |||||
| δαίσ | |||||
| δαὶ | |||||
| δαὶς | |||||
| δε | |||||
| δεν | |||||
| δι' | |||||
| διά | |||||
| διὰ | |||||
| δὲ | |||||
| δὴ | |||||
| δ’ | |||||
| εαν | |||||
| ειμαι | |||||
| ειμαστε | |||||
| ειναι | |||||
| εισαι | |||||
| ειστε | |||||
| εκεινα | |||||
| εκεινεσ | |||||
| εκεινη | |||||
| εκεινο | |||||
| εκεινοι | |||||
| εκεινοσ | |||||
| εκεινουσ | |||||
| εκεινων | |||||
| ενω | |||||
| επ | |||||
| επι | |||||
| εἰ | |||||
| εἰμί | |||||
| εἰμὶ | |||||
| εἰς | |||||
| εἰσ | |||||
| εἴ | |||||
| εἴμι | |||||
| εἴτε | |||||
| η | |||||
| θα | |||||
| ισωσ | |||||
| κ | |||||
| καί | |||||
| καίτοι | |||||
| καθ | |||||
| και | |||||
| κατ | |||||
| κατά | |||||
| κατα | |||||
| κατὰ | |||||
| καὶ | |||||
| κι | |||||
| κἀν | |||||
| κἂν | |||||
| μέν | |||||
| μή | |||||
| μήτε | |||||
| μα | |||||
| με | |||||
| μεθ | |||||
| μετ | |||||
| μετά | |||||
| μετα | |||||
| μετὰ | |||||
| μη | |||||
| μην | |||||
| μἐν | |||||
| μὲν | |||||
| μὴ | |||||
| μὴν | |||||
| να | |||||
| ο | |||||
| οι | |||||
| ομωσ | |||||
| οπωσ | |||||
| οσο | |||||
| οτι | |||||
| οἱ | |||||
| οἳ | |||||
| οἷς | |||||
| οὐ | |||||
| οὐδ | |||||
| οὐδέ | |||||
| οὐδείσ | |||||
| οὐδεὶς | |||||
| οὐδὲ | |||||
| οὐδὲν | |||||
| οὐκ | |||||
| οὐχ | |||||
| οὐχὶ | |||||
| οὓς | |||||
| οὔτε | |||||
| οὕτω | |||||
| οὕτως | |||||
| οὕτωσ | |||||
| οὖν | |||||
| οὗ | |||||
| οὗτος | |||||
| οὗτοσ | |||||
| παρ | |||||
| παρά | |||||
| παρα | |||||
| παρὰ | |||||
| περί | |||||
| περὶ | |||||
| ποια | |||||
| ποιεσ | |||||
| ποιο | |||||
| ποιοι | |||||
| ποιοσ | |||||
| ποιουσ | |||||
| ποιων | |||||
| ποτε | |||||
| που | |||||
| ποῦ | |||||
| προ | |||||
| προσ | |||||
| πρόσ | |||||
| πρὸ | |||||
| πρὸς | |||||
| πως | |||||
| πωσ | |||||
| σε | |||||
| στη | |||||
| στην | |||||
| στο | |||||
| στον | |||||
| σόσ | |||||
| σύ | |||||
| σύν | |||||
| σὸς | |||||
| σὺ | |||||
| σὺν | |||||
| τά | |||||
| τήν | |||||
| τί | |||||
| τίς | |||||
| τίσ | |||||
| τα | |||||
| ταῖς | |||||
| τε | |||||
| την | |||||
| τησ | |||||
| τι | |||||
| τινα | |||||
| τις | |||||
| τισ | |||||
| το | |||||
| τοί | |||||
| τοι | |||||
| τοιοῦτος | |||||
| τοιοῦτοσ | |||||
| τον | |||||
| τοτε | |||||
| του | |||||
| τούσ | |||||
| τοὺς | |||||
| τοῖς | |||||
| τοῦ | |||||
| των | |||||
| τό | |||||
| τόν | |||||
| τότε | |||||
| τὰ | |||||
| τὰς | |||||
| τὴν | |||||
| τὸ | |||||
| τὸν | |||||
| τῆς | |||||
| τῆσ | |||||
| τῇ | |||||
| τῶν | |||||
| τῷ | |||||
| ωσ | |||||
| ἀλλ' | |||||
| ἀλλά | |||||
| ἀλλὰ | |||||
| ἀλλ’ | |||||
| ἀπ | |||||
| ἀπό | |||||
| ἀπὸ | |||||
| ἀφ | |||||
| ἂν | |||||
| ἃ | |||||
| ἄλλος | |||||
| ἄλλοσ | |||||
| ἄν | |||||
| ἄρα | |||||
| ἅμα | |||||
| ἐάν | |||||
| ἐγώ | |||||
| ἐγὼ | |||||
| ἐκ | |||||
| ἐμόσ | |||||
| ἐμὸς | |||||
| ἐν | |||||
| ἐξ | |||||
| ἐπί | |||||
| ἐπεὶ | |||||
| ἐπὶ | |||||
| ἐστι | |||||
| ἐφ | |||||
| ἐὰν | |||||
| ἑαυτοῦ | |||||
| ἔτι | |||||
| ἡ | |||||
| ἢ | |||||
| ἣ | |||||
| ἤ | |||||
| ἥ | |||||
| ἧς | |||||
| ἵνα | |||||
| ὁ | |||||
| ὃ | |||||
| ὃν | |||||
| ὃς | |||||
| ὅ | |||||
| ὅδε | |||||
| ὅθεν | |||||
| ὅπερ | |||||
| ὅς | |||||
| ὅσ | |||||
| ὅστις | |||||
| ὅστισ | |||||
| ὅτε | |||||
| ὅτι | |||||
| ὑμόσ | |||||
| ὑπ | |||||
| ὑπέρ | |||||
| ὑπό | |||||
| ὑπὲρ | |||||
| ὑπὸ | |||||
| ὡς | |||||
| ὡσ | |||||
| ὥς | |||||
| ὥστε | |||||
| ὦ | |||||
| ᾧ | |||||
+ 221
- 0
Models+K-Means/nltk_data/corpora/stopwords/hebrew
View File
| @@ -0,0 +1,221 @@ | |||||
| אני | |||||
| את | |||||
| אתה | |||||
| אנחנו | |||||
| אתן | |||||
| אתם | |||||
| הם | |||||
| הן | |||||
| היא | |||||
| הוא | |||||
| שלי | |||||
| שלו | |||||
| שלך | |||||
| שלה | |||||
| שלנו | |||||
| שלכם | |||||
| שלכן | |||||
| שלהם | |||||
| שלהן | |||||
| לי | |||||
| לו | |||||
| לה | |||||
| לנו | |||||
| לכם | |||||
| לכן | |||||
| להם | |||||
| להן | |||||
| אותה | |||||
| אותו | |||||
| זה | |||||
| זאת | |||||
| אלה | |||||
| אלו | |||||
| תחת | |||||
| מתחת | |||||
| מעל | |||||
| בין | |||||
| עם | |||||
| עד | |||||
| נגר | |||||
| על | |||||
| אל | |||||
| מול | |||||
| של | |||||
| אצל | |||||
| כמו | |||||
| אחר | |||||
| אותו | |||||
| בלי | |||||
| לפני | |||||
| אחרי | |||||
| מאחורי | |||||
| עלי | |||||
| עליו | |||||
| עליה | |||||
| עליך | |||||
| עלינו | |||||
| עליכם | |||||
| לעיכן | |||||
| עליהם | |||||
| עליהן | |||||
| כל | |||||
| כולם | |||||
| כולן | |||||
| כך | |||||
| ככה | |||||
| כזה | |||||
| זה | |||||
| זות | |||||
| אותי | |||||
| אותה | |||||
| אותם | |||||
| אותך | |||||
| אותו | |||||
| אותן | |||||
| אותנו | |||||
| ואת | |||||
| את | |||||
| אתכם | |||||
| אתכן | |||||
| איתי | |||||
| איתו | |||||
| איתך | |||||
| איתה | |||||
| איתם | |||||
| איתן | |||||
| איתנו | |||||
| איתכם | |||||
| איתכן | |||||
| יהיה | |||||
| תהיה | |||||
| היתי | |||||
| היתה | |||||
| היה | |||||
| להיות | |||||
| עצמי | |||||
| עצמו | |||||
| עצמה | |||||
| עצמם | |||||
| עצמן | |||||
| עצמנו | |||||
| עצמהם | |||||
| עצמהן | |||||
| מי | |||||
| מה | |||||
| איפה | |||||
| היכן | |||||
| במקום שבו | |||||
| אם | |||||
| לאן | |||||
| למקום שבו | |||||
| מקום בו | |||||
| איזה | |||||
| מהיכן | |||||
| איך | |||||
| כיצד | |||||
| באיזו מידה | |||||
| מתי | |||||
| בשעה ש | |||||
| כאשר | |||||
| כש | |||||
| למרות | |||||
| לפני | |||||
| אחרי | |||||
| מאיזו סיבה | |||||
| הסיבה שבגללה | |||||
| למה | |||||
| מדוע | |||||
| לאיזו תכלית | |||||
| כי | |||||
| יש | |||||
| אין | |||||
| אך | |||||
| מנין | |||||
| מאין | |||||
| מאיפה | |||||
| יכל | |||||
| יכלה | |||||
| יכלו | |||||
| יכול | |||||
| יכולה | |||||
| יכולים | |||||
| יכולות | |||||
| יוכלו | |||||
| יוכל | |||||
| מסוגל | |||||
| לא | |||||
| רק | |||||
| אולי | |||||
| אין | |||||
| לאו | |||||
| אי | |||||
| כלל | |||||
| נגד | |||||
| אם | |||||
| עם | |||||
| אל | |||||
| אלה | |||||
| אלו | |||||
| אף | |||||
| על | |||||
| מעל | |||||
| מתחת | |||||
| מצד | |||||
| בשביל | |||||
| לבין | |||||
| באמצע | |||||
| בתוך | |||||
| דרך | |||||
| מבעד | |||||
| באמצעות | |||||
| למעלה | |||||
| למטה | |||||
| מחוץ | |||||
| מן | |||||
| לעבר | |||||
| מכאן | |||||
| כאן | |||||
| הנה | |||||
| הרי | |||||
| פה | |||||
| שם | |||||
| אך | |||||
| ברם | |||||
| שוב | |||||
| אבל | |||||
| מבלי | |||||
| בלי | |||||
| מלבד | |||||
| רק | |||||
| בגלל | |||||
| מכיוון | |||||
| עד | |||||
| אשר | |||||
| ואילו | |||||
| למרות | |||||
| אס | |||||
| כמו | |||||
| כפי | |||||
| אז | |||||
| אחרי | |||||
| כן | |||||
| לכן | |||||
| לפיכך | |||||
| מאד | |||||
| עז | |||||
| מעט | |||||
| מעטים | |||||
| במידה | |||||
| שוב | |||||
| יותר | |||||
| מדי | |||||
| גם | |||||
| כן | |||||
| נו | |||||
| אחר | |||||
| אחרת | |||||
| אחרים | |||||
| אחרות | |||||
| אשר | |||||
| או | |||||
+ 1036
- 0
Models+K-Means/nltk_data/corpora/stopwords/hinglish
File diff suppressed because it is too large
View File
+ 199
- 0
Models+K-Means/nltk_data/corpora/stopwords/hungarian
View File
| @@ -0,0 +1,199 @@ | |||||
| a | |||||
| ahogy | |||||
| ahol | |||||
| aki | |||||
| akik | |||||
| akkor | |||||
| alatt | |||||
| által | |||||
| általában | |||||
| amely | |||||
| amelyek | |||||
| amelyekben | |||||
| amelyeket | |||||
| amelyet | |||||
| amelynek | |||||
| ami | |||||
| amit | |||||
| amolyan | |||||
| amíg | |||||
| amikor | |||||
| át | |||||
| abban | |||||
| ahhoz | |||||
| annak | |||||
| arra | |||||
| arról | |||||
| az | |||||
| azok | |||||
| azon | |||||
| azt | |||||
| azzal | |||||
| azért | |||||
| aztán | |||||
| azután | |||||
| azonban | |||||
| bár | |||||
| be | |||||
| belül | |||||
| benne | |||||
| cikk | |||||
| cikkek | |||||
| cikkeket | |||||
| csak | |||||
| de | |||||
| e | |||||
| eddig | |||||
| egész | |||||
| egy | |||||
| egyes | |||||
| egyetlen | |||||
| egyéb | |||||
| egyik | |||||
| egyre | |||||
| ekkor | |||||
| el | |||||
| elég | |||||
| ellen | |||||
| elõ | |||||
| elõször | |||||
| elõtt | |||||
| elsõ | |||||
| én | |||||
| éppen | |||||
| ebben | |||||
| ehhez | |||||
| emilyen | |||||
| ennek | |||||
| erre | |||||
| ez | |||||
| ezt | |||||
| ezek | |||||
| ezen | |||||
| ezzel | |||||
| ezért | |||||
| és | |||||
| fel | |||||
| felé | |||||
| hanem | |||||
| hiszen | |||||
| hogy | |||||
| hogyan | |||||
| igen | |||||
| így | |||||
| illetve | |||||
| ill. | |||||
| ill | |||||
| ilyen | |||||
| ilyenkor | |||||
| ison | |||||
| ismét | |||||
| itt | |||||
| jó | |||||
| jól | |||||
| jobban | |||||
| kell | |||||
| kellett | |||||
| keresztül | |||||
| keressünk | |||||
| ki | |||||
| kívül | |||||
| között | |||||
| közül | |||||
| legalább | |||||
| lehet | |||||
| lehetett | |||||
| legyen | |||||
| lenne | |||||
| lenni | |||||
| lesz | |||||
| lett | |||||
| maga | |||||
| magát | |||||
| majd | |||||
| majd | |||||
| már | |||||
| más | |||||
| másik | |||||
| meg | |||||
| még | |||||
| mellett | |||||
| mert | |||||
| mely | |||||
| melyek | |||||
| mi | |||||
| mit | |||||
| míg | |||||
| miért | |||||
| milyen | |||||
| mikor | |||||
| minden | |||||
| mindent | |||||
| mindenki | |||||
| mindig | |||||
| mint | |||||
| mintha | |||||
| mivel | |||||
| most | |||||
| nagy | |||||
| nagyobb | |||||
| nagyon | |||||
| ne | |||||
| néha | |||||
| nekem | |||||
| neki | |||||
| nem | |||||
| néhány | |||||
| nélkül | |||||
| nincs | |||||
| olyan | |||||
| ott | |||||
| össze | |||||
| õ | |||||
| õk | |||||
| õket | |||||
| pedig | |||||
| persze | |||||
| rá | |||||
| s | |||||
| saját | |||||
| sem | |||||
| semmi | |||||
| sok | |||||
| sokat | |||||
| sokkal | |||||
| számára | |||||
| szemben | |||||
| szerint | |||||
| szinte | |||||
| talán | |||||
| tehát | |||||
| teljes | |||||
| tovább | |||||
| továbbá | |||||
| több | |||||
| úgy | |||||
| ugyanis | |||||
| új | |||||
| újabb | |||||
| újra | |||||
| után | |||||
| utána | |||||
| utolsó | |||||
| vagy | |||||
| vagyis | |||||
| valaki | |||||
| valami | |||||
| valamint | |||||
| való | |||||
| vagyok | |||||
| van | |||||
| vannak | |||||
| volt | |||||
| voltam | |||||
| voltak | |||||
| voltunk | |||||
| vissza | |||||
| vele | |||||
| viszont | |||||
| volna | |||||
+ 758
- 0
Models+K-Means/nltk_data/corpora/stopwords/indonesian
View File
| @@ -0,0 +1,758 @@ | |||||
| ada | |||||
| adalah | |||||
| adanya | |||||
| adapun | |||||
| agak | |||||
| agaknya | |||||
| agar | |||||
| akan | |||||
| akankah | |||||
| akhir | |||||
| akhiri | |||||
| akhirnya | |||||
| aku | |||||
| akulah | |||||
| amat | |||||
| amatlah | |||||
| anda | |||||
| andalah | |||||
| antar | |||||
| antara | |||||
| antaranya | |||||
| apa | |||||
| apaan | |||||
| apabila | |||||
| apakah | |||||
| apalagi | |||||
| apatah | |||||
| artinya | |||||
| asal | |||||
| asalkan | |||||
| atas | |||||
| atau | |||||
| ataukah | |||||
| ataupun | |||||
| awal | |||||
| awalnya | |||||
| bagai | |||||
| bagaikan | |||||
| bagaimana | |||||
| bagaimanakah | |||||
| bagaimanapun | |||||
| bagi | |||||
| bagian | |||||
| bahkan | |||||
| bahwa | |||||
| bahwasanya | |||||
| baik | |||||
| bakal | |||||
| bakalan | |||||
| balik | |||||
| banyak | |||||
| bapak | |||||
| baru | |||||
| bawah | |||||
| beberapa | |||||
| begini | |||||
| beginian | |||||
| beginikah | |||||
| beginilah | |||||
| begitu | |||||
| begitukah | |||||
| begitulah | |||||
| begitupun | |||||
| bekerja | |||||
| belakang | |||||
| belakangan | |||||
| belum | |||||
| belumlah | |||||
| benar | |||||
| benarkah | |||||
| benarlah | |||||
| berada | |||||
| berakhir | |||||
| berakhirlah | |||||
| berakhirnya | |||||
| berapa | |||||
| berapakah | |||||
| berapalah | |||||
| berapapun | |||||
| berarti | |||||
| berawal | |||||
| berbagai | |||||
| berdatangan | |||||
| beri | |||||
| berikan | |||||
| berikut | |||||
| berikutnya | |||||
| berjumlah | |||||
| berkali-kali | |||||
| berkata | |||||
| berkehendak | |||||
| berkeinginan | |||||
| berkenaan | |||||
| berlainan | |||||
| berlalu | |||||
| berlangsung | |||||
| berlebihan | |||||
| bermacam | |||||
| bermacam-macam | |||||
| bermaksud | |||||
| bermula | |||||
| bersama | |||||
| bersama-sama | |||||
| bersiap | |||||
| bersiap-siap | |||||
| bertanya | |||||
| bertanya-tanya | |||||
| berturut | |||||
| berturut-turut | |||||
| bertutur | |||||
| berujar | |||||
| berupa | |||||
| besar | |||||
| betul | |||||
| betulkah | |||||
| biasa | |||||
| biasanya | |||||
| bila | |||||
| bilakah | |||||
| bisa | |||||
| bisakah | |||||
| boleh | |||||
| bolehkah | |||||
| bolehlah | |||||
| buat | |||||
| bukan | |||||
| bukankah | |||||
| bukanlah | |||||
| bukannya | |||||
| bulan | |||||
| bung | |||||
| cara | |||||
| caranya | |||||
| cukup | |||||
| cukupkah | |||||
| cukuplah | |||||
| cuma | |||||
| dahulu | |||||
| dalam | |||||
| dan | |||||
| dapat | |||||
| dari | |||||
| daripada | |||||
| datang | |||||
| dekat | |||||
| demi | |||||
| demikian | |||||
| demikianlah | |||||
| dengan | |||||
| depan | |||||
| di | |||||
| dia | |||||
| diakhiri | |||||
| diakhirinya | |||||
| dialah | |||||
| diantara | |||||
| diantaranya | |||||
| diberi | |||||
| diberikan | |||||
| diberikannya | |||||
| dibuat | |||||
| dibuatnya | |||||
| didapat | |||||
| didatangkan | |||||
| digunakan | |||||
| diibaratkan | |||||
| diibaratkannya | |||||
| diingat | |||||
| diingatkan | |||||
| diinginkan | |||||
| dijawab | |||||
| dijelaskan | |||||
| dijelaskannya | |||||
| dikarenakan | |||||
| dikatakan | |||||
| dikatakannya | |||||
| dikerjakan | |||||
| diketahui | |||||
| diketahuinya | |||||
| dikira | |||||
| dilakukan | |||||
| dilalui | |||||
| dilihat | |||||
| dimaksud | |||||
| dimaksudkan | |||||
| dimaksudkannya | |||||
| dimaksudnya | |||||
| diminta | |||||
| dimintai | |||||
| dimisalkan | |||||
| dimulai | |||||
| dimulailah | |||||
| dimulainya | |||||
| dimungkinkan | |||||
| dini | |||||
| dipastikan | |||||
| diperbuat | |||||
| diperbuatnya | |||||
| dipergunakan | |||||
| diperkirakan | |||||
| diperlihatkan | |||||
| diperlukan | |||||
| diperlukannya | |||||
| dipersoalkan | |||||
| dipertanyakan | |||||
| dipunyai | |||||
| diri | |||||
| dirinya | |||||
| disampaikan | |||||
| disebut | |||||
| disebutkan | |||||
| disebutkannya | |||||
| disini | |||||
| disinilah | |||||
| ditambahkan | |||||
| ditandaskan | |||||
| ditanya | |||||
| ditanyai | |||||
| ditanyakan | |||||
| ditegaskan | |||||
| ditujukan | |||||
| ditunjuk | |||||
| ditunjuki | |||||
| ditunjukkan | |||||
| ditunjukkannya | |||||
| ditunjuknya | |||||
| dituturkan | |||||
| dituturkannya | |||||
| diucapkan | |||||
| diucapkannya | |||||
| diungkapkan | |||||
| dong | |||||
| dua | |||||
| dulu | |||||
| empat | |||||
| enggak | |||||
| enggaknya | |||||
| entah | |||||
| entahlah | |||||
| guna | |||||
| gunakan | |||||
| hal | |||||
| hampir | |||||
| hanya | |||||
| hanyalah | |||||
| hari | |||||
| harus | |||||
| haruslah | |||||
| harusnya | |||||
| hendak | |||||
| hendaklah | |||||
| hendaknya | |||||
| hingga | |||||
| ia | |||||
| ialah | |||||
| ibarat | |||||
| ibaratkan | |||||
| ibaratnya | |||||
| ibu | |||||
| ikut | |||||
| ingat | |||||
| ingat-ingat | |||||
| ingin | |||||
| inginkah | |||||
| inginkan | |||||
| ini | |||||
| inikah | |||||
| inilah | |||||
| itu | |||||
| itukah | |||||
| itulah | |||||
| jadi | |||||
| jadilah | |||||
| jadinya | |||||
| jangan | |||||
| jangankan | |||||
| janganlah | |||||
| jauh | |||||
| jawab | |||||
| jawaban | |||||
| jawabnya | |||||
| jelas | |||||
| jelaskan | |||||
| jelaslah | |||||
| jelasnya | |||||
| jika | |||||
| jikalau | |||||
| juga | |||||
| jumlah | |||||
| jumlahnya | |||||
| justru | |||||
| kala | |||||
| kalau | |||||
| kalaulah | |||||
| kalaupun | |||||
| kalian | |||||
| kami | |||||
| kamilah | |||||
| kamu | |||||
| kamulah | |||||
| kan | |||||
| kapan | |||||
| kapankah | |||||
| kapanpun | |||||
| karena | |||||
| karenanya | |||||
| kasus | |||||
| kata | |||||
| katakan | |||||
| katakanlah | |||||
| katanya | |||||
| ke | |||||
| keadaan | |||||
| kebetulan | |||||
| kecil | |||||
| kedua | |||||
| keduanya | |||||
| keinginan | |||||
| kelamaan | |||||
| kelihatan | |||||
| kelihatannya | |||||
| kelima | |||||
| keluar | |||||
| kembali | |||||
| kemudian | |||||
| kemungkinan | |||||
| kemungkinannya | |||||
| kenapa | |||||
| kepada | |||||
| kepadanya | |||||
| kesampaian | |||||
| keseluruhan | |||||
| keseluruhannya | |||||
| keterlaluan | |||||
| ketika | |||||
| khususnya | |||||
| kini | |||||
| kinilah | |||||
| kira | |||||
| kira-kira | |||||
| kiranya | |||||
| kita | |||||
| kitalah | |||||
| kok | |||||
| kurang | |||||
| lagi | |||||
| lagian | |||||
| lah | |||||
| lain | |||||
| lainnya | |||||
| lalu | |||||
| lama | |||||
| lamanya | |||||
| lanjut | |||||
| lanjutnya | |||||
| lebih | |||||
| lewat | |||||
| lima | |||||
| luar | |||||
| macam | |||||
| maka | |||||
| makanya | |||||
| makin | |||||
| malah | |||||
| malahan | |||||
| mampu | |||||
| mampukah | |||||
| mana | |||||
| manakala | |||||
| manalagi | |||||
| masa | |||||
| masalah | |||||
| masalahnya | |||||
| masih | |||||
| masihkah | |||||
| masing | |||||
| masing-masing | |||||
| mau | |||||
| maupun | |||||
| melainkan | |||||
| melakukan | |||||
| melalui | |||||
| melihat | |||||
| melihatnya | |||||
| memang | |||||
| memastikan | |||||
| memberi | |||||
| memberikan | |||||
| membuat | |||||
| memerlukan | |||||
| memihak | |||||
| meminta | |||||
| memintakan | |||||
| memisalkan | |||||
| memperbuat | |||||
| mempergunakan | |||||
| memperkirakan | |||||
| memperlihatkan | |||||
| mempersiapkan | |||||
| mempersoalkan | |||||
| mempertanyakan | |||||
| mempunyai | |||||
| memulai | |||||
| memungkinkan | |||||
| menaiki | |||||
| menambahkan | |||||
| menandaskan | |||||
| menanti | |||||
| menanti-nanti | |||||
| menantikan | |||||
| menanya | |||||
| menanyai | |||||
| menanyakan | |||||
| mendapat | |||||
| mendapatkan | |||||
| mendatang | |||||
| mendatangi | |||||
| mendatangkan | |||||
| menegaskan | |||||
| mengakhiri | |||||
| mengapa | |||||
| mengatakan | |||||
| mengatakannya | |||||
| mengenai | |||||
| mengerjakan | |||||
| mengetahui | |||||
| menggunakan | |||||
| menghendaki | |||||
| mengibaratkan | |||||
| mengibaratkannya | |||||
| mengingat | |||||
| mengingatkan | |||||
| menginginkan | |||||
| mengira | |||||
| mengucapkan | |||||
| mengucapkannya | |||||
| mengungkapkan | |||||
| menjadi | |||||
| menjawab | |||||
| menjelaskan | |||||
| menuju | |||||
| menunjuk | |||||
| menunjuki | |||||
| menunjukkan | |||||
| menunjuknya | |||||
| menurut | |||||
| menuturkan | |||||
| menyampaikan | |||||
| menyangkut | |||||
| menyatakan | |||||
| menyebutkan | |||||
| menyeluruh | |||||
| menyiapkan | |||||
| merasa | |||||
| mereka | |||||
| merekalah | |||||
| merupakan | |||||
| meski | |||||
| meskipun | |||||
| meyakini | |||||
| meyakinkan | |||||
| minta | |||||
| mirip | |||||
| misal | |||||
| misalkan | |||||
| misalnya | |||||
| mula | |||||
| mulai | |||||
| mulailah | |||||
| mulanya | |||||
| mungkin | |||||
| mungkinkah | |||||
| nah | |||||
| naik | |||||
| namun | |||||
| nanti | |||||
| nantinya | |||||
| nyaris | |||||
| nyatanya | |||||
| oleh | |||||
| olehnya | |||||
| pada | |||||
| padahal | |||||
| padanya | |||||
| pak | |||||
| paling | |||||
| panjang | |||||
| pantas | |||||
| para | |||||
| pasti | |||||
| pastilah | |||||
| penting | |||||
| pentingnya | |||||
| per | |||||
| percuma | |||||
| perlu | |||||
| perlukah | |||||
| perlunya | |||||
| pernah | |||||
| persoalan | |||||
| pertama | |||||
| pertama-tama | |||||
| pertanyaan | |||||
| pertanyakan | |||||
| pihak | |||||
| pihaknya | |||||
| pukul | |||||
| pula | |||||
| pun | |||||
| punya | |||||
| rasa | |||||
| rasanya | |||||
| rata | |||||
| rupanya | |||||
| saat | |||||
| saatnya | |||||
| saja | |||||
| sajalah | |||||
| saling | |||||
| sama | |||||
| sama-sama | |||||
| sambil | |||||
| sampai | |||||
| sampai-sampai | |||||
| sampaikan | |||||
| sana | |||||
| sangat | |||||
| sangatlah | |||||
| satu | |||||
| saya | |||||
| sayalah | |||||
| se | |||||
| sebab | |||||
| sebabnya | |||||
| sebagai | |||||
| sebagaimana | |||||
| sebagainya | |||||
| sebagian | |||||
| sebaik | |||||
| sebaik-baiknya | |||||
| sebaiknya | |||||
| sebaliknya | |||||
| sebanyak | |||||
| sebegini | |||||
| sebegitu | |||||
| sebelum | |||||
| sebelumnya | |||||
| sebenarnya | |||||
| seberapa | |||||
| sebesar | |||||
| sebetulnya | |||||
| sebisanya | |||||
| sebuah | |||||
| sebut | |||||
| sebutlah | |||||
| sebutnya | |||||
| secara | |||||
| secukupnya | |||||
| sedang | |||||
| sedangkan | |||||
| sedemikian | |||||
| sedikit | |||||
| sedikitnya | |||||
| seenaknya | |||||
| segala | |||||
| segalanya | |||||
| segera | |||||
| seharusnya | |||||
| sehingga | |||||
| seingat | |||||
| sejak | |||||
| sejauh | |||||
| sejenak | |||||
| sejumlah | |||||
| sekadar | |||||
| sekadarnya | |||||
| sekali | |||||
| sekali-kali | |||||
| sekalian | |||||
| sekaligus | |||||
| sekalipun | |||||
| sekarang | |||||
| sekarang | |||||
| sekecil | |||||
| seketika | |||||
| sekiranya | |||||
| sekitar | |||||
| sekitarnya | |||||
| sekurang-kurangnya | |||||
| sekurangnya | |||||
| sela | |||||
| selain | |||||
| selaku | |||||
| selalu | |||||
| selama | |||||
| selama-lamanya | |||||
| selamanya | |||||
| selanjutnya | |||||
| seluruh | |||||
| seluruhnya | |||||
| semacam | |||||
| semakin | |||||
| semampu | |||||
| semampunya | |||||
| semasa | |||||
| semasih | |||||
| semata | |||||
| semata-mata | |||||
| semaunya | |||||
| sementara | |||||
| semisal | |||||
| semisalnya | |||||
| sempat | |||||
| semua | |||||
| semuanya | |||||
| semula | |||||
| sendiri | |||||
| sendirian | |||||
| sendirinya | |||||
| seolah | |||||
| seolah-olah | |||||
| seorang | |||||
| sepanjang | |||||
| sepantasnya | |||||
| sepantasnyalah | |||||
| seperlunya | |||||
| seperti | |||||
| sepertinya | |||||
| sepihak | |||||
| sering | |||||
| seringnya | |||||
| serta | |||||
| serupa | |||||
| sesaat | |||||
| sesama | |||||
| sesampai | |||||
| sesegera | |||||
| sesekali | |||||
| seseorang | |||||
| sesuatu | |||||
| sesuatunya | |||||
| sesudah | |||||
| sesudahnya | |||||
| setelah | |||||
| setempat | |||||
| setengah | |||||
| seterusnya | |||||
| setiap | |||||
| setiba | |||||
| setibanya | |||||
| setidak-tidaknya | |||||
| setidaknya | |||||
| setinggi | |||||
| seusai | |||||
| sewaktu | |||||
| siap | |||||
| siapa | |||||
| siapakah | |||||
| siapapun | |||||
| sini | |||||
| sinilah | |||||
| soal | |||||
| soalnya | |||||
| suatu | |||||
| sudah | |||||
| sudahkah | |||||
| sudahlah | |||||
| supaya | |||||
| tadi | |||||
| tadinya | |||||
| tahu | |||||
| tahun | |||||
| tak | |||||
| tambah | |||||
| tambahnya | |||||
| tampak | |||||
| tampaknya | |||||
| tandas | |||||
| tandasnya | |||||
| tanpa | |||||
| tanya | |||||
| tanyakan | |||||
| tanyanya | |||||
| tapi | |||||
| tegas | |||||
| tegasnya | |||||
| telah | |||||
| tempat | |||||
| tengah | |||||
| tentang | |||||
| tentu | |||||
| tentulah | |||||
| tentunya | |||||
| tepat | |||||
| terakhir | |||||
| terasa | |||||
| terbanyak | |||||
| terdahulu | |||||
| terdapat | |||||
| terdiri | |||||
| terhadap | |||||
| terhadapnya | |||||
| teringat | |||||
| teringat-ingat | |||||
| terjadi | |||||
| terjadilah | |||||
| terjadinya | |||||
| terkira | |||||
| terlalu | |||||
| terlebih | |||||
| terlihat | |||||
| termasuk | |||||
| ternyata | |||||
| tersampaikan | |||||
| tersebut | |||||
| tersebutlah | |||||
| tertentu | |||||
| tertuju | |||||
| terus | |||||
| terutama | |||||
| tetap | |||||
| tetapi | |||||
| tiap | |||||
| tiba | |||||
| tiba-tiba | |||||
| tidak | |||||
| tidakkah | |||||
| tidaklah | |||||
| tiga | |||||
| tinggi | |||||
| toh | |||||
| tunjuk | |||||
| turut | |||||
| tutur | |||||
| tuturnya | |||||
| ucap | |||||
| ucapnya | |||||
| ujar | |||||
| ujarnya | |||||
| umum | |||||
| umumnya | |||||
| ungkap | |||||
| ungkapnya | |||||
| untuk | |||||
| usah | |||||
| usai | |||||
| waduh | |||||
| wah | |||||
| wahai | |||||
| waktu | |||||
| waktunya | |||||
| walau | |||||
| walaupun | |||||
| wong | |||||
| yaitu | |||||
| yakin | |||||
| yakni | |||||
| yang | |||||
+ 279
- 0
Models+K-Means/nltk_data/corpora/stopwords/italian
View File
| @@ -0,0 +1,279 @@ | |||||
| ad | |||||
| al | |||||
| allo | |||||
| ai | |||||
| agli | |||||
| all | |||||
| agl | |||||
| alla | |||||
| alle | |||||
| con | |||||
| col | |||||
| coi | |||||
| da | |||||
| dal | |||||
| dallo | |||||
| dai | |||||
| dagli | |||||
| dall | |||||
| dagl | |||||
| dalla | |||||
| dalle | |||||
| di | |||||
| del | |||||
| dello | |||||
| dei | |||||
| degli | |||||
| dell | |||||
| degl | |||||
| della | |||||
| delle | |||||
| in | |||||
| nel | |||||
| nello | |||||
| nei | |||||
| negli | |||||
| nell | |||||
| negl | |||||
| nella | |||||
| nelle | |||||
| su | |||||
| sul | |||||
| sullo | |||||
| sui | |||||
| sugli | |||||
| sull | |||||
| sugl | |||||
| sulla | |||||
| sulle | |||||
| per | |||||
| tra | |||||
| contro | |||||
| io | |||||
| tu | |||||
| lui | |||||
| lei | |||||
| noi | |||||
| voi | |||||
| loro | |||||
| mio | |||||
| mia | |||||
| miei | |||||
| mie | |||||
| tuo | |||||
| tua | |||||
| tuoi | |||||
| tue | |||||
| suo | |||||
| sua | |||||
| suoi | |||||
| sue | |||||
| nostro | |||||
| nostra | |||||
| nostri | |||||
| nostre | |||||
| vostro | |||||
| vostra | |||||
| vostri | |||||
| vostre | |||||
| mi | |||||
| ti | |||||
| ci | |||||
| vi | |||||
| lo | |||||
| la | |||||
| li | |||||
| le | |||||
| gli | |||||
| ne | |||||
| il | |||||
| un | |||||
| uno | |||||
| una | |||||
| ma | |||||
| ed | |||||
| se | |||||
| perché | |||||
| anche | |||||
| come | |||||
| dov | |||||
| dove | |||||
| che | |||||
| chi | |||||
| cui | |||||
| non | |||||
| più | |||||
| quale | |||||
| quanto | |||||
| quanti | |||||
| quanta | |||||
| quante | |||||
| quello | |||||
| quelli | |||||
| quella | |||||
| quelle | |||||
| questo | |||||
| questi | |||||
| questa | |||||
| queste | |||||
| si | |||||
| tutto | |||||
| tutti | |||||
| a | |||||
| c | |||||
| e | |||||
| i | |||||
| l | |||||
| o | |||||
| ho | |||||
| hai | |||||
| ha | |||||
| abbiamo | |||||
| avete | |||||
| hanno | |||||
| abbia | |||||
| abbiate | |||||
| abbiano | |||||
| avrò | |||||
| avrai | |||||
| avrà | |||||
| avremo | |||||
| avrete | |||||
| avranno | |||||
| avrei | |||||
| avresti | |||||
| avrebbe | |||||
| avremmo | |||||
| avreste | |||||
| avrebbero | |||||
| avevo | |||||
| avevi | |||||
| aveva | |||||
| avevamo | |||||
| avevate | |||||
| avevano | |||||
| ebbi | |||||
| avesti | |||||
| ebbe | |||||
| avemmo | |||||
| aveste | |||||
| ebbero | |||||
| avessi | |||||
| avesse | |||||
| avessimo | |||||
| avessero | |||||
| avendo | |||||
| avuto | |||||
| avuta | |||||
| avuti | |||||
| avute | |||||
| sono | |||||
| sei | |||||
| è | |||||
| siamo | |||||
| siete | |||||
| sia | |||||
| siate | |||||
| siano | |||||
| sarò | |||||
| sarai | |||||
| sarà | |||||
| saremo | |||||
| sarete | |||||
| saranno | |||||
| sarei | |||||
| saresti | |||||
| sarebbe | |||||
| saremmo | |||||
| sareste | |||||
| sarebbero | |||||
| ero | |||||
| eri | |||||
| era | |||||
| eravamo | |||||
| eravate | |||||
| erano | |||||
| fui | |||||
| fosti | |||||
| fu | |||||
| fummo | |||||
| foste | |||||
| furono | |||||
| fossi | |||||
| fosse | |||||
| fossimo | |||||
| fossero | |||||
| essendo | |||||
| faccio | |||||
| fai | |||||
| facciamo | |||||
| fanno | |||||
| faccia | |||||
| facciate | |||||
| facciano | |||||
| farò | |||||
| farai | |||||
| farà | |||||
| faremo | |||||
| farete | |||||
| faranno | |||||
| farei | |||||
| faresti | |||||
| farebbe | |||||
| faremmo | |||||
| fareste | |||||
| farebbero | |||||
| facevo | |||||
| facevi | |||||
| faceva | |||||
| facevamo | |||||
| facevate | |||||
| facevano | |||||
| feci | |||||
| facesti | |||||
| fece | |||||
| facemmo | |||||
| faceste | |||||
| fecero | |||||
| facessi | |||||
| facesse | |||||
| facessimo | |||||
| facessero | |||||
| facendo | |||||
| sto | |||||
| stai | |||||
| sta | |||||
| stiamo | |||||
| stanno | |||||
| stia | |||||
| stiate | |||||
| stiano | |||||
| starò | |||||
| starai | |||||
| starà | |||||
| staremo | |||||
| starete | |||||
| staranno | |||||
| starei | |||||
| staresti | |||||
| starebbe | |||||
| staremmo | |||||
| stareste | |||||
| starebbero | |||||
| stavo | |||||
| stavi | |||||
| stava | |||||
| stavamo | |||||
| stavate | |||||
| stavano | |||||
| stetti | |||||
| stesti | |||||
| stette | |||||
| stemmo | |||||
| steste | |||||
| stettero | |||||
| stessi | |||||
| stesse | |||||
| stessimo | |||||
| stessero | |||||
| stando | |||||
+ 380
- 0
Models+K-Means/nltk_data/corpora/stopwords/kazakh
View File
| @@ -0,0 +1,380 @@ | |||||
| ах | |||||
| ох | |||||
| эх | |||||
| ай | |||||
| эй | |||||
| ой | |||||
| тағы | |||||
| тағыда | |||||
| әрине | |||||
| жоқ | |||||
| сондай | |||||
| осындай | |||||
| осылай | |||||
| солай | |||||
| мұндай | |||||
| бұндай | |||||
| мен | |||||
| сен | |||||
| ол | |||||
| біз | |||||
| біздер | |||||
| олар | |||||
| сіз | |||||
| сіздер | |||||
| маған | |||||
| оған | |||||
| саған | |||||
| біздің | |||||
| сіздің | |||||
| оның | |||||
| бізге | |||||
| сізге | |||||
| оларға | |||||
| біздерге | |||||
| сіздерге | |||||
| оларға | |||||
| менімен | |||||
| сенімен | |||||
| онымен | |||||
| бізбен | |||||
| сізбен | |||||
| олармен | |||||
| біздермен | |||||
| сіздермен | |||||
| менің | |||||
| сенің | |||||
| біздің | |||||
| сіздің | |||||
| оның | |||||
| біздердің | |||||
| сіздердің | |||||
| олардың | |||||
| маған | |||||
| саған | |||||
| оған | |||||
| менен | |||||
| сенен | |||||
| одан | |||||
| бізден | |||||
| сізден | |||||
| олардан | |||||
| біздерден | |||||
| сіздерден | |||||
| олардан | |||||
| айтпақшы | |||||
| сонымен | |||||
| сондықтан | |||||
| бұл | |||||
| осы | |||||
| сол | |||||
| анау | |||||
| мынау | |||||
| сонау | |||||
| осынау | |||||
| ана | |||||
| мына | |||||
| сона | |||||
| әні | |||||
| міне | |||||
| өй | |||||
| үйт | |||||
| бүйт | |||||
| біреу | |||||
| кейбіреу | |||||
| кейбір | |||||
| қайсыбір | |||||
| әрбір | |||||
| бірнеше | |||||
| бірдеме | |||||
| бірнеше | |||||
| әркім | |||||
| әрне | |||||
| әрқайсы | |||||
| әрқалай | |||||
| әлдекім | |||||
| әлдене | |||||
| әлдеқайдан | |||||
| әлденеше | |||||
| әлдеқалай | |||||
| әлдеқашан | |||||
| алдақашан | |||||
| еш | |||||
| ешкім | |||||
| ешбір | |||||
| ештеме | |||||
| дәнеңе | |||||
| ешқашан | |||||
| ешқандай | |||||
| ешқайсы | |||||
| емес | |||||
| бәрі | |||||
| барлық | |||||
| барша | |||||
| бар | |||||
| күллі | |||||
| бүкіл | |||||
| түгел | |||||
| өз | |||||
| өзім | |||||
| өзің | |||||
| өзінің | |||||
| өзіме | |||||
| өзіне | |||||
| өзімнің | |||||
| өзі | |||||
| өзге | |||||
| менде | |||||
| сенде | |||||
| онда | |||||
| менен | |||||
| сенен онан | |||||
| одан | |||||
| ау | |||||
| па | |||||
| ей | |||||
| әй | |||||
| е | |||||
| уа | |||||
| уау | |||||
| уай | |||||
| я | |||||
| пай | |||||
| ә | |||||
| о | |||||
| оһо | |||||
| ой | |||||
| ие | |||||
| аһа | |||||
| ау | |||||
| беу | |||||
| мәссаған | |||||
| бәрекелді | |||||
| әттегенай | |||||
| жаракімалла | |||||
| масқарай | |||||
| астапыралла | |||||
| япырмай | |||||
| ойпырмай | |||||
| кәне | |||||
| кәнеки | |||||
| ал | |||||
| әйда | |||||
| кәні | |||||
| міне | |||||
| әні | |||||
| сорап | |||||
| қош-қош | |||||
| пфша | |||||
| пішә | |||||
| құрау-құрау | |||||
| шәйт | |||||
| шек | |||||
| моһ | |||||
| тәк | |||||
| құрау | |||||
| құр | |||||
| кә | |||||
| кәһ | |||||
| күшім | |||||
| күшім | |||||
| мышы | |||||
| пырс | |||||
| әукім | |||||
| алақай | |||||
| паһ-паһ | |||||
| бәрекелді | |||||
| ура | |||||
| әттең | |||||
| әттеген-ай | |||||
| қап | |||||
| түге | |||||
| пішту | |||||
| шіркін | |||||
| алатау | |||||
| пай-пай | |||||
| үшін | |||||
| сайын | |||||
| сияқты | |||||
| туралы | |||||
| арқылы | |||||
| бойы | |||||
| бойымен | |||||
| шамалы | |||||
| шақты | |||||
| қаралы | |||||
| ғұрлы | |||||
| ғұрлым | |||||
| шейін | |||||
| дейін | |||||
| қарай | |||||
| таман | |||||
| салым | |||||
| тарта | |||||
| жуық | |||||
| таяу | |||||
| гөрі | |||||
| бері | |||||
| кейін | |||||
| соң | |||||
| бұрын | |||||
| бетер | |||||
| қатар | |||||
| бірге | |||||
| қоса | |||||
| арс | |||||
| гүрс | |||||
| дүрс | |||||
| қорс | |||||
| тарс | |||||
| тырс | |||||
| ырс | |||||
| барқ | |||||
| борт | |||||
| күрт | |||||
| кірт | |||||
| морт | |||||
| сарт | |||||
| шырт | |||||
| дүңк | |||||
| күңк | |||||
| қыңқ | |||||
| мыңқ | |||||
| маңқ | |||||
| саңқ | |||||
| шаңқ | |||||
| шіңк | |||||
| сыңқ | |||||
| таңқ | |||||
| тыңқ | |||||
| ыңқ | |||||
| болп | |||||
| былп | |||||
| жалп | |||||
| желп | |||||
| қолп | |||||
| ірк | |||||
| ырқ | |||||
| сарт-сұрт | |||||
| тарс-тұрс | |||||
| арс-ұрс | |||||
| жалт-жалт | |||||
| жалт-жұлт | |||||
| қалт-қалт | |||||
| қалт-құлт | |||||
| қаңқ-қаңқ | |||||
| қаңқ-құңқ | |||||
| шаңқ-шаңқ | |||||
| шаңқ-шұңқ | |||||
| арбаң-арбаң | |||||
| бүгжең-бүгжең | |||||
| арсалаң-арсалаң | |||||
| ербелең-ербелең | |||||
| батыр-бұтыр | |||||
| далаң-далаң | |||||
| тарбаң-тарбаң | |||||
| қызараң-қызараң | |||||
| қаңғыр-күңгір | |||||
| қайқаң-құйқаң | |||||
| митың-митың | |||||
| салаң-сұлаң | |||||
| ыржың-тыржың | |||||
| бірақ | |||||
| алайда | |||||
| дегенмен | |||||
| әйтпесе | |||||
| әйткенмен | |||||
| себебі | |||||
| өйткені | |||||
| сондықтан | |||||
| үшін | |||||
| сайын | |||||
| сияқты | |||||
| туралы | |||||
| арқылы | |||||
| бойы | |||||
| бойымен | |||||
| шамалы | |||||
| шақты | |||||
| қаралы | |||||
| ғұрлы | |||||
| ғұрлым | |||||
| гөрі | |||||
| бері | |||||
| кейін | |||||
| соң | |||||
| бұрын | |||||
| бетер | |||||
| қатар | |||||
| бірге | |||||
| қоса | |||||
| шейін | |||||
| дейін | |||||
| қарай | |||||
| таман | |||||
| салым | |||||
| тарта | |||||
| жуық | |||||
| таяу | |||||
| арнайы | |||||
| осындай | |||||
| ғана | |||||
| қана | |||||
| тек | |||||
| әншейін | |||||
+ 255
- 0
Models+K-Means/nltk_data/corpora/stopwords/nepali
View File
| @@ -0,0 +1,255 @@ | |||||
| छ | |||||
| र | |||||
| पनि | |||||
| छन् | |||||
| लागि | |||||
| भएको | |||||
| गरेको | |||||
| भने | |||||
| गर्न | |||||
| गर्ने | |||||
| हो | |||||
| तथा | |||||
| यो | |||||
| रहेको | |||||
| उनले | |||||
| थियो | |||||
| हुने | |||||
| गरेका | |||||
| थिए | |||||
| गर्दै | |||||
| तर | |||||
| नै | |||||
| को | |||||
| मा | |||||
| हुन् | |||||
| भन्ने | |||||
| हुन | |||||
| गरी | |||||
| त | |||||
| हुन्छ | |||||
| अब | |||||
| के | |||||
| रहेका | |||||
| गरेर | |||||
| छैन | |||||
| दिए | |||||
| भए | |||||
| यस | |||||
| ले | |||||
| गर्नु | |||||
| औं | |||||
| सो | |||||
| त्यो | |||||
| कि | |||||
| जुन | |||||
| यी | |||||
| का | |||||
| गरि | |||||
| ती | |||||
| न | |||||
| छु | |||||
| छौं | |||||
| लाई | |||||
| नि | |||||
| उप | |||||
| अक्सर | |||||
| आदि | |||||
| कसरी | |||||
| क्रमशः | |||||
| चाले | |||||
| अगाडी | |||||
| अझै | |||||
| अनुसार | |||||
| अन्तर्गत | |||||
| अन्य | |||||
| अन्यत्र | |||||
| अन्यथा | |||||
| अरु | |||||
| अरुलाई | |||||
| अर्को | |||||
| अर्थात | |||||
| अर्थात् | |||||
| अलग | |||||
| आए | |||||
| आजको | |||||
| ओठ | |||||
| आत्म | |||||
| आफू | |||||
| आफूलाई | |||||
| आफ्नै | |||||
| आफ्नो | |||||
| आयो | |||||
| उदाहरण | |||||
| उनको | |||||
| उहालाई | |||||
| एउटै | |||||
| एक | |||||
| एकदम | |||||
| कतै | |||||
| कम से कम | |||||
| कसै | |||||
| कसैले | |||||
| कहाँबाट | |||||
| कहिलेकाहीं | |||||
| का | |||||
| किन | |||||
| किनभने | |||||
| कुनै | |||||
| कुरा | |||||
| कृपया | |||||
| केही | |||||
| कोही | |||||
| गए | |||||
| गरौं | |||||
| गर्छ | |||||
| गर्छु | |||||
| गर्नुपर्छ | |||||
| गयौ | |||||
| गैर | |||||
| चार | |||||
| चाहनुहुन्छ | |||||
| चाहन्छु | |||||
| चाहिए | |||||
| छू | |||||
| जताततै | |||||
| जब | |||||
| जबकि | |||||
| जसको | |||||
| जसबाट | |||||
| जसमा | |||||
| जसलाई | |||||
| जसले | |||||
| जस्तै | |||||
| जस्तो | |||||
| जस्तोसुकै | |||||
| जहाँ | |||||
| जान | |||||
| जाहिर | |||||
| जे | |||||
| जो | |||||
| ठीक | |||||
| तत्काल | |||||
| तदनुसार | |||||
| तपाईको | |||||
| तपाई | |||||
| पर्याप्त | |||||
| पहिले | |||||
| पहिलो | |||||
| पहिल्यै | |||||
| पाँच | |||||
| पाँचौं | |||||
| तल | |||||
| तापनी | |||||
| तिनी | |||||
| तिनीहरू | |||||
| तिनीहरुको | |||||
| तिनिहरुलाई | |||||
| तिमी | |||||
| तिर | |||||
| तीन | |||||
| तुरुन्तै | |||||
| तेस्रो | |||||
| तेस्कारण | |||||
| पूर्व | |||||
| प्रति | |||||
| प्रतेक | |||||
| प्लस | |||||
| फेरी | |||||
| बने | |||||
| त्सपछि | |||||
| त्सैले | |||||
| त्यहाँ | |||||
| थिएन | |||||
| दिनुभएको | |||||
| दिनुहुन्छ | |||||
| दुई | |||||
| देखि | |||||
| बरु | |||||
| बारे | |||||
| बाहिर | |||||
| देखिन्छ | |||||
| देखियो | |||||
| देखे | |||||
| देखेको | |||||
| देखेर | |||||
| दोस्रो | |||||
| धेरै | |||||
| नजिकै | |||||
| नत्र | |||||
| नयाँ | |||||
| निम्ति | |||||
| बाहेक | |||||
| बीच | |||||
| बीचमा | |||||
| भन | |||||
| निम्न | |||||
| निम्नानुसार | |||||
| निर्दिष्ट | |||||
| नौ | |||||
| पक्का | |||||
| पक्कै | |||||
| पछि | |||||
| पछिल्लो | |||||
| पटक | |||||
| पर्छ | |||||
| पर्थ्यो | |||||
| भन्छन् | |||||
| भन् | |||||
| भन्छु | |||||
| भन्दा | |||||
| भन्नुभयो | |||||
| भर | |||||
| भित्र | |||||
| भित्री | |||||
| म | |||||
| मलाई | |||||
| मात्र | |||||
| माथि | |||||
| मुख्य | |||||
| मेरो | |||||
| यति | |||||
| यथोचित | |||||
| यदि | |||||
| यद्यपि | |||||
| यसको | |||||
| यसपछि | |||||
| यसबाहेक | |||||
| यसरी | |||||
| यसो | |||||
| यस्तो | |||||
| यहाँ | |||||
| यहाँसम्म | |||||
| या | |||||
| रही | |||||
| राखे | |||||
| राख्छ | |||||
| राम्रो | |||||
| रूप | |||||
| लगभग | |||||
| वरीपरी | |||||
| वास्तवमा | |||||
| बिरुद्ध | |||||
| बिशेष | |||||
| सायद | |||||
| शायद | |||||
| संग | |||||
| संगै | |||||
| सक्छ | |||||
| सट्टा | |||||
| सधै | |||||
| सबै | |||||
| सबैलाई | |||||
| समय | |||||
| सम्भव | |||||
| सम्म | |||||
| सही | |||||
| साँच्चै | |||||
| सात | |||||
| साथ | |||||
| साथै | |||||
| सारा | |||||
| सोही | |||||
| स्पष्ट | |||||
| हरे | |||||
| हरेक | |||||
+ 176
- 0
Models+K-Means/nltk_data/corpora/stopwords/norwegian
View File
| @@ -0,0 +1,176 @@ | |||||
| og | |||||
| i | |||||
| jeg | |||||
| det | |||||
| at | |||||
| en | |||||
| et | |||||
| den | |||||
| til | |||||
| er | |||||
| som | |||||
| på | |||||
| de | |||||
| med | |||||
| han | |||||
| av | |||||
| ikke | |||||
| ikkje | |||||
| der | |||||
| så | |||||
| var | |||||
| meg | |||||
| seg | |||||
| men | |||||
| ett | |||||
| har | |||||
| om | |||||
| vi | |||||
| min | |||||
| mitt | |||||
| ha | |||||
| hadde | |||||
| hun | |||||
| nå | |||||
| over | |||||
| da | |||||
| ved | |||||
| fra | |||||
| du | |||||
| ut | |||||
| sin | |||||
| dem | |||||
| oss | |||||
| opp | |||||
| man | |||||
| kan | |||||
| hans | |||||
| hvor | |||||
| eller | |||||
| hva | |||||
| skal | |||||
| selv | |||||
| sjøl | |||||
| her | |||||
| alle | |||||
| vil | |||||
| bli | |||||
| ble | |||||
| blei | |||||
| blitt | |||||
| kunne | |||||
| inn | |||||
| når | |||||
| være | |||||
| kom | |||||
| noen | |||||
| noe | |||||
| ville | |||||
| dere | |||||
| som | |||||
| deres | |||||
| kun | |||||
| ja | |||||
| etter | |||||
| ned | |||||
| skulle | |||||
| denne | |||||
| for | |||||
| deg | |||||
| si | |||||
| sine | |||||
| sitt | |||||
| mot | |||||
| å | |||||
| meget | |||||
| hvorfor | |||||
| dette | |||||
| disse | |||||
| uten | |||||
| hvordan | |||||
| ingen | |||||
| din | |||||
| ditt | |||||
| blir | |||||
| samme | |||||
| hvilken | |||||
| hvilke | |||||
| sånn | |||||
| inni | |||||
| mellom | |||||
| vår | |||||
| hver | |||||
| hvem | |||||
| vors | |||||
| hvis | |||||
| både | |||||
| bare | |||||
| enn | |||||
| fordi | |||||
| før | |||||
| mange | |||||
| også | |||||
| slik | |||||
| vært | |||||
| være | |||||
| båe | |||||
| begge | |||||
| siden | |||||
| dykk | |||||
| dykkar | |||||
| dei | |||||
| deira | |||||
| deires | |||||
| deim | |||||
| di | |||||
| då | |||||
| eg | |||||
| ein | |||||
| eit | |||||
| eitt | |||||
| elles | |||||
| honom | |||||
| hjå | |||||
| ho | |||||
| hoe | |||||
| henne | |||||
| hennar | |||||
| hennes | |||||
| hoss | |||||
| hossen | |||||
| ikkje | |||||
| ingi | |||||
| inkje | |||||
| korleis | |||||
| korso | |||||
| kva | |||||
| kvar | |||||
| kvarhelst | |||||
| kven | |||||
| kvi | |||||
| kvifor | |||||
| me | |||||
| medan | |||||
| mi | |||||
| mine | |||||
| mykje | |||||
| no | |||||
| nokon | |||||
| noka | |||||
| nokor | |||||
| noko | |||||
| nokre | |||||
| si | |||||
| sia | |||||
| sidan | |||||
| so | |||||
| somt | |||||
| somme | |||||
| um | |||||
| upp | |||||
| vere | |||||
| vore | |||||
| verte | |||||
| vort | |||||
| varte | |||||
| vart | |||||
+ 207
- 0
Models+K-Means/nltk_data/corpora/stopwords/portuguese
View File
| @@ -0,0 +1,207 @@ | |||||
| a | |||||
| à | |||||
| ao | |||||
| aos | |||||
| aquela | |||||
| aquelas | |||||
| aquele | |||||
| aqueles | |||||
| aquilo | |||||
| as | |||||
| às | |||||
| até | |||||
| com | |||||
| como | |||||
| da | |||||
| das | |||||
| de | |||||
| dela | |||||
| delas | |||||
| dele | |||||
| deles | |||||
| depois | |||||
| do | |||||
| dos | |||||
| e | |||||
| é | |||||
| ela | |||||
| elas | |||||
| ele | |||||
| eles | |||||
| em | |||||
| entre | |||||
| era | |||||
| eram | |||||
| éramos | |||||
| essa | |||||
| essas | |||||
| esse | |||||
| esses | |||||
| esta | |||||
| está | |||||
| estamos | |||||
| estão | |||||
| estar | |||||
| estas | |||||
| estava | |||||
| estavam | |||||
| estávamos | |||||
| este | |||||
| esteja | |||||
| estejam | |||||
| estejamos | |||||
| estes | |||||
| esteve | |||||
| estive | |||||
| estivemos | |||||
| estiver | |||||
| estivera | |||||
| estiveram | |||||
| estivéramos | |||||
| estiverem | |||||
| estivermos | |||||
| estivesse | |||||
| estivessem | |||||
| estivéssemos | |||||
| estou | |||||
| eu | |||||
| foi | |||||
| fomos | |||||
| for | |||||
| fora | |||||
| foram | |||||
| fôramos | |||||
| forem | |||||
| formos | |||||
| fosse | |||||
| fossem | |||||
| fôssemos | |||||
| fui | |||||
| há | |||||
| haja | |||||
| hajam | |||||
| hajamos | |||||
| hão | |||||
| havemos | |||||
| haver | |||||
| hei | |||||
| houve | |||||
| houvemos | |||||
| houver | |||||
| houvera | |||||
| houverá | |||||
| houveram | |||||
| houvéramos | |||||
| houverão | |||||
| houverei | |||||
| houverem | |||||
| houveremos | |||||
| houveria | |||||
| houveriam | |||||
| houveríamos | |||||
| houvermos | |||||
| houvesse | |||||
| houvessem | |||||
| houvéssemos | |||||
| isso | |||||
| isto | |||||
| já | |||||
| lhe | |||||
| lhes | |||||
| mais | |||||
| mas | |||||
| me | |||||
| mesmo | |||||
| meu | |||||
| meus | |||||
| minha | |||||
| minhas | |||||
| muito | |||||
| na | |||||
| não | |||||
| nas | |||||
| nem | |||||
| no | |||||
| nos | |||||
| nós | |||||
| nossa | |||||
| nossas | |||||
| nosso | |||||
| nossos | |||||
| num | |||||
| numa | |||||
| o | |||||
| os | |||||
| ou | |||||
| para | |||||
| pela | |||||
| pelas | |||||
| pelo | |||||
| pelos | |||||
| por | |||||
| qual | |||||
| quando | |||||
| que | |||||
| quem | |||||
| são | |||||
| se | |||||
| seja | |||||
| sejam | |||||
| sejamos | |||||
| sem | |||||
| ser | |||||
| será | |||||
| serão | |||||
| serei | |||||
| seremos | |||||
| seria | |||||
| seriam | |||||
| seríamos | |||||
| seu | |||||
| seus | |||||
| só | |||||
| somos | |||||
| sou | |||||
| sua | |||||
| suas | |||||
| também | |||||
| te | |||||
| tem | |||||
| tém | |||||
| temos | |||||
| tenha | |||||
| tenham | |||||
| tenhamos | |||||
| tenho | |||||
| terá | |||||
| terão | |||||
| terei | |||||
| teremos | |||||
| teria | |||||
| teriam | |||||
| teríamos | |||||
| teu | |||||
| teus | |||||
| teve | |||||
| tinha | |||||
| tinham | |||||
| tínhamos | |||||
| tive | |||||
| tivemos | |||||
| tiver | |||||
| tivera | |||||
| tiveram | |||||
| tivéramos | |||||
| tiverem | |||||
| tivermos | |||||
| tivesse | |||||
| tivessem | |||||
| tivéssemos | |||||
| tu | |||||
| tua | |||||
| tuas | |||||
| um | |||||
| uma | |||||
| você | |||||
| vocês | |||||
| vos | |||||
+ 356
- 0
Models+K-Means/nltk_data/corpora/stopwords/romanian
View File
| @@ -0,0 +1,356 @@ | |||||
| a | |||||
| abia | |||||
| acea | |||||
| aceasta | |||||
| această | |||||
| aceea | |||||
| aceeasi | |||||
| acei | |||||
| aceia | |||||
| acel | |||||
| acela | |||||
| acelasi | |||||
| acele | |||||
| acelea | |||||
| acest | |||||
| acesta | |||||
| aceste | |||||
| acestea | |||||
| acestei | |||||
| acestia | |||||
| acestui | |||||
| aceşti | |||||
| aceştia | |||||
| adica | |||||
| ai | |||||
| aia | |||||
| aibă | |||||
| aici | |||||
| al | |||||
| ala | |||||
| ale | |||||
| alea | |||||
| alt | |||||
| alta | |||||
| altceva | |||||
| altcineva | |||||
| alte | |||||
| altfel | |||||
| alti | |||||
| altii | |||||
| altul | |||||
| am | |||||
| anume | |||||
| apoi | |||||
| ar | |||||
| are | |||||
| as | |||||
| asa | |||||
| asta | |||||
| astea | |||||
| astfel | |||||
| asupra | |||||
| atare | |||||
| atat | |||||
| atata | |||||
| atatea | |||||
| atatia | |||||
| ati | |||||
| atit | |||||
| atita | |||||
| atitea | |||||
| atitia | |||||
| atunci | |||||
| au | |||||
| avea | |||||
| avem | |||||
| aveţi | |||||
| avut | |||||
| aş | |||||
| aţi | |||||
| ba | |||||
| ca | |||||
| cam | |||||
| cand | |||||
| care | |||||
| careia | |||||
| carora | |||||
| caruia | |||||
| cat | |||||
| catre | |||||
| ce | |||||
| cea | |||||
| ceea | |||||
| cei | |||||
| ceilalti | |||||
| cel | |||||
| cele | |||||
| celor | |||||
| ceva | |||||
| chiar | |||||
| ci | |||||
| cind | |||||
| cine | |||||
| cineva | |||||
| cit | |||||
| cita | |||||
| cite | |||||
| citeva | |||||
| citi | |||||
| citiva | |||||
| cu | |||||
| cui | |||||
| cum | |||||
| cumva | |||||
| cât | |||||
| câte | |||||
| câtva | |||||
| câţi | |||||
| cînd | |||||
| cît | |||||
| cîte | |||||
| cîtva | |||||
| cîţi | |||||
| că | |||||
| căci | |||||
| cărei | |||||
| căror | |||||
| cărui | |||||
| către | |||||
| da | |||||
| daca | |||||
| dacă | |||||
| dar | |||||
| dat | |||||
| dată | |||||
| dau | |||||
| de | |||||
| deasupra | |||||
| deci | |||||
| decit | |||||
| deja | |||||
| desi | |||||
| despre | |||||
| deşi | |||||
| din | |||||
| dintr | |||||
| dintr- | |||||
| dintre | |||||
| doar | |||||
| doi | |||||
| doilea | |||||
| două | |||||
| drept | |||||
| dupa | |||||
| după | |||||
| dă | |||||
| e | |||||
| ea | |||||
| ei | |||||
| el | |||||
| ele | |||||
| era | |||||
| eram | |||||
| este | |||||
| eu | |||||
| eşti | |||||
| face | |||||
| fara | |||||
| fata | |||||
| fel | |||||
| fi | |||||
| fie | |||||
| fiecare | |||||
| fii | |||||
| fim | |||||
| fiu | |||||
| fiţi | |||||
| foarte | |||||
| fost | |||||
| fără | |||||
| i | |||||
| ia | |||||
| iar | |||||
| ii | |||||
| il | |||||
| imi | |||||
| in | |||||
| inainte | |||||
| inapoi | |||||
| inca | |||||
| incit | |||||
| insa | |||||
| intr | |||||
| intre | |||||
| isi | |||||
| iti | |||||
| la | |||||
| le | |||||
| li | |||||
| lor | |||||
| lui | |||||
| lângă | |||||
| lîngă | |||||
| m | |||||
| ma | |||||
| mai | |||||
| mea | |||||
| mei | |||||
| mele | |||||
| mereu | |||||
| meu | |||||
| mi | |||||
| mie | |||||
| mine | |||||
| mod | |||||
| mult | |||||
| multa | |||||
| multe | |||||
| multi | |||||
| multă | |||||
| mulţi | |||||
| mâine | |||||
| mîine | |||||
| mă | |||||
| ne | |||||
| ni | |||||
| nici | |||||
| nimeni | |||||
| nimic | |||||
| niste | |||||
| nişte | |||||
| noastre | |||||
| noastră | |||||
| noi | |||||
| nostri | |||||
| nostru | |||||
| nou | |||||
| noua | |||||
| nouă | |||||
| noştri | |||||
| nu | |||||
| numai | |||||
| o | |||||
| or | |||||
| ori | |||||
| oricare | |||||
| orice | |||||
| oricine | |||||
| oricum | |||||
| oricând | |||||
| oricât | |||||
| oricînd | |||||
| oricît | |||||
| oriunde | |||||
| pai | |||||
| parca | |||||
| patra | |||||
| patru | |||||
| pe | |||||
| pentru | |||||
| peste | |||||
| pic | |||||
| pina | |||||
| poate | |||||
| pot | |||||
| prea | |||||
| prima | |||||
| primul | |||||
| prin | |||||
| printr- | |||||
| putini | |||||
| puţin | |||||
| puţina | |||||
| puţină | |||||
| până | |||||
| pînă | |||||
| sa | |||||
| sa-mi | |||||
| sa-ti | |||||
| sai | |||||
| sale | |||||
| sau | |||||
| se | |||||
| si | |||||
| sint | |||||
| sintem | |||||
| spate | |||||
| spre | |||||
| sub | |||||
| sunt | |||||
| suntem | |||||
| sunteţi | |||||
| sus | |||||
| să | |||||
| săi | |||||
| său | |||||
| t | |||||
| ta | |||||
| tale | |||||
| te | |||||
| ti | |||||
| tine | |||||
| toata | |||||
| toate | |||||
| toată | |||||
| tocmai | |||||
| tot | |||||
| toti | |||||
| totul | |||||
| totusi | |||||
| totuşi | |||||
| toţi | |||||
| trei | |||||
| treia | |||||
| treilea | |||||
| tu | |||||
| tuturor | |||||
| tăi | |||||
| tău | |||||
| u | |||||
| ul | |||||
| ului | |||||
| un | |||||
| una | |||||
| unde | |||||
| undeva | |||||
| unei | |||||
| uneia | |||||
| unele | |||||
| uneori | |||||
| unii | |||||
| unor | |||||
| unora | |||||
| unu | |||||
| unui | |||||
| unuia | |||||
| unul | |||||
| v | |||||
| va | |||||
| vi | |||||
| voastre | |||||
| voastră | |||||
| voi | |||||
| vom | |||||
| vor | |||||
| vostru | |||||
| vouă | |||||
| voştri | |||||
| vreo | |||||
| vreun | |||||
| vă | |||||
| zi | |||||
| zice | |||||
| îi | |||||
| îl | |||||
| îmi | |||||
| în | |||||
| îţi | |||||
| ăla | |||||
| ălea | |||||
| ăsta | |||||
| ăstea | |||||
| ăştia | |||||
| şi | |||||
| ţi | |||||
| ţie | |||||
+ 151
- 0
Models+K-Means/nltk_data/corpora/stopwords/russian
View File
| @@ -0,0 +1,151 @@ | |||||
| и | |||||
| в | |||||
| во | |||||
| не | |||||
| что | |||||
| он | |||||
| на | |||||
| я | |||||
| с | |||||
| со | |||||
| как | |||||
| а | |||||
| то | |||||
| все | |||||
| она | |||||
| так | |||||
| его | |||||
| но | |||||
| да | |||||
| ты | |||||
| к | |||||
| у | |||||
| же | |||||
| вы | |||||
| за | |||||
| бы | |||||
| по | |||||
| только | |||||
| ее | |||||
| мне | |||||
| было | |||||
| вот | |||||
| от | |||||
| меня | |||||
| еще | |||||
| нет | |||||
| о | |||||
| из | |||||
| ему | |||||
| теперь | |||||
| когда | |||||
| даже | |||||
| ну | |||||
| вдруг | |||||
| ли | |||||
| если | |||||
| уже | |||||
| или | |||||
| ни | |||||
| быть | |||||
| был | |||||
| него | |||||
| до | |||||
| вас | |||||
| нибудь | |||||
| опять | |||||
| уж | |||||
| вам | |||||
| ведь | |||||
| там | |||||
| потом | |||||
| себя | |||||
| ничего | |||||
| ей | |||||
| может | |||||
| они | |||||
| тут | |||||
| где | |||||
| есть | |||||
| надо | |||||
| ней | |||||
| для | |||||
| мы | |||||
| тебя | |||||
| их | |||||
| чем | |||||
| была | |||||
| сам | |||||
| чтоб | |||||
| без | |||||
| будто | |||||
| чего | |||||
| раз | |||||
| тоже | |||||
| себе | |||||
| под | |||||
| будет | |||||
| ж | |||||
| тогда | |||||
| кто | |||||
| этот | |||||
| того | |||||
| потому | |||||
| этого | |||||
| какой | |||||
| совсем | |||||
| ним | |||||
| здесь | |||||
| этом | |||||
| один | |||||
| почти | |||||
| мой | |||||
| тем | |||||
| чтобы | |||||
| нее | |||||
| сейчас | |||||
| были | |||||
| куда | |||||
| зачем | |||||
| всех | |||||
| никогда | |||||
| можно | |||||
| при | |||||
| наконец | |||||
| два | |||||
| об | |||||
| другой | |||||
| хоть | |||||
| после | |||||
| над | |||||
| больше | |||||
| тот | |||||
| через | |||||
| эти | |||||
| нас | |||||
| про | |||||
| всего | |||||
| них | |||||
| какая | |||||
| много | |||||
| разве | |||||
| три | |||||
| эту | |||||
| моя | |||||
| впрочем | |||||
| хорошо | |||||
| свою | |||||
| этой | |||||
| перед | |||||
| иногда | |||||
| лучше | |||||
| чуть | |||||
| том | |||||
| нельзя | |||||
| такой | |||||
| им | |||||
| более | |||||
| всегда | |||||
| конечно | |||||
| всю | |||||
| между | |||||
+ 1784
- 0
Models+K-Means/nltk_data/corpora/stopwords/slovene
File diff suppressed because it is too large
View File
+ 313
- 0
Models+K-Means/nltk_data/corpora/stopwords/spanish
View File
| @@ -0,0 +1,313 @@ | |||||
| de | |||||
| la | |||||
| que | |||||
| el | |||||
| en | |||||
| y | |||||
| a | |||||
| los | |||||
| del | |||||
| se | |||||
| las | |||||
| por | |||||
| un | |||||
| para | |||||
| con | |||||
| no | |||||
| una | |||||
| su | |||||
| al | |||||
| lo | |||||
| como | |||||
| más | |||||
| pero | |||||
| sus | |||||
| le | |||||
| ya | |||||
| o | |||||
| este | |||||
| sí | |||||
| porque | |||||
| esta | |||||
| entre | |||||
| cuando | |||||
| muy | |||||
| sin | |||||
| sobre | |||||
| también | |||||
| me | |||||
| hasta | |||||
| hay | |||||
| donde | |||||
| quien | |||||
| desde | |||||
| todo | |||||
| nos | |||||
| durante | |||||
| todos | |||||
| uno | |||||
| les | |||||
| ni | |||||
| contra | |||||
| otros | |||||
| ese | |||||
| eso | |||||
| ante | |||||
| ellos | |||||
| e | |||||
| esto | |||||
| mí | |||||
| antes | |||||
| algunos | |||||
| qué | |||||
| unos | |||||
| yo | |||||
| otro | |||||
| otras | |||||
| otra | |||||
| él | |||||
| tanto | |||||
| esa | |||||
| estos | |||||
| mucho | |||||
| quienes | |||||
| nada | |||||
| muchos | |||||
| cual | |||||
| poco | |||||
| ella | |||||
| estar | |||||
| estas | |||||
| algunas | |||||
| algo | |||||
| nosotros | |||||
| mi | |||||
| mis | |||||
| tú | |||||
| te | |||||
| ti | |||||
| tu | |||||
| tus | |||||
| ellas | |||||
| nosotras | |||||
| vosotros | |||||
| vosotras | |||||
| os | |||||
| mío | |||||
| mía | |||||
| míos | |||||
| mías | |||||
| tuyo | |||||
| tuya | |||||
| tuyos | |||||
| tuyas | |||||
| suyo | |||||
| suya | |||||
| suyos | |||||
| suyas | |||||
| nuestro | |||||
| nuestra | |||||
| nuestros | |||||
| nuestras | |||||
| vuestro | |||||
| vuestra | |||||
| vuestros | |||||
| vuestras | |||||
| esos | |||||
| esas | |||||
| estoy | |||||
| estás | |||||
| está | |||||
| estamos | |||||
| estáis | |||||
| están | |||||
| esté | |||||
| estés | |||||
| estemos | |||||
| estéis | |||||
| estén | |||||
| estaré | |||||
| estarás | |||||
| estará | |||||
| estaremos | |||||
| estaréis | |||||
| estarán | |||||
| estaría | |||||
| estarías | |||||
| estaríamos | |||||
| estaríais | |||||
| estarían | |||||
| estaba | |||||
| estabas | |||||
| estábamos | |||||
| estabais | |||||
| estaban | |||||
| estuve | |||||
| estuviste | |||||
| estuvo | |||||
| estuvimos | |||||
| estuvisteis | |||||
| estuvieron | |||||
| estuviera | |||||
| estuvieras | |||||
| estuviéramos | |||||
| estuvierais | |||||
| estuvieran | |||||
| estuviese | |||||
| estuvieses | |||||
| estuviésemos | |||||
| estuvieseis | |||||
| estuviesen | |||||
| estando | |||||
| estado | |||||
| estada | |||||
| estados | |||||
| estadas | |||||
| estad | |||||
| he | |||||
| has | |||||
| ha | |||||
| hemos | |||||
| habéis | |||||
| han | |||||
| haya | |||||
| hayas | |||||
| hayamos | |||||
| hayáis | |||||
| hayan | |||||
| habré | |||||
| habrás | |||||
| habrá | |||||
| habremos | |||||
| habréis | |||||
| habrán | |||||
| habría | |||||
| habrías | |||||
| habríamos | |||||
| habríais | |||||
| habrían | |||||
| había | |||||
| habías | |||||
| habíamos | |||||
| habíais | |||||
| habían | |||||
| hube | |||||
| hubiste | |||||
| hubo | |||||
| hubimos | |||||
| hubisteis | |||||
| hubieron | |||||
| hubiera | |||||
| hubieras | |||||
| hubiéramos | |||||
| hubierais | |||||
| hubieran | |||||
| hubiese | |||||
| hubieses | |||||
| hubiésemos | |||||
| hubieseis | |||||
| hubiesen | |||||
| habiendo | |||||
| habido | |||||
| habida | |||||
| habidos | |||||
| habidas | |||||
| soy | |||||
| eres | |||||
| es | |||||
| somos | |||||
| sois | |||||
| son | |||||
| sea | |||||
| seas | |||||
| seamos | |||||
| seáis | |||||
| sean | |||||
| seré | |||||
| serás | |||||
| será | |||||
| seremos | |||||
| seréis | |||||
| serán | |||||
| sería | |||||
| serías | |||||
| seríamos | |||||
| seríais | |||||
| serían | |||||
| era | |||||
| eras | |||||
| éramos | |||||
| erais | |||||
| eran | |||||
| fui | |||||
| fuiste | |||||
| fue | |||||
| fuimos | |||||
| fuisteis | |||||
| fueron | |||||
| fuera | |||||
| fueras | |||||
| fuéramos | |||||
| fuerais | |||||
| fueran | |||||
| fuese | |||||
| fueses | |||||
| fuésemos | |||||
| fueseis | |||||
| fuesen | |||||
| sintiendo | |||||
| sentido | |||||
| sentida | |||||
| sentidos | |||||
| sentidas | |||||
| siente | |||||
| sentid | |||||
| tengo | |||||
| tienes | |||||
| tiene | |||||
| tenemos | |||||
| tenéis | |||||
| tienen | |||||
| tenga | |||||
| tengas | |||||
| tengamos | |||||
| tengáis | |||||
| tengan | |||||
| tendré | |||||
| tendrás | |||||
| tendrá | |||||
| tendremos | |||||
| tendréis | |||||
| tendrán | |||||
| tendría | |||||
| tendrías | |||||
| tendríamos | |||||
| tendríais | |||||
| tendrían | |||||
| tenía | |||||
| tenías | |||||
| teníamos | |||||
| teníais | |||||
| tenían | |||||
| tuve | |||||
| tuviste | |||||
| tuvo | |||||
| tuvimos | |||||
| tuvisteis | |||||
| tuvieron | |||||
| tuviera | |||||
| tuvieras | |||||
| tuviéramos | |||||
| tuvierais | |||||
| tuvieran | |||||
| tuviese | |||||
| tuvieses | |||||
| tuviésemos | |||||
| tuvieseis | |||||
| tuviesen | |||||
| teniendo | |||||
| tenido | |||||
| tenida | |||||
| tenidos | |||||
| tenidas | |||||
| tened | |||||
+ 114
- 0
Models+K-Means/nltk_data/corpora/stopwords/swedish
View File
| @@ -0,0 +1,114 @@ | |||||
| och | |||||
| det | |||||
| att | |||||
| i | |||||
| en | |||||
| jag | |||||
| hon | |||||
| som | |||||
| han | |||||
| på | |||||
| den | |||||
| med | |||||
| var | |||||
| sig | |||||
| för | |||||
| så | |||||
| till | |||||
| är | |||||
| men | |||||
| ett | |||||
| om | |||||
| hade | |||||
| de | |||||
| av | |||||
| icke | |||||
| mig | |||||
| du | |||||
| henne | |||||
| då | |||||
| sin | |||||
| nu | |||||
| har | |||||
| inte | |||||
| hans | |||||
| honom | |||||
| skulle | |||||
| hennes | |||||
| där | |||||
| min | |||||
| man | |||||
| ej | |||||
| vid | |||||
| kunde | |||||
| något | |||||
| från | |||||
| ut | |||||
| när | |||||
| efter | |||||
| upp | |||||
| vi | |||||
| dem | |||||
| vara | |||||
| vad | |||||
| över | |||||
| än | |||||
| dig | |||||
| kan | |||||
| sina | |||||
| här | |||||
| ha | |||||
| mot | |||||
| alla | |||||
| under | |||||
| någon | |||||
| eller | |||||
| allt | |||||
| mycket | |||||
| sedan | |||||
| ju | |||||
| denna | |||||
| själv | |||||
| detta | |||||
| åt | |||||
| utan | |||||
| varit | |||||
| hur | |||||
| ingen | |||||
| mitt | |||||
| ni | |||||
| bli | |||||
| blev | |||||
| oss | |||||
| din | |||||
| dessa | |||||
| några | |||||
| deras | |||||
| blir | |||||
| mina | |||||
| samma | |||||
| vilken | |||||
| er | |||||
| sådan | |||||
| vår | |||||
| blivit | |||||
| dess | |||||
| inom | |||||
| mellan | |||||
| sådant | |||||
| varför | |||||
| varje | |||||
| vilka | |||||
| ditt | |||||
| vem | |||||
| vilket | |||||
| sitta | |||||
| sådana | |||||
| vart | |||||
| dina | |||||
| vars | |||||
| vårt | |||||
| våra | |||||
| ert | |||||
| era | |||||
| vilkas | |||||
+ 163
- 0
Models+K-Means/nltk_data/corpora/stopwords/tajik
View File
| @@ -0,0 +1,163 @@ | |||||
| аз | |||||
| дар | |||||
| ба | |||||
| бо | |||||
| барои | |||||
| бе | |||||
| то | |||||
| ҷуз | |||||
| пеши | |||||
| назди | |||||
| рӯйи | |||||
| болои | |||||
| паси | |||||
| ғайри | |||||
| ҳамон | |||||
| ҳамоно | |||||
| инҷониб | |||||
| замон | |||||
| замоно | |||||
| эътиборан | |||||
| пеш | |||||
| қабл | |||||
| дида | |||||
| сар карда | |||||
| агар | |||||
| агар ки | |||||
| валекин | |||||
| ки | |||||
| лекин | |||||
| аммо | |||||
| вале | |||||
| балки | |||||
| ва | |||||
| ҳарчанд | |||||
| чунки | |||||
| зеро | |||||
| зеро ки | |||||
| вақте ки | |||||
| то вақте ки | |||||
| барои он ки | |||||
| бо нияти он ки | |||||
| лекин ва ҳол он ки | |||||
| ё | |||||
| ё ин ки | |||||
| бе он ки | |||||
| дар ҳолате ки | |||||
| то даме ки | |||||
| баъд аз он ки | |||||
| даме ки | |||||
| ба тразе ки | |||||
| аз баҳри он ки | |||||
| гар | |||||
| ар | |||||
| ба шарте | |||||
| азбаски | |||||
| модоме ки | |||||
| агар чи | |||||
| гарчанде ки | |||||
| бо вуҷуди он ки | |||||
| гӯё | |||||
| аз-баски | |||||
| чун-ки | |||||
| агар-чанд | |||||
| агар-чи | |||||
| гар-чи | |||||
| то ки | |||||
| чунон ки | |||||
| то даме ки | |||||
| ҳар қадар ки | |||||
| магар | |||||
| оё | |||||
| наход | |||||
| ҳатто | |||||
| ҳам | |||||
| бале | |||||
| оре | |||||
| хуб | |||||
| хуш | |||||
| хайр | |||||
| не | |||||
| на | |||||
| мана | |||||
| э | |||||
| фақат | |||||
| танҳо | |||||
| кошки | |||||
| мабодо | |||||
| ҳтимол | |||||
| ана ҳамин | |||||
| наход ки | |||||
| ҳатто ки | |||||
| аз афташ | |||||
| майлаш куя | |||||
| ана | |||||
| ҳа | |||||
| канӣ | |||||
| гӯё ки | |||||
| ҳо ана | |||||
| на ин ки | |||||
| ваҳ | |||||
| ҳой | |||||
| и | |||||
| а | |||||
| о | |||||
| эҳ | |||||
| ҳе | |||||
| ҳу | |||||
| аҳа | |||||
| оҳе | |||||
| уҳа | |||||
| ҳм | |||||
| нм | |||||
| оббо | |||||
| ӯббо | |||||
| ҳой-ҳой | |||||
| вой-вой | |||||
| ту-ту | |||||
| ҳмм | |||||
| эҳа | |||||
| тавба | |||||
| ӯҳӯ | |||||
| аҷабо | |||||
| ало | |||||
| аё | |||||
| ой | |||||
| ӯим | |||||
| ором | |||||
| хом?ш | |||||
| ҳай-ҳай | |||||
| бай-бай | |||||
| аз | |||||
| он | |||||
| баъд | |||||
| азбаски | |||||
| ӯ | |||||
| ҳангоми | |||||
| чӣ | |||||
| кадом | |||||
| ин | |||||
| ҷо | |||||
| ҳам | |||||
| ё ки | |||||
| бояд | |||||
| аст | |||||
| чанд | |||||
| ҳар | |||||
| бар | |||||
| чаро ки | |||||
| агар | |||||
| то кӣ | |||||
| бинобар | |||||
| бинобар ин | |||||
| ҳаргиз | |||||
| асло | |||||
| нахот | |||||
| нахот ки | |||||
| кошкӣ | |||||
| шояд | |||||
| шояд ки | |||||
| охир | |||||
| аз рӯи | |||||
| аз рӯйи | |||||
| рӯ | |||||
+ 53
- 0
Models+K-Means/nltk_data/corpora/stopwords/turkish
View File
| @@ -0,0 +1,53 @@ | |||||
| acaba | |||||
| ama | |||||
| aslında | |||||
| az | |||||
| bazı | |||||
| belki | |||||
| biri | |||||
| birkaç | |||||
| birşey | |||||
| biz | |||||
| bu | |||||
| çok | |||||
| çünkü | |||||
| da | |||||
| daha | |||||
| de | |||||
| defa | |||||
| diye | |||||
| eğer | |||||
| en | |||||
| gibi | |||||
| hem | |||||
| hep | |||||
| hepsi | |||||
| her | |||||
| hiç | |||||
| için | |||||
| ile | |||||
| ise | |||||
| kez | |||||
| ki | |||||
| kim | |||||
| mı | |||||
| mu | |||||
| mü | |||||
| nasıl | |||||
| ne | |||||
| neden | |||||
| nerde | |||||
| nerede | |||||
| nereye | |||||
| niçin | |||||
| niye | |||||
| o | |||||
| sanki | |||||
| şey | |||||
| siz | |||||
| şu | |||||
| tüm | |||||
| ve | |||||
| veya | |||||
| ya | |||||
| yani | |||||
BIN
Models+K-Means/nltk_data/tokenizers/punkt_tab.zip
View File
+ 98
- 0
Models+K-Means/nltk_data/tokenizers/punkt_tab/README
View File
| @@ -0,0 +1,98 @@ | |||||
| Pretrained Punkt Models -- Jan Strunk (New version trained after issues 313 and 514 had been corrected) | |||||
| Most models were prepared using the test corpora from Kiss and Strunk (2006). Additional models have | |||||
| been contributed by various people using NLTK for sentence boundary detection. | |||||
| For information about how to use these models, please confer the tokenization HOWTO: | |||||
| http://nltk.googlecode.com/svn/trunk/doc/howto/tokenize.html | |||||
| and chapter 3.8 of the NLTK book: | |||||
| http://nltk.googlecode.com/svn/trunk/doc/book/ch03.html#sec-segmentation | |||||
| There are pretrained tokenizers for the following languages: | |||||
| File Language Source Contents Size of training corpus(in tokens) Model contributed by | |||||
| ======================================================================================================================================================================= | |||||
| czech.pickle Czech Multilingual Corpus 1 (ECI) Lidove Noviny ~345,000 Jan Strunk / Tibor Kiss | |||||
| Literarni Noviny | |||||
| ----------------------------------------------------------------------------------------------------------------------------------------------------------------------- | |||||
| danish.pickle Danish Avisdata CD-Rom Ver. 1.1. 1995 Berlingske Tidende ~550,000 Jan Strunk / Tibor Kiss | |||||
| (Berlingske Avisdata, Copenhagen) Weekend Avisen | |||||
| ----------------------------------------------------------------------------------------------------------------------------------------------------------------------- | |||||
| dutch.pickle Dutch Multilingual Corpus 1 (ECI) De Limburger ~340,000 Jan Strunk / Tibor Kiss | |||||
| ----------------------------------------------------------------------------------------------------------------------------------------------------------------------- | |||||
| english.pickle English Penn Treebank (LDC) Wall Street Journal ~469,000 Jan Strunk / Tibor Kiss | |||||
| (American) | |||||
| ----------------------------------------------------------------------------------------------------------------------------------------------------------------------- | |||||
| estonian.pickle Estonian University of Tartu, Estonia Eesti Ekspress ~359,000 Jan Strunk / Tibor Kiss | |||||
| ----------------------------------------------------------------------------------------------------------------------------------------------------------------------- | |||||
| finnish.pickle Finnish Finnish Parole Corpus, Finnish Books and major national ~364,000 Jan Strunk / Tibor Kiss | |||||
| Text Bank (Suomen Kielen newspapers | |||||
| Tekstipankki) | |||||
| Finnish Center for IT Science | |||||
| (CSC) | |||||
| ----------------------------------------------------------------------------------------------------------------------------------------------------------------------- | |||||
| french.pickle French Multilingual Corpus 1 (ECI) Le Monde ~370,000 Jan Strunk / Tibor Kiss | |||||
| (European) | |||||
| ----------------------------------------------------------------------------------------------------------------------------------------------------------------------- | |||||
| german.pickle German Neue Zürcher Zeitung AG Neue Zürcher Zeitung ~847,000 Jan Strunk / Tibor Kiss | |||||
| (Switzerland) CD-ROM | |||||
| (Uses "ss" | |||||
| instead of "ß") | |||||
| ----------------------------------------------------------------------------------------------------------------------------------------------------------------------- | |||||
| greek.pickle Greek Efstathios Stamatatos To Vima (TO BHMA) ~227,000 Jan Strunk / Tibor Kiss | |||||
| ----------------------------------------------------------------------------------------------------------------------------------------------------------------------- | |||||
| italian.pickle Italian Multilingual Corpus 1 (ECI) La Stampa, Il Mattino ~312,000 Jan Strunk / Tibor Kiss | |||||
| ----------------------------------------------------------------------------------------------------------------------------------------------------------------------- | |||||
| norwegian.pickle Norwegian Centre for Humanities Bergens Tidende ~479,000 Jan Strunk / Tibor Kiss | |||||
| (Bokmål and Information Technologies, | |||||
| Nynorsk) Bergen | |||||
| ----------------------------------------------------------------------------------------------------------------------------------------------------------------------- | |||||
| polish.pickle Polish Polish National Corpus Literature, newspapers, etc. ~1,000,000 Krzysztof Langner | |||||
| (http://www.nkjp.pl/) | |||||
| ----------------------------------------------------------------------------------------------------------------------------------------------------------------------- | |||||
| portuguese.pickle Portuguese CETENFolha Corpus Folha de São Paulo ~321,000 Jan Strunk / Tibor Kiss | |||||
| (Brazilian) (Linguateca) | |||||
| ----------------------------------------------------------------------------------------------------------------------------------------------------------------------- | |||||
| slovene.pickle Slovene TRACTOR Delo ~354,000 Jan Strunk / Tibor Kiss | |||||
| Slovene Academy for Arts | |||||
| and Sciences | |||||
| ----------------------------------------------------------------------------------------------------------------------------------------------------------------------- | |||||
| spanish.pickle Spanish Multilingual Corpus 1 (ECI) Sur ~353,000 Jan Strunk / Tibor Kiss | |||||
| (European) | |||||
| ----------------------------------------------------------------------------------------------------------------------------------------------------------------------- | |||||
| swedish.pickle Swedish Multilingual Corpus 1 (ECI) Dagens Nyheter ~339,000 Jan Strunk / Tibor Kiss | |||||
| (and some other texts) | |||||
| ----------------------------------------------------------------------------------------------------------------------------------------------------------------------- | |||||
| turkish.pickle Turkish METU Turkish Corpus Milliyet ~333,000 Jan Strunk / Tibor Kiss | |||||
| (Türkçe Derlem Projesi) | |||||
| University of Ankara | |||||
| ----------------------------------------------------------------------------------------------------------------------------------------------------------------------- | |||||
| The corpora contained about 400,000 tokens on average and mostly consisted of newspaper text converted to | |||||
| Unicode using the codecs module. | |||||
| Kiss, Tibor and Strunk, Jan (2006): Unsupervised Multilingual Sentence Boundary Detection. | |||||
| Computational Linguistics 32: 485-525. | |||||
| ---- Training Code ---- | |||||
| # import punkt | |||||
| import nltk.tokenize.punkt | |||||
| # Make a new Tokenizer | |||||
| tokenizer = nltk.tokenize.punkt.PunktSentenceTokenizer() | |||||
| # Read in training corpus (one example: Slovene) | |||||
| import codecs | |||||
| text = codecs.open("slovene.plain","Ur","iso-8859-2").read() | |||||
| # Train tokenizer | |||||
| tokenizer.train(text) | |||||
| # Dump pickled tokenizer | |||||
| import pickle | |||||
| out = open("slovene.pickle","wb") | |||||
| pickle.dump(tokenizer, out) | |||||
| out.close() | |||||
| --------- | |||||
+ 118
- 0
Models+K-Means/nltk_data/tokenizers/punkt_tab/czech/abbrev_types.txt
View File
| @@ -0,0 +1,118 @@ | |||||
| t | |||||
| množ | |||||
| např | |||||
| j.h | |||||
| man | |||||
| ú | |||||
| jug | |||||
| dr | |||||
| bl | |||||
| ml | |||||
| okr | |||||
| st | |||||
| uh | |||||
| šp | |||||
| judr | |||||
| u.s.a | |||||
| p | |||||
| arg | |||||
| žitě | |||||
| st.celsia | |||||
| etc | |||||
| p.s | |||||
| t.r | |||||
| lok | |||||
| mil | |||||
| ict | |||||
| n | |||||
| tl | |||||
| min | |||||
| č | |||||
| d | |||||
| al | |||||
| ravenně | |||||
| mj | |||||
| nar | |||||
| plk | |||||
| s.p | |||||
| a.g | |||||
| roč | |||||
| b | |||||
| zdi | |||||
| r.s.c | |||||
| přek | |||||
| m | |||||
| gen | |||||
| csc | |||||
| mudr | |||||
| vic | |||||
| š | |||||
| sb | |||||
| resp | |||||
| tzn | |||||
| iv | |||||
| s.r.o | |||||
| mar | |||||
| w | |||||
| čs | |||||
| vi | |||||
| tzv | |||||
| ul | |||||
| pen | |||||
| zv | |||||
| str | |||||
| čp | |||||
| org | |||||
| rak | |||||
| sv | |||||
| pplk | |||||
| u.s | |||||
| prof | |||||
| c.k | |||||
| op | |||||
| g | |||||
| vii | |||||
| kr | |||||
| ing | |||||
| j.o | |||||
| drsc | |||||
| m3 | |||||
| l | |||||
| tr | |||||
| ceo | |||||
| ch | |||||
| fuk | |||||
| vl | |||||
| viii | |||||
| líp | |||||
| hl.m | |||||
| t.zv | |||||
| phdr | |||||
| o.k | |||||
| tis | |||||
| doc | |||||
| kl | |||||
| ard | |||||
| čkd | |||||
| pok | |||||
| apod | |||||
| r | |||||
| př | |||||
| a.s | |||||
| j | |||||
| jr | |||||
| i.m | |||||
| e | |||||
| kupř | |||||
| f | |||||
| tř | |||||
| xvi | |||||
| mir | |||||
| atď | |||||
| vr | |||||
| r.i.v | |||||
| hl | |||||
| kv | |||||
| t.j | |||||
| y | |||||
| q.p.r | |||||
+ 96
- 0
Models+K-Means/nltk_data/tokenizers/punkt_tab/czech/collocations.tab
View File
| @@ -0,0 +1,96 @@ | |||||
| i dejmala | |||||
| ##number## prosince | |||||
| h steina | |||||
| ##number## listopadu | |||||
| a dvořák | |||||
| v klaus | |||||
| i čnhl | |||||
| ##number## wladyslawowo | |||||
| ##number## letech | |||||
| a jiráska | |||||
| a dubček | |||||
| ##number## štrasburk | |||||
| ##number## juniorské | |||||
| ##number## století | |||||
| ##number## kola | |||||
| ##number## pád | |||||
| ##number## května | |||||
| ##number## týdne | |||||
| v dlouhý | |||||
| k design | |||||
| ##number## červenec | |||||
| i ligy | |||||
| ##number## kolo | |||||
| z svěrák | |||||
| ##number## mája | |||||
| ##number## šimková | |||||
| a bělého | |||||
| a bradáč | |||||
| ##number## ročníku | |||||
| ##number## dubna | |||||
| a vivaldiho | |||||
| v mečiara | |||||
| c carrićre | |||||
| ##number## sjezd | |||||
| ##number## výroční | |||||
| ##number## kole | |||||
| ##number## narozenin | |||||
| k maleevová | |||||
| i čnfl | |||||
| ##number## pádě | |||||
| ##number## září | |||||
| ##number## výročí | |||||
| a dvořáka | |||||
| h g. | |||||
| ##number## ledna | |||||
| a dvorský | |||||
| h měsíc | |||||
| ##number## srpna | |||||
| ##number## tř. | |||||
| a mozarta | |||||
| ##number## sudetoněmeckých | |||||
| o sokolov | |||||
| k škrach | |||||
| v benda | |||||
| ##number## symfonie | |||||
| ##number## července | |||||
| x šalda | |||||
| c abrahama | |||||
| a tichý | |||||
| ##number## místo | |||||
| k bielecki | |||||
| v havel | |||||
| ##number## etapu | |||||
| a dubčeka | |||||
| i liga | |||||
| ##number## světový | |||||
| v klausem | |||||
| ##number## ženy | |||||
| ##number## létech | |||||
| ##number## minutě | |||||
| ##number## listopadem | |||||
| ##number## místě | |||||
| o vlček | |||||
| k peteraje | |||||
| i sponzor | |||||
| ##number## června | |||||
| ##number## min. | |||||
| ##number## oprávněnou | |||||
| ##number## květnu | |||||
| ##number## aktu | |||||
| ##number## květnem | |||||
| ##number## října | |||||
| i rynda | |||||
| ##number## února | |||||
| i snfl | |||||
| a mozart | |||||
| z košler | |||||
| a dvorskému | |||||
| v marhoul | |||||
| v mečiar | |||||
| ##number## ročník | |||||
| ##number## máje | |||||
| v havla | |||||
| k gott | |||||
| s bacha | |||||
| ##number## ad | |||||
+ 52789
- 0
Models+K-Means/nltk_data/tokenizers/punkt_tab/czech/ortho_context.tab
File diff suppressed because it is too large
View File
+ 54
- 0
Models+K-Means/nltk_data/tokenizers/punkt_tab/czech/sent_starters.txt
View File
| @@ -0,0 +1,54 @@ | |||||
| já | |||||
| milena | |||||
| tomáš | |||||
| oznámila | |||||
| podle | |||||
| my | |||||
| vyplývá | |||||
| hlavní | |||||
| jelikož | |||||
| musíme | |||||
| kdyby | |||||
| foto | |||||
| rozptylové | |||||
| snad | |||||
| zároveň | |||||
| jaroslav | |||||
| po | |||||
| v | |||||
| kromě | |||||
| pokud | |||||
| toto | |||||
| jenže | |||||
| oba | |||||
| jak | |||||
| zatímco | |||||
| ten | |||||
| myslím | |||||
| navíc | |||||
| dušan | |||||
| zdá | |||||
| dnes | |||||
| přesto | |||||
| tato | |||||
| ti | |||||
| bratislava | |||||
| ale | |||||
| když | |||||
| nicméně | |||||
| tento | |||||
| mirka | |||||
| přitom | |||||
| dokud | |||||
| jan | |||||
| bohužel | |||||
| ta | |||||
| díky | |||||
| prohlásil | |||||
| praha | |||||
| jestliže | |||||
| jde | |||||
| vždyť | |||||
| moskva | |||||
| proto | |||||
| to | |||||
+ 211
- 0
Models+K-Means/nltk_data/tokenizers/punkt_tab/danish/abbrev_types.txt
View File
| @@ -0,0 +1,211 @@ | |||||
| t | |||||
| tlf | |||||
| b.p | |||||
| evt | |||||
| j.h | |||||
| lenz | |||||
| mht | |||||
| gl | |||||
| bl | |||||
| stud.polit | |||||
| e.j | |||||
| st | |||||
| o | |||||
| dec | |||||
| mag | |||||
| h.b | |||||
| p | |||||
| adm | |||||
| el.lign | |||||
| e.s | |||||
| saalba | |||||
| styrt | |||||
| nr | |||||
| m.a.s.h | |||||
| etc | |||||
| pharm | |||||
| hg | |||||
| j.j | |||||
| dj | |||||
| mountainb | |||||
| f.kr | |||||
| h.r | |||||
| cand.jur | |||||
| sp | |||||
| osv | |||||
| s.g | |||||
| ndr | |||||
| inc | |||||
| b.i.g | |||||
| dk-sver | |||||
| sl | |||||
| v.s.o.d | |||||
| cand.mag | |||||
| d.v.s | |||||
| v.i | |||||
| bøddel | |||||
| fr | |||||
| ø« | |||||
| dr.phil | |||||
| chr | |||||
| p.d | |||||
| bj | |||||
| fhv | |||||
| tilskudsforhold | |||||
| m.a | |||||
| sek | |||||
| p.g.a | |||||
| int | |||||
| pokalf | |||||
| ik | |||||
| dir | |||||
| em-lodtrækn | |||||
| a.h | |||||
| o.lign | |||||
| p.t | |||||
| m.v | |||||
| n.j | |||||
| m.h.t | |||||
| m.m | |||||
| a.p | |||||
| pers | |||||
| 4-bakketurn | |||||
| dr.med | |||||
| w.ø | |||||
| polit | |||||
| fremsættes | |||||
| techn | |||||
| tidl | |||||
| o.g | |||||
| i.c.i | |||||
| mill | |||||
| skt | |||||
| m.fl | |||||
| cand.merc | |||||
| kbh | |||||
| indiv | |||||
| stk | |||||
| dk-maked | |||||
| memorandum | |||||
| mestersk | |||||
| mag.art | |||||
| kitzb | |||||
| h | |||||
| lic | |||||
| fig | |||||
| dressurst | |||||
| sportsg | |||||
| r.e.m | |||||
| d.u.m | |||||
| sct | |||||
| kld | |||||
| bl.a | |||||
| hf | |||||
| g.a | |||||
| corp | |||||
| w | |||||
| konk | |||||
| zoeterm | |||||
| b.t | |||||
| a.d | |||||
| l.b | |||||
| jf | |||||
| s.b | |||||
| kgl | |||||
| ill | |||||
| beck | |||||
| tosset | |||||
| afd | |||||
| johs | |||||
| pct | |||||
| k.b | |||||
| sv | |||||
| verbalt | |||||
| kgs | |||||
| l.m.k | |||||
| j.l | |||||
| aus | |||||
| superl | |||||
| t.v | |||||
| mia | |||||
| kr | |||||
| pr | |||||
| præmien | |||||
| j.b.s | |||||
| j.o | |||||
| o.s.v | |||||
| edb-oplysninger | |||||
| o.m.a | |||||
| ca | |||||
| 1b | |||||
| f.eks | |||||
| rens | |||||
| ch | |||||
| mr | |||||
| schw | |||||
| d.c | |||||
| utraditionelt | |||||
| idrætsgym | |||||
| hhv | |||||
| e.l | |||||
| s.s | |||||
| eks | |||||
| f.o.m | |||||
| dk-storbrit | |||||
| dk-jugo | |||||
| n.z | |||||
| derivater | |||||
| c | |||||
| pt | |||||
| vm-kval | |||||
| kl | |||||
| hr | |||||
| cand | |||||
| jur | |||||
| sav | |||||
| h.c | |||||
| arab.-danm | |||||
| d.a.d | |||||
| fl | |||||
| o.a | |||||
| a.s | |||||
| cand.polit | |||||
| grundejerform | |||||
| j | |||||
| faglærte | |||||
| cr | |||||
| a.a | |||||
| mou | |||||
| f.r.i | |||||
| årh | |||||
| o.m.m | |||||
| sve | |||||
| c.a | |||||
| engl | |||||
| sikkerhedssystemerne | |||||
| m.f | |||||
| j.k | |||||
| phil | |||||
| f | |||||
| vet | |||||
| mio | |||||
| k.e | |||||
| m.k | |||||
| atla | |||||
| idrætsg | |||||
| n.n | |||||
| 4-bakketur | |||||
| dvs | |||||
| sdr | |||||
| s.j | |||||
| hol | |||||
| s.h | |||||
| pei | |||||
| kbhvn | |||||
| aa | |||||
| m.g.i | |||||
| fvt | |||||
| i« | |||||
| b.c | |||||
| th | |||||
| lrs | |||||
+ 101
- 0
Models+K-Means/nltk_data/tokenizers/punkt_tab/danish/collocations.tab
View File
| @@ -0,0 +1,101 @@ | |||||
| ##number## skak | |||||
| ##number## speedway | |||||
| ##number## rally | |||||
| ##number## april | |||||
| ##number## dm-fin | |||||
| ##number## viceformand | |||||
| m jensen | |||||
| ##number## kano/kajak | |||||
| ##number## bowling | |||||
| ##number## dm-finale | |||||
| ##number## årh. | |||||
| ##number## januar | |||||
| ##number## august | |||||
| ##number## marathon | |||||
| ##number## kamp | |||||
| ##number## skihop | |||||
| ##number## etage | |||||
| ##number## tennis | |||||
| ##number## cykling | |||||
| e andersen | |||||
| ##number## december | |||||
| g h. | |||||
| ##number## neb | |||||
| ##number## sektion | |||||
| ##number## afd. | |||||
| ##number## klasse | |||||
| ##number## trampolin | |||||
| ##number## bordtennis | |||||
| ##number## formel | |||||
| ##number## århundredes | |||||
| ##number## dm-semifin | |||||
| ##number## heks | |||||
| ##number## taekwondo | |||||
| ##number## galop | |||||
| ##number## basketball | |||||
| ##number## dm | |||||
| m skræl | |||||
| ##number## trav | |||||
| ##number## provins | |||||
| ##number## triathlon | |||||
| k axel | |||||
| ##number## rugby | |||||
| s h. | |||||
| ##number## klaverkoncert | |||||
| a p. | |||||
| e løgstrup | |||||
| k telefax | |||||
| ##number## gyldendal | |||||
| ##number## fodbold | |||||
| e rosenfeldt | |||||
| ##number## oktober | |||||
| k o. | |||||
| ##number## september | |||||
| ##number## dec. | |||||
| ##number## juledag | |||||
| ##number## badminton | |||||
| ##number## sejlsport | |||||
| ##number## håndbold | |||||
| r førsund | |||||
| e jørgensen | |||||
| d ##number## | |||||
| k e | |||||
| ##number## alp.ski | |||||
| ##number## judo | |||||
| ##number## roning | |||||
| ##number## november | |||||
| ##number## atletik | |||||
| ##number## århundrede | |||||
| ##number## ridning | |||||
| ##number## marts | |||||
| m andersen | |||||
| d roosevelt | |||||
| ##number## brydning | |||||
| s kr. | |||||
| ##number## runde | |||||
| ##number## division | |||||
| ##number## sal | |||||
| ##number## boksning | |||||
| ##number## minut | |||||
| ##number## golf | |||||
| ##number## juni | |||||
| ##number## symfoni | |||||
| ##number## hurtigløb | |||||
| k jørgensen | |||||
| ##number## jörgen | |||||
| ##number## klasses | |||||
| e jacobsen | |||||
| k jensen | |||||
| ##number## februar | |||||
| k nielsen | |||||
| ##number## volleyball | |||||
| ##number## maj | |||||
| ##number## verdenskrig | |||||
| ##number## juli | |||||
| ##number## ishockey | |||||
| ##number## kunstskøjteløb | |||||
| b jørgensen | |||||
| ##number## gymnastik | |||||
| ##number## svømning | |||||
| ##number## tw | |||||
| i pedersens | |||||
+ 53913
- 0
Models+K-Means/nltk_data/tokenizers/punkt_tab/danish/ortho_context.tab
File diff suppressed because it is too large
View File
+ 64
- 0
Models+K-Means/nltk_data/tokenizers/punkt_tab/danish/sent_starters.txt
View File
| @@ -0,0 +1,64 @@ | |||||
| kronik | |||||
| alligevel | |||||
| de | |||||
| først | |||||
| derfor | |||||
| vi | |||||
| selv | |||||
| hertil | |||||
| sådan | |||||
| dette | |||||
| sport | |||||
| man | |||||
| foto | |||||
| begge | |||||
| tag | |||||
| dertil | |||||
| reuter | |||||
| efter | |||||
| endelig | |||||
| ifølge | |||||
| lad | |||||
| når | |||||
| det | |||||
| desuden | |||||
| nu | |||||
| reuters | |||||
| årsagen | |||||
| tænk | |||||
| samtidig | |||||
| udover | |||||
| men | |||||
| endvidere | |||||
| rør | |||||
| rb | |||||
| udstillingen | |||||
| faktabox | |||||
| reception | |||||
| blandt | |||||
| hvad | |||||
| skær | |||||
| lilot | |||||
| derudover | |||||
| da | |||||
| tilsæt | |||||
| denne | |||||
| afp | |||||
| her | |||||
| hvis | |||||
| hæld | |||||
| problemet | |||||
| dermed | |||||
| jeg | |||||
| grafik | |||||
| anmeldelse | |||||
| den | |||||
| ebbe | |||||
| resultatet | |||||
| tværtimod | |||||
| hans | |||||
| måske | |||||
| feature | |||||
| tillæg | |||||
| hun | |||||
| han | |||||
+ 99
- 0
Models+K-Means/nltk_data/tokenizers/punkt_tab/dutch/abbrev_types.txt
View File
| @@ -0,0 +1,99 @@ | |||||
| m.j | |||||
| t | |||||
| ph | |||||
| j.h | |||||
| p.a.m | |||||
| j.m | |||||
| dr | |||||
| st | |||||
| j.b.m | |||||
| p | |||||
| nr | |||||
| h.s | |||||
| e.d | |||||
| t.e | |||||
| a.v | |||||
| esb | |||||
| s.z | |||||
| drs | |||||
| b.b | |||||
| m.o | |||||
| inc | |||||
| n | |||||
| pensioenfonds | |||||
| s.v.p | |||||
| bod | |||||
| fr | |||||
| pk | |||||
| r.p | |||||
| c.p.j | |||||
| v.l.n.r | |||||
| chr | |||||
| m.v.d | |||||
| int | |||||
| o.m | |||||
| j.v.d | |||||
| u.o.m | |||||
| f.c | |||||
| k | |||||
| bijgebracht | |||||
| ontwaakte | |||||
| m | |||||
| j.w | |||||
| a.l | |||||
| a.v.d | |||||
| s.v | |||||
| s | |||||
| j.d | |||||
| binnengekomen | |||||
| ds | |||||
| schouwburg | |||||
| b.v | |||||
| h | |||||
| a | |||||
| j.a | |||||
| aanvielen | |||||
| h.g | |||||
| p.f | |||||
| j.l | |||||
| mgr | |||||
| c.j | |||||
| blz | |||||
| l.e.h | |||||
| w.k | |||||
| g | |||||
| m.g | |||||
| r.v.d | |||||
| ing | |||||
| v.d | |||||
| c.q | |||||
| l | |||||
| h.p | |||||
| mr | |||||
| gesch | |||||
| e.l | |||||
| p.j | |||||
| mm | |||||
| j.g | |||||
| j.f | |||||
| c | |||||
| f.m | |||||
| jl | |||||
| r | |||||
| o.a | |||||
| a.s | |||||
| ir | |||||
| v | |||||
| j | |||||
| jr | |||||
| e | |||||
| m.i.v | |||||
| l.a | |||||
| f.v.d | |||||
| aansluit | |||||
| c.c | |||||
| a.m | |||||
| f.o.j | |||||
| m.b | |||||
| y | |||||
| th | |||||
+ 37
- 0
Models+K-Means/nltk_data/tokenizers/punkt_tab/dutch/collocations.tab
View File
| @@ -0,0 +1,37 @@ | |||||
| ##number## sotelo | |||||
| ##number## clas | |||||
| ##number## buckler | |||||
| ##number## carrera | |||||
| ##number## rmo | |||||
| ##number## orioli | |||||
| w baron | |||||
| ##number## morales | |||||
| ##number## snotselelaank | |||||
| ##number## arcarons | |||||
| ##number## cavandoli | |||||
| ##number## pdm | |||||
| ##number## helvetia | |||||
| ##number## panasonic | |||||
| ##number## motorola | |||||
| w bruinsma | |||||
| ##number## heer | |||||
| ##number## lotus | |||||
| ##number## banesto | |||||
| ##number## magnaldi | |||||
| w jense | |||||
| w heuvelmans | |||||
| w spatje | |||||
| ##number## telekom | |||||
| f kennedy | |||||
| ##number## gatorade | |||||
| ##number## mg-gb | |||||
| ##number## once | |||||
| ##number## peterhansel | |||||
| ##number## ariostea | |||||
| ##number## tvm | |||||
| ##number## höl | |||||
| ##number## castorama | |||||
| ##number## tulip | |||||
| b situatie | |||||
| ##number## mas | |||||
| ##number## lotto | |||||
+ 32208
- 0
Models+K-Means/nltk_data/tokenizers/punkt_tab/dutch/ortho_context.tab
File diff suppressed because it is too large
View File
+ 54
- 0
Models+K-Means/nltk_data/tokenizers/punkt_tab/dutch/sent_starters.txt
View File
| @@ -0,0 +1,54 @@ | |||||
| het | |||||
| daardoor | |||||
| de | |||||
| er | |||||
| hoewel | |||||
| wat | |||||
| urlings | |||||
| na | |||||
| ze | |||||
| alleen | |||||
| dat | |||||
| ik | |||||
| pijls | |||||
| wie | |||||
| daarna | |||||
| foto | |||||
| als | |||||
| boer | |||||
| hammes | |||||
| verder | |||||
| ook | |||||
| evers | |||||
| vandaar | |||||
| toen | |||||
| we | |||||
| langenberg | |||||
| naast | |||||
| want | |||||
| in | |||||
| wij | |||||
| zo | |||||
| hendrikx | |||||
| daar | |||||
| crouzen | |||||
| dit | |||||
| daarnaast | |||||
| anp | |||||
| zij | |||||
| behalve | |||||
| waarom | |||||
| daarom | |||||
| bovendien | |||||
| hij | |||||
| daarbij | |||||
| nee | |||||
| volgens | |||||
| daarmee | |||||
| bukkems | |||||
| dvnl | |||||
| eén | |||||
| pas | |||||
| tijdens | |||||
| vooral | |||||
| maar | |||||
+ 156
- 0
Models+K-Means/nltk_data/tokenizers/punkt_tab/english/abbrev_types.txt
View File
| @@ -0,0 +1,156 @@ | |||||
| ct | |||||
| m.j | |||||
| t | |||||
| a.c | |||||
| n.h | |||||
| ms | |||||
| p.a.m | |||||
| dr | |||||
| pa | |||||
| p.m | |||||
| u.k | |||||
| st | |||||
| dec | |||||
| u.s.a | |||||
| lt | |||||
| g.k | |||||
| adm | |||||
| p | |||||
| h.m | |||||
| ga | |||||
| tenn | |||||
| yr | |||||
| sen | |||||
| n.c | |||||
| j.j | |||||
| d.h | |||||
| s.g | |||||
| inc | |||||
| vs | |||||
| s.p.a | |||||
| a.t | |||||
| n | |||||
| feb | |||||
| sr | |||||
| jan | |||||
| s.a.y | |||||
| n.y | |||||
| col | |||||
| g.f | |||||
| c.o.m.b | |||||
| d | |||||
| ft | |||||
| va | |||||
| r.k | |||||
| e.f | |||||
| chg | |||||
| r.i | |||||
| a.g | |||||
| minn | |||||
| a.h | |||||
| k | |||||
| n.j | |||||
| m | |||||
| l.f | |||||
| f.j | |||||
| gen | |||||
| i.m.s | |||||
| s.a | |||||
| aug | |||||
| j.p | |||||
| okla | |||||
| m.d.c | |||||
| ltd | |||||
| oct | |||||
| s | |||||
| vt | |||||
| r.a | |||||
| j.c | |||||
| ariz | |||||
| w.w | |||||
| b.v | |||||
| ore | |||||
| h | |||||
| w.r | |||||
| e.h | |||||
| mrs | |||||
| cie | |||||
| corp | |||||
| w | |||||
| n.v | |||||
| a.d | |||||
| r.j | |||||
| ok | |||||
| . . | |||||
| e.m | |||||
| w.c | |||||
| ill | |||||
| nov | |||||
| u.s | |||||
| prof | |||||
| conn | |||||
| u.s.s.r | |||||
| mg | |||||
| f.g | |||||
| ph.d | |||||
| g | |||||
| calif | |||||
| messrs | |||||
| h.f | |||||
| wash | |||||
| tues | |||||
| sw | |||||
| bros | |||||
| u.n | |||||
| l | |||||
| wis | |||||
| mr | |||||
| sep | |||||
| d.c | |||||
| ave | |||||
| e.l | |||||
| co | |||||
| s.s | |||||
| reps | |||||
| c | |||||
| r.t | |||||
| h.c | |||||
| r | |||||
| wed | |||||
| a.s | |||||
| v | |||||
| fla | |||||
| jr | |||||
| r.h | |||||
| c.v | |||||
| m.b.a | |||||
| rep | |||||
| a.a | |||||
| e | |||||
| c.i.t | |||||
| l.a | |||||
| b.f | |||||
| j.b | |||||
| d.w | |||||
| j.k | |||||
| ala | |||||
| f | |||||
| w.va | |||||
| sept | |||||
| mich | |||||
| n.m | |||||
| j.r | |||||
| l.p | |||||
| s.c | |||||
| colo | |||||
| fri | |||||
| a.m | |||||
| g.d | |||||
| kan | |||||
| maj | |||||
| ky | |||||
| a.m.e | |||||
| n.d | |||||
| t.j | |||||
| cos | |||||
| nev | |||||
+ 37
- 0
Models+K-Means/nltk_data/tokenizers/punkt_tab/english/collocations.tab
View File
| @@ -0,0 +1,37 @@ | |||||
| ##number## international | |||||
| ##number## rj | |||||
| ##number## commodities | |||||
| ##number## cooper | |||||
| b stewart | |||||
| ##number## genentech | |||||
| ##number## wedgestone | |||||
| i toussie | |||||
| ##number## pepper | |||||
| j fialka | |||||
| o ludcke | |||||
| ##number## insider | |||||
| ##number## aes | |||||
| i magnin | |||||
| ##number## credit | |||||
| ##number## corrections | |||||
| ##number## financing | |||||
| ##number## henley | |||||
| ##number## business | |||||
| ##number## pay-fone | |||||
| b wigton | |||||
| b edelman | |||||
| b levine | |||||
| ##number## leisure | |||||
| b smith | |||||
| j walter | |||||
| ##number## pegasus | |||||
| ##number## dividend | |||||
| j aron | |||||
| ##number## review | |||||
| ##number## abreast | |||||
| ##number## who | |||||
| ##number## letters | |||||
| ##number## colgate | |||||
| ##number## cbot | |||||
| ##number## notable | |||||
| ##number## zimmer | |||||
+ 20366
- 0
Models+K-Means/nltk_data/tokenizers/punkt_tab/english/ortho_context.tab
File diff suppressed because it is too large
View File
+ 39
- 0
Models+K-Means/nltk_data/tokenizers/punkt_tab/english/sent_starters.txt
View File
| @@ -0,0 +1,39 @@ | |||||
| most | |||||
| he | |||||
| since | |||||
| so | |||||
| both | |||||
| these | |||||
| it | |||||
| nevertheless | |||||
| this | |||||
| indeed | |||||
| however | |||||
| instead | |||||
| under | |||||
| similarly | |||||
| some | |||||
| though | |||||
| while | |||||
| when | |||||
| in | |||||
| despite | |||||
| although | |||||
| nonetheless | |||||
| thus | |||||
| there | |||||
| if | |||||
| the | |||||
| nor | |||||
| separately | |||||
| moreover | |||||
| but | |||||
| they | |||||
| yet | |||||
| many | |||||
| according | |||||
| sales | |||||
| among | |||||
| meanwhile | |||||
| even | |||||
| i | |||||
+ 48
- 0
Models+K-Means/nltk_data/tokenizers/punkt_tab/estonian/abbrev_types.txt
View File
| @@ -0,0 +1,48 @@ | |||||
| eos | |||||
| c | |||||
| a.d | |||||
| t.a.s.s | |||||
| e.t | |||||
| päevapiltnikud | |||||
| c.h | |||||
| b.p | |||||
| amm | |||||
| ameerika-mees | |||||
| n.-ö | |||||
| cm | |||||
| b | |||||
| mhm | |||||
| a.s | |||||
| m.e | |||||
| j.l | |||||
| j | |||||
| u.t | |||||
| vm | |||||
| g.u.n | |||||
| hajutada | |||||
| p.s | |||||
| a.b | |||||
| c.h.-r | |||||
| i.q | |||||
| gr | |||||
| fido | |||||
| pankurit | |||||
| s.v | |||||
| l.l | |||||
| c.-h | |||||
| m.h | |||||
| h.l | |||||
| m.k | |||||
| j.r | |||||
| t.k | |||||
| k.h | |||||
| 89/90 | |||||
| h | |||||
| a | |||||
| dost | |||||
| v.k | |||||
| e.q | |||||
| t.j | |||||
| m.b | |||||
| d | |||||
| p.k | |||||
+ 100
- 0
Models+K-Means/nltk_data/tokenizers/punkt_tab/estonian/collocations.tab
View File
| @@ -0,0 +1,100 @@ | |||||
| ##number## juuni | |||||
| ##number## novembril | |||||
| ##number## juulilt | |||||
| r järve-vomm | |||||
| ##number## mida | |||||
| n liidu | |||||
| ##number## milliseid | |||||
| ##number## oktoobri | |||||
| ##number## iidol | |||||
| m e | |||||
| ##number## klassist | |||||
| ##number## millest | |||||
| ##number## august | |||||
| ##number## pariis | |||||
| ##number## septembrist | |||||
| ##number## oktoober | |||||
| ##number## märtsini | |||||
| ##number## kust | |||||
| k mägi | |||||
| ##number## detsembrist | |||||
| ##number## jaanuari | |||||
| ##number## epee | |||||
| ##number## nimetage | |||||
| ##number## novembrini | |||||
| ##number## eluaasta | |||||
| s mill | |||||
| ##number## helsingi | |||||
| ##number## jaanuarini | |||||
| ##number## aastail | |||||
| ##number## augustil | |||||
| ##number## millise | |||||
| ##number## juulist | |||||
| ##number## mai | |||||
| ##number## novembri | |||||
| ##number## oktoobrist | |||||
| ##number## juunini | |||||
| ##number## septembriks | |||||
| ##number## detsembril | |||||
| p s | |||||
| ##number## jaanuar | |||||
| ##number## aastate | |||||
| ##number## milline | |||||
| ##number## kelle | |||||
| ##number## jaanuaril | |||||
| s stadnikov | |||||
| ##number## aastaks | |||||
| ##number## stockholm | |||||
| ##number## suurim | |||||
| ##number## aasta | |||||
| ##number## sajandi | |||||
| ##number## millega | |||||
| ##number## aastast | |||||
| ##number## aastal | |||||
| ##number## kumb | |||||
| ##number## septembril | |||||
| ##number## korruselt | |||||
| ##number## septembri | |||||
| ##number## veebruarini | |||||
| ##number## london | |||||
| ##number## aastatel | |||||
| ##number## september | |||||
| ##number## veebruari | |||||
| ##number## oktoobrini | |||||
| ##number## mail | |||||
| m kassovitz | |||||
| ##number## action-film | |||||
| ##number## mis | |||||
| k herkül | |||||
| n n | |||||
| ##number## detsembrini | |||||
| ##number## imre | |||||
| t jõgeda | |||||
| ##number## casino | |||||
| ##number## septembrit | |||||
| ##number## augustini | |||||
| ##number## juulil | |||||
| ##number## november | |||||
| ##number## kuupäeval | |||||
| ##number## taevas | |||||
| ##number## septembrini | |||||
| ##number## detsember | |||||
| ##number## detsembri | |||||
| ##number## juunil | |||||
| ##number## augustist | |||||
| n jurist | |||||
| ##number## missugust | |||||
| ##number## aastatesse | |||||
| ##number## aprillil | |||||
| ##number## augusti | |||||
| ##number## oktoobril | |||||
| ##number## märtsil | |||||
| ##number## a | |||||
| ##number## the | |||||
| ##number## sajandil | |||||
| ##number## aastani | |||||
| ##number## juuli | |||||
| ##number## septembrile | |||||
| ##number## millist | |||||
| ##number## millised | |||||
| ##number## veebruaril | |||||