 troyyyyy
1 year ago
troyyyyy
1 year ago
38 changed files with 266 additions and 241 deletions
Split View
Diff Options
-
+1 -1.github/workflows/build-and-test.yaml
-
+3 -4.gitignore
-
+28 -23README.md
-
+1 -3ablkit/bridge/base_bridge.py
-
+16 -7ablkit/bridge/simple_bridge.py
-
+1 -1ablkit/data/data_converter.py
-
+1 -1ablkit/data/evaluation/base_metric.py
-
+2 -2ablkit/data/evaluation/reasoning_metric.py
-
+1 -1ablkit/data/evaluation/symbol_accuracy.py
-
+2 -2ablkit/data/structures/list_data.py
-
+31 -25ablkit/learning/basic_nn.py
-
+23 -23ablkit/learning/model_converter.py
-
+8 -6ablkit/reasoning/reasoner.py
-
+1 -1ablkit/utils/logger.py
-
+1 -1ablkit/utils/utils.py
-
+1 -1docs/Examples/HED.rst
-
+2 -2docs/Examples/HWF.rst
-
+2 -2docs/Examples/MNISTAdd.rst
-
+2 -2docs/Examples/Zoo.rst
-
+6 -6docs/Intro/Basics.rst
-
+3 -4docs/Intro/Bridge.rst
-
+5 -5docs/Intro/Datasets.rst
-
+1 -1docs/Intro/Evaluation.rst
-
+2 -2docs/Intro/Learning.rst
-
+4 -4docs/Intro/Quick-Start.rst
-
+12 -10docs/Intro/Reasoning.rst
-
+1 -1docs/Makefile
-
+3 -3docs/Overview/Installation.rst
-
+0 -87docs/README.rst
-
BINdocs/_static/img/ABLKit.png
-
BINdocs/_static/img/ABLkit.png
-
BINdocs/_static/img/logo.png
-
+1 -1docs/conf.py
-
+94 -2docs/index.rst
-
+1 -1examples/hwf/hwf.ipynb
-
+2 -2examples/mnist_add/mnist_add.ipynb
-
+1 -1examples/zoo/zoo.ipynb
-
+3 -3pyproject.toml
+ 1
- 1
.github/workflows/build-and-test.yaml
View File
| @@ -1,4 +1,4 @@ | |||
| name: ABLKit-CI | |||
| name: ABLkit-CI | |||
| on: | |||
| push: | |||
+ 3
- 4
.gitignore
View File
| @@ -6,10 +6,9 @@ examples/**/*.png | |||
| *.ckpt | |||
| results | |||
| raw/ | |||
| abl.egg-info/ | |||
| ablkit.egg-info/ | |||
| *.egg-info/ | |||
| examples/**/*.jpg | |||
| .idea/ | |||
| build/ | |||
| docs/API/generated/ | |||
| .history | |||
| .history | |||
| dist | |||
+ 28
- 23
README.md
View File
| @@ -1,49 +1,54 @@ | |||
| <div align="center"> | |||
| <p align="center"> | |||
| <img src="https://raw.githubusercontent.com/AbductiveLearning/ABLkit/main/docs/_static/img/logo.png" alt="ABLkit logo" style="width: 35%;"/> | |||
| </p> | |||
| <br> | |||
| [](https://pypi.org/project/ablkit/) | |||
| [](https://pypi.org/project/ablkit/) | |||
| [](https://ablkit.readthedocs.io/en/latest/?badge=latest) | |||
| [](https://github.com/AbductiveLearning/ABLKit/blob/main/LICENSE) | |||
| [](https://github.com/AbductiveLearning/ABLKit/actions/workflows/lint.yaml) | |||
| [](https://github.com/AbductiveLearning/ABLkit/blob/main/LICENSE) | |||
| [](https://github.com/AbductiveLearning/ABLkit/actions/workflows/lint.yaml) | |||
| [](https://github.com/psf/black) | |||
| [](https://github.com/AbductiveLearning/ABLKit/actions/workflows/build-and-test.yaml) | |||
| [](https://github.com/AbductiveLearning/ABLkit/actions/workflows/build-and-test.yaml) | |||
| [📘Documentation](https://ablkit.readthedocs.io/en/latest/index.html) | | |||
| [📚Examples](https://github.com/AbductiveLearning/ABLKit/tree/main/examples) | | |||
| [💬Reporting Issues](https://github.com/AbductiveLearning/ABLKit/issues/new) | |||
| [📚Examples](https://github.com/AbductiveLearning/ABLkit/tree/main/examples) | | |||
| [💬Reporting Issues](https://github.com/AbductiveLearning/ABLkit/issues/new) | |||
| </div> | |||
| # ABL Kit: A Python Toolkit for Abductive Learning | |||
| # ABLkit: A Python Toolkit for Abductive Learning | |||
| **ABL Kit** is an efficient Python toolkit for **Abductive Learning (ABL)**. | |||
| **ABLkit** is an efficient Python toolkit for [**Abductive Learning (ABL)**](https://www.lamda.nju.edu.cn/publication/chap_ABL.pdf). | |||
| ABL is a novel paradigm that integrates machine learning and | |||
| logical reasoning in a unified framework. It is suitable for tasks | |||
| where both data and (logical) domain knowledge are available. | |||
| <p align="center"> | |||
| <img src="docs/_static/img/ABL.png" alt="Abductive Learning" style="width: 80%;"/> | |||
| <img src="https://raw.githubusercontent.com/AbductiveLearning/ABLkit/main/docs/_static/img/ABL.png" alt="Abductive Learning" style="width: 80%;"/> | |||
| </p> | |||
| Key Features of ABL Kit: | |||
| Key Features of ABLkit: | |||
| - **Great Flexibility**: Adaptable to various machine learning modules and logical reasoning components. | |||
| - **User-Friendly**: Provide data, model, and KB, and get started with just a few lines of code. | |||
| - **High-Performance**: Optimization for high accuracy and fast training speed. | |||
| ABL Kit encapsulates advanced ABL techniques, providing users with | |||
| ABLkit encapsulates advanced ABL techniques, providing users with | |||
| an efficient and convenient toolkit to develop dual-driven ABL systems, | |||
| which leverage the power of both data and knowledge. | |||
| <p align="center"> | |||
| <img src="docs/_static/img/ABLKit.png" alt="ABL Kit" style="width: 80%;"/> | |||
| <img src="https://raw.githubusercontent.com/AbductiveLearning/ABLkit/main/docs/_static/img/ABLKit.png" alt="ABLkit" style="width: 80%;"/> | |||
| </p> | |||
| ## Installation | |||
| ### Install from PyPI | |||
| The easiest way to install ABL Kit is using ``pip``: | |||
| The easiest way to install ABLkit is using ``pip``: | |||
| ```bash | |||
| pip install ablkit | |||
| @@ -54,8 +59,8 @@ pip install ablkit | |||
| Alternatively, to install from source code, sequentially run following commands in your terminal/command line. | |||
| ```bash | |||
| git clone https://github.com/AbductiveLearning/ABLKit.git | |||
| cd ABLKit | |||
| git clone https://github.com/AbductiveLearning/ABLkit.git | |||
| cd ABLkit | |||
| pip install -v -e . | |||
| ``` | |||
| @@ -79,7 +84,7 @@ We use the MNIST Addition task as a quick start example. In this task, pairs of | |||
| <summary>Working with Data</summary> | |||
| <br> | |||
| ABL Kit requires data in the format of `(X, gt_pseudo_label, Y)` where `X` is a list of input examples containing instances, `gt_pseudo_label` is the ground-truth label of each example in `X` and `Y` is the ground-truth reasoning result of each example in `X`. Note that `gt_pseudo_label` is only used to evaluate the machine learning model's performance but not to train it. | |||
| ABLkit requires data in the format of `(X, gt_pseudo_label, Y)` where `X` is a list of input examples containing instances, `gt_pseudo_label` is the ground-truth label of each example in `X` and `Y` is the ground-truth reasoning result of each example in `X`. Note that `gt_pseudo_label` is only used to evaluate the machine learning model's performance but not to train it. | |||
| In the MNIST Addition task, the data loading looks like: | |||
| @@ -98,7 +103,7 @@ test_data = get_dataset(train=False) | |||
| <summary>Building the Learning Part</summary> | |||
| <br> | |||
| Learning part is constructed by first defining a base model for machine learning. ABL Kit offers considerable flexibility, supporting any base model that conforms to the scikit-learn style (which requires the implementation of fit and predict methods), or a PyTorch-based neural network (which has defined the architecture and implemented forward method). In this example, we build a simple LeNet5 network as the base model. | |||
| Learning part is constructed by first defining a base model for machine learning. ABLkit offers considerable flexibility, supporting any base model that conforms to the scikit-learn style (which requires the implementation of `fit` and `predict` methods), or a PyTorch-based neural network (which has defined the architecture and implemented `forward` method). In this example, we build a simple LeNet5 network as the base model. | |||
| ```python | |||
| # The 'models' module below is located in 'examples/mnist_add/' | |||
| @@ -107,7 +112,7 @@ from models.nn import LeNet5 | |||
| cls = LeNet5(num_classes=10) | |||
| ``` | |||
| To facilitate uniform processing, ABL Kit provides the `BasicNN` class to convert a PyTorch-based neural network into a format compatible with scikit-learn models. To construct a `BasicNN` instance, aside from the network itself, we also need to define a loss function, an optimizer, and the computing device. | |||
| To facilitate uniform processing, ABLkit provides the `BasicNN` class to convert a PyTorch-based neural network into a format compatible with scikit-learn models. To construct a `BasicNN` instance, aside from the network itself, we also need to define a loss function, an optimizer, and the computing device. | |||
| ```python | |||
| import torch | |||
| @@ -119,7 +124,7 @@ To facilitate uniform processing, ABL Kit provides the `BasicNN` class to conver | |||
| base_model = BasicNN(model=cls, loss_fn=loss_fn, optimizer=optimizer, device=device) | |||
| ``` | |||
| The base model built above is trained to make predictions on instance-level data (e.g., a single image), while ABL deals with example-level data. To bridge this gap, we wrap the base_model into an instance of `ABLModel`. This class serves as a unified wrapper for base models, facilitating the learning part to train, test, and predict on example-level data, (e.g., images that comprise an equation). | |||
| The base model built above is trained to make predictions on instance-level data (e.g., a single image), while ABL deals with example-level data. To bridge this gap, we wrap the `base_model` into an instance of `ABLModel`. This class serves as a unified wrapper for base models, facilitating the learning part to train, test, and predict on example-level data, (e.g., images that comprise an equation). | |||
| ```python | |||
| from ablkit.learning import ABLModel | |||
| @@ -162,7 +167,7 @@ reasoner = Reasoner(kb) | |||
| <summary>Building Evaluation Metrics</summary> | |||
| <br> | |||
| ABL Kit provides two basic metrics, namely `SymbolAccuracy` and `ReasoningMetric`, which are used to evaluate the accuracy of the machine learning model's predictions and the accuracy of the `logic_forward` results, respectively. | |||
| ABLkit provides two basic metrics, namely `SymbolAccuracy` and `ReasoningMetric`, which are used to evaluate the accuracy of the machine learning model's predictions and the accuracy of the `logic_forward` results, respectively. | |||
| ```python | |||
| from ablkit.data.evaluation import ReasoningMetric, SymbolAccuracy | |||
| @@ -200,10 +205,10 @@ To explore detailed tutorials and information, please refer to - [document](http | |||
| We provide several examples in `examples/`. Each example is stored in a separate folder containing a README file. | |||
| + [MNIST Addition](https://github.com/AbductiveLearning/ABLKit/tree/main/examples/mnist_add) | |||
| + [Handwritten Formula (HWF)](https://github.com/AbductiveLearning/ABLKit/tree/main/examples/hwf) | |||
| + [Handwritten Equation Decipherment](https://github.com/AbductiveLearning/ABLKit/tree/main/examples/hed) | |||
| + [Zoo](https://github.com/AbductiveLearning/ABLKit/tree/main/examples/zoo) | |||
| + [MNIST Addition](https://github.com/AbductiveLearning/ABLkit/tree/main/examples/mnist_add) | |||
| + [Handwritten Formula (HWF)](https://github.com/AbductiveLearning/ABLkit/tree/main/examples/hwf) | |||
| + [Handwritten Equation Decipherment](https://github.com/AbductiveLearning/ABLkit/tree/main/examples/hed) | |||
| + [Zoo](https://github.com/AbductiveLearning/ABLkit/tree/main/examples/zoo) | |||
| ## References | |||
+ 1
- 3
ablkit/bridge/base_bridge.py
View File
| @@ -36,9 +36,7 @@ class BaseBridge(metaclass=ABCMeta): | |||
| def __init__(self, model: ABLModel, reasoner: Reasoner) -> None: | |||
| if not isinstance(model, ABLModel): | |||
| raise TypeError( | |||
| f"Expected an instance of ABLModel, but received type: {type(model)}" | |||
| ) | |||
| raise TypeError(f"Expected an instance of ABLModel, but received type: {type(model)}") | |||
| if not isinstance(reasoner, Reasoner): | |||
| raise TypeError( | |||
| f"Expected an instance of Reasoner, but received type: {type(reasoner)}" | |||
+ 16
- 7
ablkit/bridge/simple_bridge.py
View File
| @@ -49,6 +49,15 @@ class SimpleBridge(BaseBridge): | |||
| ) -> None: | |||
| super().__init__(model, reasoner) | |||
| self.metric_list = metric_list | |||
| if not hasattr(model.base_model, "predict_proba") and reasoner.dist_func in [ | |||
| "confidence", | |||
| "avg_confidence", | |||
| ]: | |||
| raise ValueError( | |||
| "If the base model does not implement the predict_proba method, " | |||
| + "then the dist_func in the reasoner cannot be set to 'confidence'" | |||
| + "or 'avg_confidence', which are related to predicted probability." | |||
| ) | |||
| def predict(self, data_examples: ListData) -> Tuple[List[ndarray], List[ndarray]]: | |||
| """ | |||
| @@ -233,19 +242,19 @@ class SimpleBridge(BaseBridge): | |||
| ``self.metric_list``. If ``val_data`` is None, ``train_data`` will be used to validate | |||
| the model during training time. Defaults to None. | |||
| loops : int | |||
| Machine Learning part and Reasoning part will be iteratively optimized | |||
| for ``loops`` times, by default 50. | |||
| Learning part and Reasoning part will be iteratively optimized | |||
| for ``loops`` times. Defaults to 50. | |||
| segment_size : Union[int, float] | |||
| Data will be split into segments of this size and data in each segment | |||
| will be used together to train the model, by default 1.0. | |||
| will be used together to train the model. Defaults to 1.0. | |||
| eval_interval : int | |||
| The model will be evaluated every ``eval_interval`` loop during training, | |||
| by default 1. | |||
| Defaults to 1. | |||
| save_interval : int, optional | |||
| The model will be saved every ``eval_interval`` loop during training, by | |||
| default None. | |||
| The model will be saved every ``eval_interval`` loop during training. | |||
| Defaults to None. | |||
| save_dir : str, optional | |||
| Directory to save the model, by default None. | |||
| Directory to save the model. Defaults to None. | |||
| """ | |||
| data_examples = self.data_preprocess("train", train_data) | |||
+ 1
- 1
ablkit/data/data_converter.py
View File
| @@ -7,7 +7,7 @@ from lambdaLearn.Base.TabularMixin import TabularMixin | |||
| class DataConverter: | |||
| """ | |||
| This class provides functionality to convert LambdaLearn data to ABL Kit data. | |||
| This class provides functionality to convert LambdaLearn data to ABLkit data. | |||
| """ | |||
| def __init__(self) -> None: | |||
+ 1
- 1
ablkit/data/evaluation/base_metric.py
View File
| @@ -24,7 +24,7 @@ class BaseMetric(metaclass=ABCMeta): | |||
| prefix : str, optional | |||
| The prefix that will be added in the metrics names to disambiguate homonymous | |||
| metrics of different tasks. If prefix is not provided in the argument, | |||
| self.default_prefix will be used instead. Default to None. | |||
| self.default_prefix will be used instead. Defaults to None. | |||
| """ | |||
+ 2
- 2
ablkit/data/evaluation/reasoning_metric.py
View File
| @@ -25,10 +25,10 @@ class ReasoningMetric(BaseMetric): | |||
| ---------- | |||
| kb : KBBase | |||
| An instance of a knowledge base, used for logical reasoning and validation. | |||
| If not provided, reasoning checks are not performed. Default to None. | |||
| If not provided, reasoning checks are not performed. Defaults to None. | |||
| prefix : str, optional | |||
| The prefix that will be added to the metrics names to disambiguate homonymous | |||
| metrics of different tasks. Inherits from BaseMetric. Default to None. | |||
| metrics of different tasks. Inherits from BaseMetric. Defaults to None. | |||
| Notes | |||
| ----- | |||
+ 1
- 1
ablkit/data/evaluation/symbol_accuracy.py
View File
| @@ -21,7 +21,7 @@ class SymbolAccuracy(BaseMetric): | |||
| ---------- | |||
| prefix : str, optional | |||
| The prefix that will be added to the metrics names to disambiguate homonymous | |||
| metrics of different tasks. Inherits from BaseMetric. Default to None. | |||
| metrics of different tasks. Inherits from BaseMetric. Defaults to None. | |||
| """ | |||
| def process(self, data_examples: ListData) -> None: | |||
+ 2
- 2
ablkit/data/structures/list_data.py
View File
| @@ -21,9 +21,9 @@ IndexType = Union[str, slice, int, list, LongTypeTensor, BoolTypeTensor, np.ndar | |||
| class ListData(BaseDataElement): | |||
| """ | |||
| Abstract Data Interface used throughout the ABL Kit. | |||
| Abstract Data Interface used throughout the ABLkit. | |||
| ``ListData`` is the underlying data structure used in the ABL Kit, | |||
| ``ListData`` is the underlying data structure used in the ABLkit, | |||
| designed to manage diverse forms of data dynamically generated throughout the | |||
| Abductive Learning (ABL) framework. This includes handling raw data, predicted | |||
| pseudo-labels, abduced pseudo-labels, pseudo-label indices, etc. | |||
+ 31
- 25
ablkit/learning/basic_nn.py
View File
| @@ -33,30 +33,30 @@ class BasicNN: | |||
| scheduler : Callable[..., Any], optional | |||
| The learning rate scheduler used for training, which will be called | |||
| at the end of each run of the ``fit`` method. It should implement the | |||
| ``step`` method, by default None. | |||
| ``step`` method. Defaults to None. | |||
| device : Union[torch.device, str] | |||
| The device on which the model will be trained or used for prediction, | |||
| by default torch.device("cpu"). | |||
| Defaults to torch.device("cpu"). | |||
| batch_size : int, optional | |||
| The batch size used for training, by default 32. | |||
| The batch size used for training. Defaults to 32. | |||
| num_epochs : int, optional | |||
| The number of epochs used for training, by default 1. | |||
| The number of epochs used for training. Defaults to 1. | |||
| stop_loss : float, optional | |||
| The loss value at which to stop training, by default 0.0001. | |||
| The loss value at which to stop training. Defaults to 0.0001. | |||
| num_workers : int | |||
| The number of workers used for loading data, by default 0. | |||
| The number of workers used for loading data. Defaults to 0. | |||
| save_interval : int, optional | |||
| The model will be saved every ``save_interval`` epoch during training, by default None. | |||
| The model will be saved every ``save_interval`` epoch during training. Defaults to None. | |||
| save_dir : str, optional | |||
| The directory in which to save the model during training, by default None. | |||
| The directory in which to save the model during training. Defaults to None. | |||
| train_transform : Callable[..., Any], optional | |||
| A function/transform that takes an object and returns a transformed version used | |||
| in the ``fit`` and ``train_epoch`` methods, by default None. | |||
| in the ``fit`` and ``train_epoch`` methods. Defaults to None. | |||
| test_transform : Callable[..., Any], optional | |||
| A function/transform that takes an object and returns a transformed version in the | |||
| ``predict``, ``predict_proba`` and ``score`` methods, , by default None. | |||
| ``predict``, ``predict_proba`` and ``score`` methods. Defaults to None. | |||
| collate_fn : Callable[[List[T]], Any], optional | |||
| The function used to collate data, by default None. | |||
| The function used to collate data. Defaults to None. | |||
| """ | |||
| def __init__( | |||
| @@ -184,11 +184,11 @@ class BasicNN: | |||
| Parameters | |||
| ---------- | |||
| data_loader : DataLoader, optional | |||
| The data loader used for training, by default None. | |||
| The data loader used for training. Defaults to None. | |||
| X : List[Any], optional | |||
| The input data, by default None. | |||
| The input data. Defaults to None. | |||
| y : List[int], optional | |||
| The target data, by default None. | |||
| The target data. Defaults to None. | |||
| Returns | |||
| ------- | |||
| @@ -291,9 +291,9 @@ class BasicNN: | |||
| Parameters | |||
| ---------- | |||
| data_loader : DataLoader, optional | |||
| The data loader used for prediction, by default None. | |||
| The data loader used for prediction. Defaults to None. | |||
| X : List[Any], optional | |||
| The input data, by default None. | |||
| The input data. Defaults to None. | |||
| Returns | |||
| ------- | |||
| @@ -333,9 +333,15 @@ class BasicNN: | |||
| Parameters | |||
| ---------- | |||
| data_loader : DataLoader, optional | |||
| The data loader used for prediction, by default None. | |||
| The data loader used for prediction. Defaults to None. | |||
| X : List[Any], optional | |||
| The input data, by default None. | |||
| The input data. Defaults to None. | |||
| Warning | |||
| ------- | |||
| This method calculates the probability by applying a softmax function to the output | |||
| of the neural network. If your neural network already includes a softmax function | |||
| as its final activation, applying softmax again here will lead to incorrect probabilities. | |||
| Returns | |||
| ------- | |||
| @@ -423,11 +429,11 @@ class BasicNN: | |||
| Parameters | |||
| ---------- | |||
| data_loader : DataLoader, optional | |||
| The data loader used for scoring, by default None. | |||
| The data loader used for scoring. Defaults to None. | |||
| X : List[Any], optional | |||
| The input data, by default None. | |||
| The input data. Defaults to None. | |||
| y : List[int], optional | |||
| The target data, by default None. | |||
| The target data. Defaults to None. | |||
| Returns | |||
| ------- | |||
| @@ -466,9 +472,9 @@ class BasicNN: | |||
| X : List[Any] | |||
| Input samples. | |||
| y : List[int], optional | |||
| Target labels. If None, dummy labels are created, by default None. | |||
| Target labels. If None, dummy labels are created. Defaults to None. | |||
| shuffle : bool, optional | |||
| Whether to shuffle the data, by default True. | |||
| Whether to shuffle the data. Defaults to True. | |||
| Returns | |||
| ------- | |||
| @@ -507,7 +513,7 @@ class BasicNN: | |||
| epoch_id : int | |||
| The epoch id. | |||
| save_path : str, optional | |||
| The path to save the model, by default None. | |||
| The path to save the model. Defaults to None. | |||
| """ | |||
| if self.save_dir is None and save_path is None: | |||
| raise ValueError("'save_dir' and 'save_path' should not be None simultaneously.") | |||
| @@ -536,7 +542,7 @@ class BasicNN: | |||
| Parameters | |||
| ---------- | |||
| load_path : str | |||
| The directory to load the model, by default "". | |||
| The directory to load the model. Defaults to "". | |||
| """ | |||
| if load_path is None: | |||
+ 23
- 23
ablkit/learning/model_converter.py
View File
| @@ -9,7 +9,7 @@ from lambdaLearn.Base.DeepModelMixin import DeepModelMixin | |||
| class ModelConverter: | |||
| """ | |||
| This class provides functionality to convert LambdaLearn models to ABL Kit models. | |||
| This class provides functionality to convert LambdaLearn models to ABLkit models. | |||
| """ | |||
| def __init__(self) -> None: | |||
| @@ -50,30 +50,30 @@ class ModelConverter: | |||
| The dict contains necessary parameters to construct a learning rate scheduler used | |||
| for training, which will be called at the end of each run of the ``fit`` method. | |||
| The scheduler class is specified by the ``scheduler`` key. It should implement the | |||
| ``step`` method, by default None. | |||
| ``step`` method. Defaults to None. | |||
| device : torch.device, optional | |||
| The device on which the model will be trained or used for prediction, | |||
| by default torch.device("cpu"). | |||
| Defaults to torch.device("cpu"). | |||
| batch_size : int, optional | |||
| The batch size used for training, by default 32. | |||
| The batch size used for training. Defaults to 32. | |||
| num_epochs : int, optional | |||
| The number of epochs used for training, by default 1. | |||
| The number of epochs used for training. Defaults to 1. | |||
| stop_loss : float, optional | |||
| The loss value at which to stop training, by default 0.0001. | |||
| The loss value at which to stop training. Defaults to 0.0001. | |||
| num_workers : int | |||
| The number of workers used for loading data, by default 0. | |||
| The number of workers used for loading data. Defaults to 0. | |||
| save_interval : int, optional | |||
| The model will be saved every ``save_interval`` epoch during training, by default None. | |||
| The model will be saved every ``save_interval`` epoch during training. Defaults to None. | |||
| save_dir : str, optional | |||
| The directory in which to save the model during training, by default None. | |||
| The directory in which to save the model during training. Defaults to None. | |||
| train_transform : Callable[..., Any], optional | |||
| A function/transform that takes an object and returns a transformed version used | |||
| in the `fit` and `train_epoch` methods, by default None. | |||
| in the `fit` and `train_epoch` methods. Defaults to None. | |||
| test_transform : Callable[..., Any], optional | |||
| A function/transform that takes an object and returns a transformed version in the | |||
| `predict`, `predict_proba` and `score` methods, , by default None. | |||
| `predict`, `predict_proba` and `score` methods. Defaults to None. | |||
| collate_fn : Callable[[List[T]], Any], optional | |||
| The function used to collate data, by default None. | |||
| The function used to collate data. Defaults to None. | |||
| Returns | |||
| ------- | |||
| @@ -140,30 +140,30 @@ class ModelConverter: | |||
| The dict contains necessary parameters to construct a learning rate scheduler used | |||
| for training, which will be called at the end of each run of the ``fit`` method. | |||
| The scheduler class is specified by the ``scheduler`` key. It should implement the | |||
| ``step`` method, by default None. | |||
| ``step`` method. Defaults to None. | |||
| device : torch.device, optional | |||
| The device on which the model will be trained or used for prediction, | |||
| by default torch.device("cpu"). | |||
| Defaults to torch.device("cpu"). | |||
| batch_size : int, optional | |||
| The batch size used for training, by default 32. | |||
| The batch size used for training. Defaults to 32. | |||
| num_epochs : int, optional | |||
| The number of epochs used for training, by default 1. | |||
| The number of epochs used for training. Defaults to 1. | |||
| stop_loss : float, optional | |||
| The loss value at which to stop training, by default 0.0001. | |||
| The loss value at which to stop training. Defaults to 0.0001. | |||
| num_workers : int | |||
| The number of workers used for loading data, by default 0. | |||
| The number of workers used for loading data. Defaults to 0. | |||
| save_interval : int, optional | |||
| The model will be saved every ``save_interval`` epoch during training, by default None. | |||
| The model will be saved every ``save_interval`` epoch during training. Defaults to None. | |||
| save_dir : str, optional | |||
| The directory in which to save the model during training, by default None. | |||
| The directory in which to save the model during training. Defaults to None. | |||
| train_transform : Callable[..., Any], optional | |||
| A function/transform that takes an object and returns a transformed version used | |||
| in the `fit` and `train_epoch` methods, by default None. | |||
| in the `fit` and `train_epoch` methods. Defaults to None. | |||
| test_transform : Callable[..., Any], optional | |||
| A function/transform that takes an object and returns a transformed version in the | |||
| `predict`, `predict_proba` and `score` methods, , by default None. | |||
| `predict`, `predict_proba` and `score` methods. Defaults to None. | |||
| collate_fn : Callable[[List[T]], Any], optional | |||
| The function used to collate data, by default None. | |||
| The function used to collate data. Defaults to None. | |||
| Returns | |||
| ------- | |||
+ 8
- 6
ablkit/reasoning/reasoner.py
View File
| @@ -30,12 +30,14 @@ class Reasoner: | |||
| measure, wherein the candidate with lowest cost is selected as the final | |||
| abduced label. It can be either a string representing a predefined distance | |||
| function or a callable function. The available predefined distance functions: | |||
| 'hamming' | 'confidence'. 'hamming': directly calculates the Hamming | |||
| distance between the predicted pseudo-label in the data example and each | |||
| candidate, 'confidence': calculates the distance between the prediction | |||
| and each candidate based on confidence derived from the predicted probability | |||
| in the data example. The callable function should have the signature | |||
| dist_func(data_example, candidates, candidate_idxs, reasoning_results) and must | |||
| 'hamming' | 'confidence' | 'avg_confidence'. 'hamming' directly calculates the | |||
| Hamming distance between the predicted pseudo-label in the data example and each | |||
| candidate. 'confidence' and 'avg_confidence' calculates the confidence distance | |||
| between the predicted probabilities in the data example and each candidate, where | |||
| the confidence distance is defined as 1 - the product of prediction probabilities | |||
| in 'confidence' and 1 - the average of prediction probabilities in 'avg_confidence'. | |||
| Alternatively, the callable function should have the signature | |||
| ``dist_func(data_example, candidates, candidate_idxs, reasoning_results)`` and must | |||
| return a cost list. Each element in this cost list should be a numerical value | |||
| representing the cost for each candidate, and the list should have the same length | |||
| as candidates. Defaults to 'confidence'. | |||
+ 1
- 1
ablkit/utils/logger.py
View File
| @@ -26,7 +26,7 @@ class FilterDuplicateWarning(logging.Filter): | |||
| Parameters | |||
| ---------- | |||
| name : str, optional | |||
| The name of the filter, by default "abl". | |||
| The name of the filter. Defaults to "abl". | |||
| """ | |||
| def __init__(self, name: Optional[str] = "abl"): | |||
+ 1
- 1
ablkit/utils/utils.py
View File
| @@ -193,7 +193,7 @@ def tab_data_to_tuple( | |||
| y : Union[List[Any], Any] | |||
| The label. | |||
| reasoning_result : Any, optional | |||
| The reasoning result, by default 0. | |||
| The reasoning result. Defaults to 0. | |||
| Returns | |||
| ------- | |||
+ 1
- 1
docs/Examples/HED.rst
View File
| @@ -3,7 +3,7 @@ Handwritten Equation Decipherment (HED) | |||
| .. raw:: html | |||
| <p>For detailed code implementation, please view it on <a class="reference external" href="https://github.com/AbductiveLearning/ABLKit/tree/main/examples/hed" target="_blank">GitHub</a>.</p> | |||
| <p>For detailed code implementation, please view it on <a class="reference external" href="https://github.com/AbductiveLearning/ABLkit/tree/main/examples/hed" target="_blank">GitHub</a>.</p> | |||
| Below shows an implementation of `Handwritten Equation | |||
| Decipherment <https://proceedings.neurips.cc/paper_files/paper/2019/file/9c19a2aa1d84e04b0bd4bc888792bd1e-Paper.pdf>`__. | |||
+ 2
- 2
docs/Examples/HWF.rst
View File
| @@ -3,7 +3,7 @@ Handwritten Formula (HWF) | |||
| .. raw:: html | |||
| <p>For detailed code implementation, please view it on <a class="reference external" href="https://github.com/AbductiveLearning/ABLKit/tree/main/examples/hwf" target="_blank">GitHub</a>.</p> | |||
| <p>For detailed code implementation, please view it on <a class="reference external" href="https://github.com/AbductiveLearning/ABLkit/tree/main/examples/hwf" target="_blank">GitHub</a>.</p> | |||
| Below shows an implementation of `Handwritten | |||
| Formula <https://arxiv.org/abs/2006.06649>`__. In this | |||
| @@ -234,7 +234,7 @@ examples. | |||
| .. code:: python | |||
| from ablkit.data.structures import ListData | |||
| # ListData is a data structure provided by ABL Kit that can be used to organize data examples | |||
| # ListData is a data structure provided by ABLkit that can be used to organize data examples | |||
| data_examples = ListData() | |||
| # We use the first 1001st and 3001st data examples in the training set as an illustration | |||
| data_examples.X = [X_1000, X_3000] | |||
+ 2
- 2
docs/Examples/MNISTAdd.rst
View File
| @@ -3,7 +3,7 @@ MNIST Addition | |||
| .. raw:: html | |||
| <p>For detailed code implementation, please view it on <a class="reference external" href="https://github.com/AbductiveLearning/ABLKit/tree/main/examples/mnist_add" target="_blank">GitHub</a>.</p> | |||
| <p>For detailed code implementation, please view it on <a class="reference external" href="https://github.com/AbductiveLearning/ABLkit/tree/main/examples/mnist_add" target="_blank">GitHub</a>.</p> | |||
| Below shows an implementation of `MNIST | |||
| Addition <https://arxiv.org/abs/1805.10872>`__. In this task, pairs of | |||
| @@ -203,7 +203,7 @@ examples. | |||
| .. code:: python | |||
| from ablkit.data.structures import ListData | |||
| # ListData is a data structure provided by ABL Kit that can be used to organize data examples | |||
| # ListData is a data structure provided by ABLkit that can be used to organize data examples | |||
| data_examples = ListData() | |||
| # We use the first 100 data examples in the training set as an illustration | |||
| data_examples.X = train_X[:100] | |||
+ 2
- 2
docs/Examples/Zoo.rst
View File
| @@ -3,7 +3,7 @@ Zoo | |||
| .. raw:: html | |||
| <p>For detailed code implementation, please view it on <a class="reference external" href="https://github.com/AbductiveLearning/ABLKit/tree/main/examples/zoo" target="_blank">GitHub</a>.</p> | |||
| <p>For detailed code implementation, please view it on <a class="reference external" href="https://github.com/AbductiveLearning/ABLkit/tree/main/examples/zoo" target="_blank">GitHub</a>.</p> | |||
| Below shows an implementation of | |||
| `Zoo <https://archive.ics.uci.edu/dataset/111/zoo>`__ dataset. In this task, | |||
| @@ -84,7 +84,7 @@ Out: | |||
| Next, we transform the tabular data to the format required by | |||
| ABL Kit, which is a tuple of (X, gt_pseudo_label, Y). In this task, | |||
| ABLkit, which is a tuple of (X, gt_pseudo_label, Y). In this task, | |||
| we treat the attributes as X and the targets as gt_pseudo_label (ground | |||
| truth pseudo-labels). Y (reasoning results) are expected to be 0, | |||
| indicating no rules are violated. | |||
+ 6
- 6
docs/Intro/Basics.rst
View File
| @@ -9,16 +9,16 @@ | |||
| Learn the Basics | |||
| ================ | |||
| Modules in ABL Kit | |||
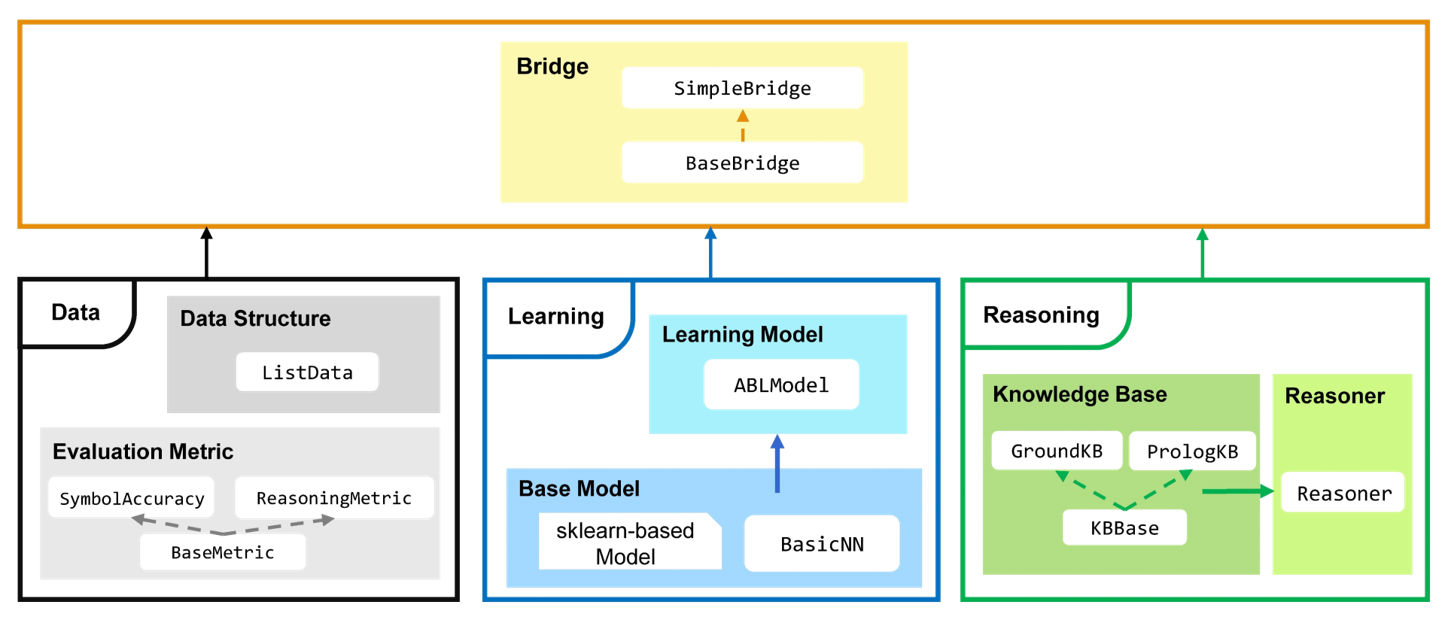
| Modules in ABLkit | |||
| ---------------------- | |||
| ABL Kit is an efficient toolkit for `Abductive Learning <../Overview/Abductive-Learning.html>`_ (ABL), | |||
| ABLkit is an efficient toolkit for `Abductive Learning <../Overview/Abductive-Learning.html>`_ (ABL), | |||
| a paradigm which integrates machine learning and logical reasoning in a balanced-loop. | |||
| ABL Kit comprises three primary parts: **Data**, **Learning**, and | |||
| ABLkit comprises three primary parts: **Data**, **Learning**, and | |||
| **Reasoning**, corresponding to the three pivotal components of current | |||
| AI: data, models, and knowledge. Below is an overview of the ABL Kit. | |||
| AI: data, models, and knowledge. Below is an overview of the ABLkit. | |||
| .. image:: ../_static/img/ABLKit.png | |||
| .. image:: ../_static/img/ABLkit.png | |||
| **Data** part manages the storage, operation, and evaluation of data efficiently. | |||
| It includes the ``ListData`` class, which defines the data structures used in | |||
| @@ -50,7 +50,7 @@ from the ``BaseBridge`` class). The Bridge part synthesizes data, | |||
| learning, and reasoning, facilitating the training and testing | |||
| of the entire ABL framework. | |||
| Use ABL Kit Step by Step | |||
| Use ABLkit Step by Step | |||
| ---------------------------- | |||
| In a typical ABL process, as illustrated below, | |||
+ 3
- 4
docs/Intro/Bridge.rst
View File
| @@ -10,7 +10,7 @@ | |||
| Bridge | |||
| ====== | |||
| In this section, we will look at how to bridge learning and reasoning parts to train the model, which is the fundamental idea of Abductive Learning. ABL Kit implements a set of bridge classes to achieve this. | |||
| In this section, we will look at how to bridge learning and reasoning parts to train the model, which is the fundamental idea of Abductive Learning. ABLkit implements a set of bridge classes to achieve this. | |||
| .. code:: python | |||
| @@ -42,7 +42,7 @@ In this section, we will look at how to bridge learning and reasoning parts to t | |||
| | ``test(test_data)`` | Test the model. | | |||
| +---------------------------------------+----------------------------------------------------+ | |||
| where ``train_data`` and ``test_data`` are both in the form of a tuple or a `ListData <../API/ablkit.data.html#structures.ListData>`_. Regardless of the form, they all need to include three components: ``X``, ``gt_pseudo_label`` and ``Y``. Since ``ListData`` is the underlying data structure used throughout the ABL Kit, tuple-formed data will be firstly transformed into ``ListData`` in the ``train`` and ``test`` methods, and such ``ListData`` instances are referred to as ``data_examples``. More details can be found in `preparing datasets <Datasets.html>`_. | |||
| where ``train_data`` and ``test_data`` are both in the form of a tuple or a `ListData <../API/ablkit.data.html#structures.ListData>`_. Regardless of the form, they all need to include three components: ``X``, ``gt_pseudo_label`` and ``Y``. Since ``ListData`` is the underlying data structure used throughout the ABLkit, tuple-formed data will be firstly transformed into ``ListData`` in the ``train`` and ``test`` methods, and such ``ListData`` instances are referred to as ``data_examples``. More details can be found in `preparing datasets <Datasets.html>`_. | |||
| ``SimpleBridge`` inherits from ``BaseBridge`` and provides a basic implementation. Besides the ``model`` and ``reasoner``, ``SimpleBridge`` has an extra initialization argument, ``metric_list``, which will be used to evaluate model performance. Its training process involves several Abductive Learning loops and each loop consists of the following five steps: | |||
| @@ -68,8 +68,7 @@ The fundamental part of the ``train`` method is as follows: | |||
| to train. ``gt_pseudo_label`` can be ``None``. | |||
| - ``Y`` is a list representing the ground truth reasoning result for each sublist in ``X``. | |||
| loops : int | |||
| Machine Learning part and Reasoning part will be iteratively optimized | |||
| for ``loops`` times. | |||
| Learning part and Reasoning part will be iteratively optimized for ``loops`` times. | |||
| segment_size : Union[int, float] | |||
| Data will be split into segments of this size and data in each segment | |||
| will be used together to train the model. | |||
+ 5
- 5
docs/Intro/Datasets.rst
View File
| @@ -10,7 +10,7 @@ | |||
| Dataset & Data Structure | |||
| ======================== | |||
| In this section, we will look at the dataset and data structure in ABL Kit. | |||
| In this section, we will look at the dataset and data structure in ABLkit. | |||
| .. code:: python | |||
| @@ -20,7 +20,7 @@ In this section, we will look at the dataset and data structure in ABL Kit. | |||
| Dataset | |||
| ------- | |||
| ABL Kit requires user data to be either structured as a tuple ``(X, gt_pseudo_label, Y)`` or a ``ListData`` (the underlying data structure utilized in ABL Kit, cf. the next section) object with ``X``, ``gt_pseudo_label`` and ``Y`` attributes. Regardless of the chosen format, the data should encompass three essential components: | |||
| ABLkit requires user data to be either structured as a tuple ``(X, gt_pseudo_label, Y)`` or a ``ListData`` (the underlying data structure utilized in ABLkit, cf. the next section) object with ``X``, ``gt_pseudo_label`` and ``Y`` attributes. Regardless of the chosen format, the data should encompass three essential components: | |||
| - ``X``: List[List[Any]] | |||
| @@ -62,11 +62,11 @@ where each sublist in ``X``, e.g., |data_example|, is a data example and each im | |||
| Data Structure | |||
| -------------- | |||
| Besides the user-provided dataset, various forms of data are utilized and dynamicly generated throughout the training and testing process of ABL framework. Examples include raw data, predicted pseudo-label, abduced pseudo-label, pseudo-label indices, etc. To manage this diversity and ensure a stable, versatile interface, ABL Kit employs `abstract data interfaces <../API/ablkit.data.html#structures>`_ to encapsulate different forms of data that will be used in the total learning process. | |||
| Besides the user-provided dataset, various forms of data are utilized and dynamicly generated throughout the training and testing process of ABL framework. Examples include raw data, predicted pseudo-label, abduced pseudo-label, pseudo-label indices, etc. To manage this diversity and ensure a stable, versatile interface, ABLkit employs `abstract data interfaces <../API/ablkit.data.html#structures>`_ to encapsulate different forms of data that will be used in the total learning process. | |||
| ``ListData`` is the underlying abstract data interface utilized in ABL Kit. As the fundamental data structure, ``ListData`` implements commonly used data manipulation methods and is responsible for transferring data between various components of ABL, ensuring that stages such as prediction, abductive reasoning, and training can utilize ``ListData`` as a unified input format. Before proceeding to other stages, user-provided datasets will be firstly converted into ``ListData``. | |||
| ``ListData`` is the underlying abstract data interface utilized in ABLkit. As the fundamental data structure, ``ListData`` implements commonly used data manipulation methods and is responsible for transferring data between various components of ABL, ensuring that stages such as prediction, abductive reasoning, and training can utilize ``ListData`` as a unified input format. Before proceeding to other stages, user-provided datasets will be firstly converted into ``ListData``. | |||
| Besides providing a tuple of ``(X, gt_pseudo_label, Y)``, ABL Kit also allows users to directly supply data in ``ListData`` format, which similarly requires the inclusion of these three attributes. The following code shows the basic usage of ``ListData``. More information can be found in the `API documentation <../API/ablkit.data.html#structures>`_. | |||
| Besides providing a tuple of ``(X, gt_pseudo_label, Y)``, ABLkit also allows users to directly supply data in ``ListData`` format, which similarly requires the inclusion of these three attributes. The following code shows the basic usage of ``ListData``. More information can be found in the `API documentation <../API/ablkit.data.html#structures>`_. | |||
| .. code-block:: python | |||
+ 1
- 1
docs/Intro/Evaluation.rst
View File
| @@ -16,7 +16,7 @@ In this section, we will look at how to build evaluation metrics. | |||
| from ablkit.data.evaluation import BaseMetric, SymbolAccuracy, ReasoningMetric | |||
| ABL Kit seperates the evaluation process from model training and testing as an independent class, ``BaseMetric``. The training and testing processes are implemented in the ``BaseBridge`` class, so metrics are used by this class and its sub-classes. After building a ``bridge`` with a list of ``BaseMetric`` instances, these metrics will be used by the ``bridge.valid`` method to evaluate the model performance during training and testing. | |||
| ABLkit seperates the evaluation process from model training and testing as an independent class, ``BaseMetric``. The training and testing processes are implemented in the ``BaseBridge`` class, so metrics are used by this class and its sub-classes. After building a ``bridge`` with a list of ``BaseMetric`` instances, these metrics will be used by the ``bridge.valid`` method to evaluate the model performance during training and testing. | |||
| To customize our own metrics, we need to inherit from ``BaseMetric`` and implement the ``process`` and ``compute_metrics`` methods. | |||
+ 2
- 2
docs/Intro/Learning.rst
View File
| @@ -12,7 +12,7 @@ Learning Part | |||
| In this section, we will look at how to build the learning part. | |||
| In ABL Kit, building the learning part involves two steps: | |||
| In ABLkit, building the learning part involves two steps: | |||
| 1. Build a machine learning base model used to make predictions on instance-level data. | |||
| 2. Instantiate an ``ABLModel`` with the base model, which enables the learning part to process example-level data. | |||
| @@ -76,7 +76,7 @@ Besides the necessary methods required to instantiate an ``ABLModel``, i.e., ``f | |||
| Instantiating an ABLModel | |||
| ------------------------- | |||
| Typically, base model is trained to make predictions on instance-level data, and can not directly process example-level data, which is not suitable for most neural-symbolic tasks. ABL Kit provides the ``ABLModel`` to solve this problem. This class serves as a unified wrapper for all base models, which enables the learning part to train, test, and predict on example-level data. | |||
| Typically, base model is trained to make predictions on instance-level data, and can not directly process example-level data, which is not suitable for most neural-symbolic tasks. ABLkit provides the ``ABLModel`` to solve this problem. This class serves as a unified wrapper for all base models, which enables the learning part to train, test, and predict on example-level data. | |||
| Generally, we can simply instantiate an ``ABLModel`` by: | |||
+ 4
- 4
docs/Intro/Quick-Start.rst
View File
| @@ -14,7 +14,7 @@ We use the MNIST Addition task as a quick start example. In this task, pairs of | |||
| Working with Data | |||
| ----------------- | |||
| ABL Kit requires data in the format of ``(X, gt_pseudo_label, Y)`` where ``X`` is a list of input examples containing instances, | |||
| ABLkit requires data in the format of ``(X, gt_pseudo_label, Y)`` where ``X`` is a list of input examples containing instances, | |||
| ``gt_pseudo_label`` is the ground-truth label of each example in ``X`` and ``Y`` is the ground-truth reasoning result of each example in ``X``. Note that ``gt_pseudo_label`` is only used to evaluate the machine learning model's performance but not to train it. | |||
| In the MNIST Addition task, the data loading looks like | |||
| @@ -33,7 +33,7 @@ Read more about `preparing datasets <Datasets.html>`_. | |||
| Building the Learning Part | |||
| -------------------------- | |||
| Learning part is constructed by first defining a base model for machine learning. ABL Kit offers considerable flexibility, supporting any base model that conforms to the scikit-learn style (which requires the implementation of ``fit`` and ``predict`` methods), or a PyTorch-based neural network (which has defined the architecture and implemented ``forward`` method). | |||
| Learning part is constructed by first defining a base model for machine learning. ABLkit offers considerable flexibility, supporting any base model that conforms to the scikit-learn style (which requires the implementation of ``fit`` and ``predict`` methods), or a PyTorch-based neural network (which has defined the architecture and implemented ``forward`` method). | |||
| In this example, we build a simple LeNet5 network as the base model. | |||
| .. code:: python | |||
| @@ -43,7 +43,7 @@ In this example, we build a simple LeNet5 network as the base model. | |||
| cls = LeNet5(num_classes=10) | |||
| To facilitate uniform processing, ABL Kit provides the ``BasicNN`` class to convert a PyTorch-based neural network into a format compatible with scikit-learn models. To construct a ``BasicNN`` instance, aside from the network itself, we also need to define a loss function, an optimizer, and the computing device. | |||
| To facilitate uniform processing, ABLkit provides the ``BasicNN`` class to convert a PyTorch-based neural network into a format compatible with scikit-learn models. To construct a ``BasicNN`` instance, aside from the network itself, we also need to define a loss function, an optimizer, and the computing device. | |||
| .. code:: python | |||
| @@ -98,7 +98,7 @@ Read more about `building the reasoning part <Reasoning.html>`_. | |||
| Building Evaluation Metrics | |||
| --------------------------- | |||
| ABL Kit provides two basic metrics, namely ``SymbolAccuracy`` and ``ReasoningMetric``, which are used to evaluate the accuracy of the machine learning model's predictions and the accuracy of the ``logic_forward`` results, respectively. | |||
| ABLkit provides two basic metrics, namely ``SymbolAccuracy`` and ``ReasoningMetric``, which are used to evaluate the accuracy of the machine learning model's predictions and the accuracy of the ``logic_forward`` results, respectively. | |||
| .. code:: python | |||
+ 12
- 10
docs/Intro/Reasoning.rst
View File
| @@ -12,7 +12,7 @@ Reasoning part | |||
| In this section, we will look at how to build the reasoning part, which | |||
| leverages domain knowledge and performs deductive or abductive reasoning. | |||
| In ABL Kit, building the reasoning part involves two steps: | |||
| In ABLkit, building the reasoning part involves two steps: | |||
| 1. Build a knowledge base by creating a subclass of ``KBBase``, which | |||
| specifies how to process pseudo-label of an example to the reasoning result. | |||
| @@ -28,7 +28,7 @@ Building a knowledge base | |||
| ------------------------- | |||
| Generally, we can create a subclass derived from ``KBBase`` to build our own | |||
| knowledge base. In addition, ABL Kit also offers several predefined | |||
| knowledge base. In addition, ABLkit also offers several predefined | |||
| subclasses of ``KBBase`` (e.g., ``PrologKB`` and ``GroundKB``), | |||
| which we can utilize to build our knowledge base more conveniently. | |||
| @@ -316,12 +316,14 @@ specify: | |||
| accelerate consistency minimization. Defaults to False. | |||
| - ``dist_func`` (str, optional), specifying the distance function to be | |||
| used when determining consistency between your prediction and | |||
| candidate returned from knowledge base. Valid options include | |||
| “confidence” (default) and “hamming”. For “confidence”, it calculates | |||
| the distance between the prediction and candidate based on confidence | |||
| derived from the predicted probability in the data example. For | |||
| “hamming”, it directly calculates the Hamming distance between the | |||
| predicted pseudo-label in the data example and candidate. | |||
| candidate returned from knowledge base. This can be either a user-defined function | |||
| or one that is predefined. Valid predefined options include | |||
| “hamming”, “confidence” and “avg_confidence”. For “hamming”, it directly calculates the Hamming distance between the | |||
| predicted pseudo-label in the data example and candidate. For “confidence”, it | |||
| calculates the confidence distance between the predicted probabilities in the data | |||
| example and each candidate, where the confidence distance is defined as 1 - the product | |||
| of prediction probabilities in “confidence” and 1 - the average of prediction probabilities in “avg_confidence”. | |||
| Defaults to “confidence”. | |||
| - ``idx_to_label`` (dict, optional), a mapping from index in the base model to label. | |||
| If not provided, a default order-based index to label mapping is created. | |||
| Defaults to None. | |||
| @@ -357,7 +359,7 @@ As an example, consider these data examples for MNIST Addition: | |||
| The compatible candidates after abductive reasoning for both examples | |||
| would be ``[[1,7], [7,1]]``. However, when the reasoner calls ``abduce`` | |||
| to select only one candidate based on the ``confidence`` distance function, | |||
| to select only one candidate based on the “confidence” distance function, | |||
| the output would differ for each example: | |||
| .. code:: python | |||
| @@ -373,7 +375,7 @@ Out: | |||
| The outputs for example1 and example2 are [1,7] and [7,1], respectively. | |||
| Specifically, as mentioned before, ``confidence`` calculates the distance between the data | |||
| Specifically, as mentioned before, “confidence” calculates the distance between the data | |||
| example and candidates based on the confidence derived from the predicted probability. | |||
| Take ``example1`` as an example, the ``pred_prob`` in it indicates a higher | |||
| confidence that the first label should be "1" rather than "7". Therefore, among the | |||
+ 1
- 1
docs/Makefile
View File
| @@ -4,7 +4,7 @@ | |||
| # You can set these variables from the command line. | |||
| SPHINXOPTS = | |||
| SPHINXBUILD = sphinx-build | |||
| SPHINXPROJ = ABL Kit | |||
| SPHINXPROJ = ABLkit | |||
| SOURCEDIR = . | |||
| BUILDDIR = build | |||
+ 3
- 3
docs/Overview/Installation.rst
View File
| @@ -4,7 +4,7 @@ Installation | |||
| Install from PyPI | |||
| ^^^^^^^^^^^^^^^^^ | |||
| The easiest way to install ABL Kit is using ``pip``: | |||
| The easiest way to install ABLkit is using ``pip``: | |||
| .. code:: bash | |||
| @@ -18,8 +18,8 @@ sequentially run following commands in your terminal/command line. | |||
| .. code:: bash | |||
| git clone https://github.com/AbductiveLearning/ABLKit.git | |||
| cd ABLKit | |||
| git clone https://github.com/AbductiveLearning/ABLkit.git | |||
| cd ABLkit | |||
| pip install -v -e . | |||
| (Optional) Install SWI-Prolog | |||
+ 0
- 87
docs/README.rst
View File
| @@ -1,87 +0,0 @@ | |||
| ABL Kit | |||
| ======= | |||
| **ABL Kit** is an efficient Python toolkit for **Abductive Learning (ABL)**. | |||
| ABL is a novel paradigm that integrates machine learning and | |||
| logical reasoning in a unified framework. It is suitable for tasks | |||
| where both data and (logical) domain knowledge are available. | |||
| .. image:: _static/img/ABL.png | |||
| Key Features of ABL Kit: | |||
| - **Great Flexibility**: Adaptable to various machine learning modules and logical reasoning components. | |||
| - **User-Friendly**: Provide **data**, :blue-bold:`model`, and :green-bold:`KB`, and get started with just a few lines of code. | |||
| - **High-Performance**: Optimization for high accuracy and fast training speed. | |||
| ABL Kit encapsulates advanced ABL techniques, providing users with | |||
| an efficient and convenient toolkit to develop dual-driven ABL systems, | |||
| which leverage the power of both data and knowledge. | |||
| .. image:: _static/img/ABLKit.png | |||
| Installation | |||
| ------------ | |||
| Install from PyPI | |||
| ^^^^^^^^^^^^^^^^^ | |||
| The easiest way to install ABL Kit is using ``pip``: | |||
| .. code:: bash | |||
| pip install ablkit | |||
| Install from Source | |||
| ^^^^^^^^^^^^^^^^^^^ | |||
| Alternatively, to install from source code, | |||
| sequentially run following commands in your terminal/command line. | |||
| .. code:: bash | |||
| git clone https://github.com/AbductiveLearning/ABLKit.git | |||
| cd ABLKit | |||
| pip install -v -e . | |||
| (Optional) Install SWI-Prolog | |||
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ | |||
| If the use of a :ref:`Prolog-based knowledge base <prolog>` is necessary, the installation of `SWI-Prolog <https://www.swi-prolog.org/>`_ is also required: | |||
| For Linux users: | |||
| .. code:: bash | |||
| sudo apt-get install swi-prolog | |||
| For Windows and Mac users, please refer to the `SWI-Prolog Install Guide <https://github.com/yuce/pyswip/blob/master/INSTALL.md>`_. | |||
| References | |||
| ---------- | |||
| For more information about ABL, please refer to: `Zhou, 2019 <http://scis.scichina.com/en/2019/076101.pdf>`_ | |||
| and `Zhou and Huang, 2022 <https://www.lamda.nju.edu.cn/publication/chap_ABL.pdf>`_. | |||
| .. code-block:: latex | |||
| @article{zhou2019abductive, | |||
| title = {Abductive learning: towards bridging machine learning and logical reasoning}, | |||
| author = {Zhou, Zhi-Hua}, | |||
| journal = {Science China Information Sciences}, | |||
| volume = {62}, | |||
| number = {7}, | |||
| pages = {76101}, | |||
| year = {2019} | |||
| } | |||
| @incollection{zhou2022abductive, | |||
| title = {Abductive Learning}, | |||
| author = {Zhou, Zhi-Hua and Huang, Yu-Xuan}, | |||
| booktitle = {Neuro-Symbolic Artificial Intelligence: The State of the Art}, | |||
| editor = {Pascal Hitzler and Md. Kamruzzaman Sarker}, | |||
| publisher = {{IOS} Press}, | |||
| pages = {353--369}, | |||
| address = {Amsterdam}, | |||
| year = {2022} | |||
| } | |||
BIN
docs/_static/img/ABLKit.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 1445 | Height: 623 | Size: 181 kB |
BIN
docs/_static/img/ABLkit.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 1453 | Height: 614 | Size: 212 kB |
BIN
docs/_static/img/logo.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
|
| Width: 801 | Height: 773 | Size: 172 kB |
+ 1
- 1
docs/conf.py
View File
| @@ -14,7 +14,7 @@ import ablkit # noqa: E402,F401 | |||
| # -- Project information ----------------------------------------------------- | |||
| project = "ABL Kit" | |||
| project = "ABLkit" | |||
| copyright = "LAMDA, 2024" | |||
| # -- General configuration --------------------------------------------------- | |||
+ 94
- 2
docs/index.rst
View File
| @@ -1,4 +1,96 @@ | |||
| .. include:: README.rst | |||
| ABLkit | |||
| ====== | |||
| .. raw:: html | |||
| <img alt="logo" class="align-right" src="_static/img/logo.png" style="width: 140px; height: 135.1px; margin-left: 20px; margin-right: 10px"> | |||
| <p> | |||
| <b>ABLkit</b> is an efficient Python toolkit for <a href="https://www.lamda.nju.edu.cn/publication/chap_ABL.pdf"><b>Abductive Learning (ABL)</b></a>. | |||
| </p> | |||
| ABL is a novel paradigm that integrates machine learning and | |||
| logical reasoning in a unified framework. It is suitable for tasks | |||
| where both data and (logical) domain knowledge are available. | |||
| .. image:: _static/img/ABL.png | |||
| Key Features of ABLkit: | |||
| - **Great Flexibility**: Adaptable to various machine learning modules and logical reasoning components. | |||
| - **User-Friendly**: Provide **data**, :blue-bold:`model`, and :green-bold:`KB`, and get started with just a few lines of code. | |||
| - **High-Performance**: Optimization for high accuracy and fast training speed. | |||
| ABLkit encapsulates advanced ABL techniques, providing users with | |||
| an efficient and convenient toolkit to develop dual-driven ABL systems, | |||
| which leverage the power of both data and knowledge. | |||
| .. image:: _static/img/ABLkit.png | |||
| Installation | |||
| ------------ | |||
| Install from PyPI | |||
| ^^^^^^^^^^^^^^^^^ | |||
| The easiest way to install ABLkit is using ``pip``: | |||
| .. code:: bash | |||
| pip install ablkit | |||
| Install from Source | |||
| ^^^^^^^^^^^^^^^^^^^ | |||
| Alternatively, to install from source code, | |||
| sequentially run following commands in your terminal/command line. | |||
| .. code:: bash | |||
| git clone https://github.com/AbductiveLearning/ABLkit.git | |||
| cd ABLkit | |||
| pip install -v -e . | |||
| (Optional) Install SWI-Prolog | |||
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ | |||
| If the use of a :ref:`Prolog-based knowledge base <prolog>` is necessary, the installation of `SWI-Prolog <https://www.swi-prolog.org/>`_ is also required: | |||
| For Linux users: | |||
| .. code:: bash | |||
| sudo apt-get install swi-prolog | |||
| For Windows and Mac users, please refer to the `SWI-Prolog Install Guide <https://github.com/yuce/pyswip/blob/master/INSTALL.md>`_. | |||
| References | |||
| ---------- | |||
| For more information about ABL, please refer to: `Zhou, 2019 <http://scis.scichina.com/en/2019/076101.pdf>`_ | |||
| and `Zhou and Huang, 2022 <https://www.lamda.nju.edu.cn/publication/chap_ABL.pdf>`_. | |||
| .. code-block:: latex | |||
| @article{zhou2019abductive, | |||
| title = {Abductive learning: towards bridging machine learning and logical reasoning}, | |||
| author = {Zhou, Zhi-Hua}, | |||
| journal = {Science China Information Sciences}, | |||
| volume = {62}, | |||
| number = {7}, | |||
| pages = {76101}, | |||
| year = {2019} | |||
| } | |||
| @incollection{zhou2022abductive, | |||
| title = {Abductive Learning}, | |||
| author = {Zhou, Zhi-Hua and Huang, Yu-Xuan}, | |||
| booktitle = {Neuro-Symbolic Artificial Intelligence: The State of the Art}, | |||
| editor = {Pascal Hitzler and Md. Kamruzzaman Sarker}, | |||
| publisher = {{IOS} Press}, | |||
| pages = {353--369}, | |||
| address = {Amsterdam}, | |||
| year = {2022} | |||
| } | |||
| .. toctree:: | |||
| :maxdepth: 1 | |||
| @@ -9,7 +101,7 @@ | |||
| .. toctree:: | |||
| :maxdepth: 1 | |||
| :caption: Introduction to ABL Kit | |||
| :caption: Introduction to ABLkit | |||
| Intro/Basics | |||
| Intro/Quick-Start | |||
+ 1
- 1
examples/hwf/hwf.ipynb
View File
| @@ -237,7 +237,7 @@ | |||
| "source": [ | |||
| "from ablkit.data.structures import ListData\n", | |||
| "\n", | |||
| "# ListData is a data structure provided by ABL Kit that can be used to organize data examples\n", | |||
| "# ListData is a data structure provided by ABLkit that can be used to organize data examples\n", | |||
| "data_examples = ListData()\n", | |||
| "# We use the first 1001st and 3001st data examples in the training set as an illustration\n", | |||
| "data_examples.X = [X_1000, X_3000]\n", | |||
+ 2
- 2
examples/mnist_add/mnist_add.ipynb
View File
| @@ -282,7 +282,7 @@ | |||
| "source": [ | |||
| "from ablkit.data.structures import ListData\n", | |||
| "\n", | |||
| "# ListData is a data structure provided by ABL Kit that can be used to organize data examples\n", | |||
| "# ListData is a data structure provided by ABLkit that can be used to organize data examples\n", | |||
| "data_examples = ListData()\n", | |||
| "# We use the first 100 data examples in the training set as an illustration\n", | |||
| "data_examples.X = train_X[:100]\n", | |||
| @@ -504,7 +504,7 @@ | |||
| "name": "python", | |||
| "nbconvert_exporter": "python", | |||
| "pygments_lexer": "ipython3", | |||
| "version": "3.8.18" | |||
| "version": "3.8.13" | |||
| }, | |||
| "orig_nbformat": 4, | |||
| "vscode": { | |||
+ 1
- 1
examples/zoo/zoo.ipynb
View File
| @@ -97,7 +97,7 @@ | |||
| "cell_type": "markdown", | |||
| "metadata": {}, | |||
| "source": [ | |||
| "Next, we transform the tabular data to the format required by ABL Kit, which is a tuple of (X, gt_pseudo_label, Y). In this task, we treat the attributes as X and the targets as gt_pseudo_label (ground truth pseudo-labels). Y (reasoning results) are expected to be 0, indicating no rules are violated." | |||
| "Next, we transform the tabular data to the format required by ABLkit, which is a tuple of (X, gt_pseudo_label, Y). In this task, we treat the attributes as X and the targets as gt_pseudo_label (ground truth pseudo-labels). Y (reasoning results) are expected to be 0, indicating no rules are violated." | |||
| ] | |||
| }, | |||
| { | |||
+ 3
- 3
pyproject.toml
View File
| @@ -4,7 +4,7 @@ build-backend = "setuptools.build_meta" | |||
| [project] | |||
| name = "ablkit" | |||
| version = "0.1.8" | |||
| version = "0.2.0" | |||
| authors = [ | |||
| { name="LAMDA 2024", email = "abductivelearning@gmail.com" }, | |||
| ] | |||
| @@ -40,8 +40,8 @@ dependencies = [ | |||
| ] | |||
| [project.urls] | |||
| Homepage = "https://github.com/AbductiveLearning/ABLKit" | |||
| Issues = "https://github.com/AbductiveLearning/ABLKit/issues" | |||
| Homepage = "https://github.com/AbductiveLearning/ABLkit" | |||
| Issues = "https://github.com/AbductiveLearning/ABLkit/issues" | |||
| [project.optional-dependencies] | |||
| test = [ | |||